Manager层的理解
MVC三层架构
MVC(Model View Controller)是软件工程中的一种软件架构模式,它把软件系统分为模型、视图和控制器三个基本部分。用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。
MVC系统的设计要遵循 MVC 架构。它将整体的系统分成了 Model(模型),View(视图)和 Controller(控制器)三个层次,也就是将用户视图和业务逻辑处理隔离开,并且通过控制器连接起来(控制器Controller 的作用就是将Model 与 View一一对应起来),很好地实现了表现和逻辑的解耦,是一种标准的软件分层架构。
MVC分层架构是架构上最简单的一种分层方式。为了遵循这种分层架构我们在构建项目时往往会建立这样三个目录:controller、service 和 dao,它们分别对应了表现层、逻辑层还有数据访问层。
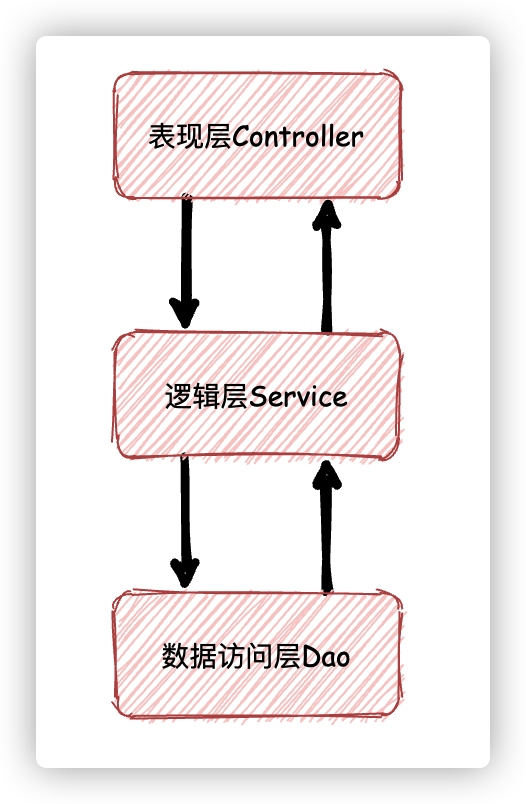
MVC与三层架构的联系
其实,无论是MVC还是三层架构,都是一种规范,都是奔着"高内聚,低耦合"的思想来设计的。三层中的UI和Servlet来分别对应MVC中的View和Controller,业务逻辑层是来组合数据访问层的原子性功能的。
在三层中,业务逻辑层和数据访问层要遵循面向接口编程。这种接口定义和具体实现逻辑的分开,非常有利于后续扩展和维护!
每层的作用如下:
- Controller层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理。
- Service层:主要是处理业务逻辑和事务
- Dao层:负责与底层数据库MySQL,Oracle等进行数据交互
MVC架构弊端
但在现如今,项目越来越庞大,业务逻辑越来复杂,代码写的越来越多,这种简单的三层架构的问题也就浮现了出来:
- Service层代码臃肿
- Service层很容易出现大事务,事务嵌套,导致问题很多,而且极难排查
- dao层参杂业务逻辑
