前言
只读了前半部分就感慨文章结构真的好清晰,从Introduction到related work完完全全都在体现它的motivation——他做了一件什么事情?以及为什么要这么做?解决了什么问题。
第一遍阅读
keywords: 以RGBD作为输入 使用点云表示场景的 dense SLAM
Introduction
- 传统方法对Mapping和Tracking使用不同的表达——造成 data redundancy & independece
- 引出基于Nerf的方法只使用一种场景表示for both T&M
- 对于dense learning-based mapping有以下几种表示方式:voxel grids, voxel hashing octrees point/surfel clouds. 但是缺点有:需要GT depth 且 在测试阶段无法预测看不到的场景(??)。
- 引出基于Nerf的方法的优势:improved noise, outlier handling, better hole filling and inpainting capabilities for unobserved scene parts, and data compression.
所以引出问题:Can point-based neural scene representations be used for tracking and mapping for real-time capable SLAM?
提出的新的场景表示能否也满足上述两种优势。此处介绍了point-based相比与其他表示方法的区别和优势,引出贡献:
1.实时的 desen SLAM使用point-based的表示方式for both T&M。
2. dynamic point density strategy保证时间空间效率。
Related Work
Dense visual SLAM and Mapping
按时间线介绍: 早期的场景表示使用TSDF,之后使用可扩展(scalable)的表示方式,如:octree等,更进一步地,还可以在tracking上加入loop做改进(BundleFusion);解决noise depth maps(RoutedFusion),NeuralFusion和 DI-Fusion在此基础上进行扩展;使用RGB作为输入;优化测试时间…但是,没有方法支持高保真度的输入自适应场景编码。
Scene Representation
(1) grid-based
优势——快速查找上下文
劣势——需要提前确定分辨率,在重建过程中无法根据场景灵活调整,造成时间和空间的浪费
(2) point-based
优势——无需提前指定分辨率,具有自适应性 (解决了gird-based的问题)
劣势——结构缺乏连通性 (现有方法和本方法如何解决)
(3) network-basd
可以恢复出高质量的场景,具有连续性,但是无法实时——不能局部更新且表示大场景
本方法基于network-based但是保证了实时性和可扩展性
(4) others
其他表示方法不适用于dense,而我们的方法…we look to model our scene space as a collection of unordered points with corresponding optimizable features.
Method
这里看不太懂,感觉作者在这里用的数学符号使用很混乱,表述也很混乱,细节完全对不上,暂且概述一下。有没有可能写前面的和写Method完全是两个人?
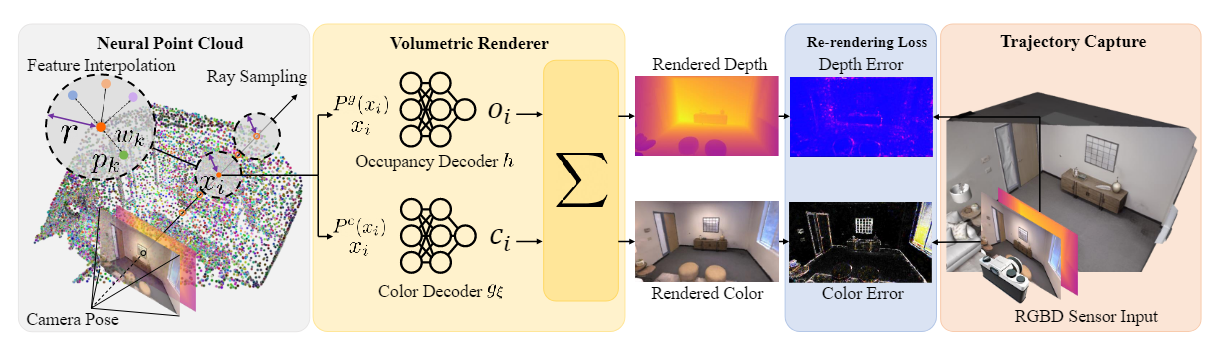
Mapping: 给定一个位姿,先添加一组稀疏点至neural poind cloud(这里的neural point cloud到底是点云还是点云的特征呢??稀疏点指的是采样的像素点对应的点云?),对于每个采样的像素点,沿射线采样出一组xi,并使用特征插值提取xi和它邻域的几何和颜色特征。(这里说是特征插值,其实就是用两个公式获取值罢了)。优化的是neural point features(隐式表示)。
Tracking: 固定map优化pose 。