- dao层sql语句复杂,关联查询比较多
《Alibaba java开发手册》就建议我们在Service层之下再独立出一个通用业务处理层(Manager层)
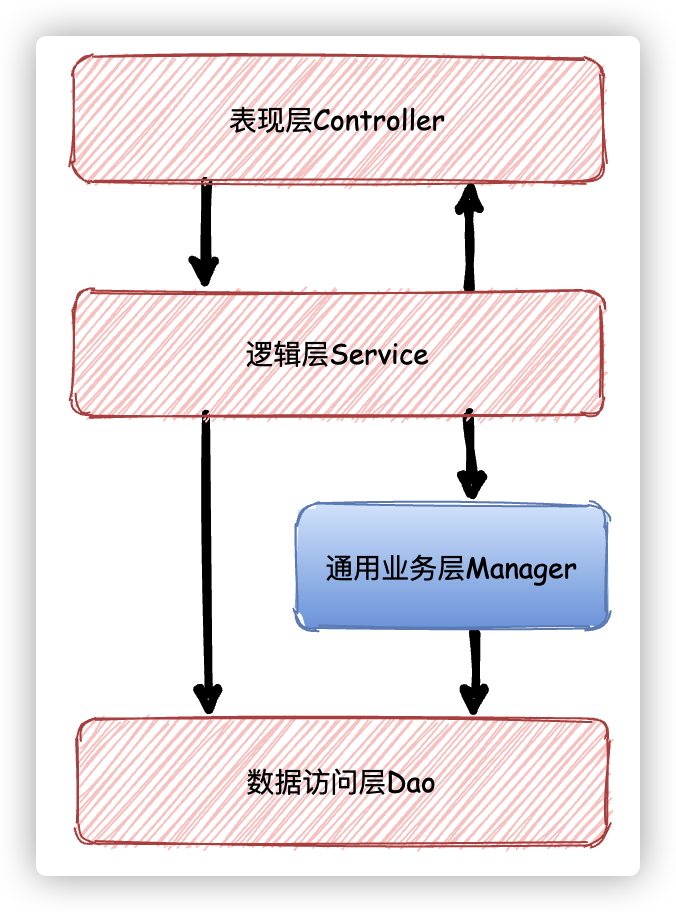
数据交互模型图:
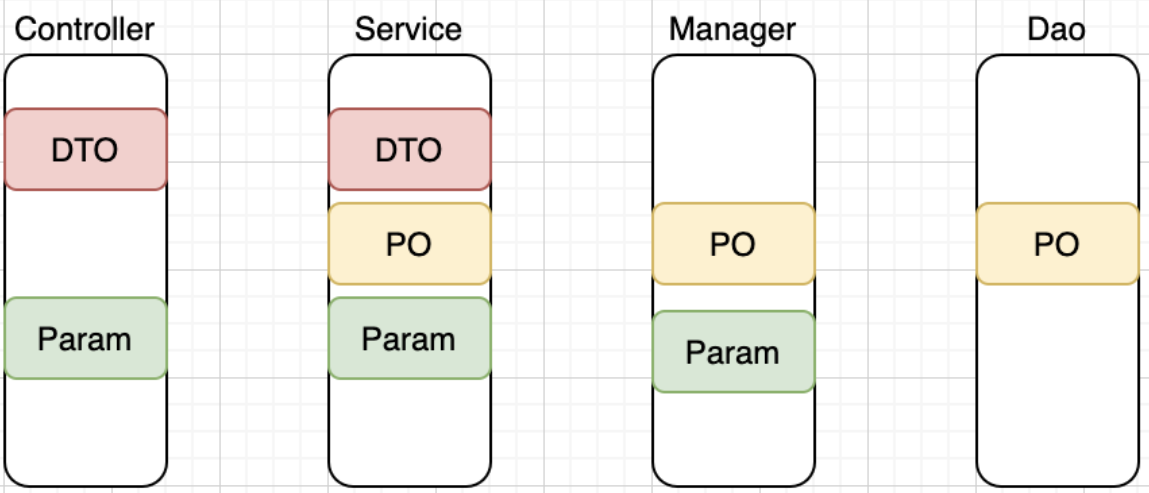
PO=DO,数据对象即与数据库表一一对应的数据模型,manager处理的对象是DO。DTO是数据传输对象(类似model),用于service层,业务逻辑处理之后将数据对象转换为DTO返回给控制层处理,控制层转换为VO返回给前端页面。
在这个分层架构中增加了 Manager 层,它与 Service 层的关系是:Manager 层提供原子的服务接口,Service 层负责依据业务逻辑来编排原子接口。
Manager层的特征
在《alibaba java开发手册》中是这样描述Manager层的:
Manager 层:通用业务处理层,它有如下特征:
- 对第三方平台封装的层,预处理返回结果及转化异常信息(适配上层接口);
- 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理;
- 与 DAO 层交互,对多个 DAO 的组合复用。
在实际开发中我们可以这样使用Manager层
- 复杂业务,service提供数据给Manager层,service负责业务编排,然后把事务下沉到Manager层,Manager层不允许相互调用,不会出现事务嵌套。
- 专注于不带业务sql语言,也可以在manager层进行通用业务的dao层封装。
- 避免复杂的join查询,数据库压力比java大很多,所以要严格控制好sql,所以可以在manager层进行拆分,比如复杂查询。
简言之, Manager 层提供原子服务接口,Service 层负责依据业务逻辑来编排调用原子接口。正如Manager层的含义一样,它用来存储一些通用的业务处理,所以manager层中的对象的方法都是一些复用性比较高的方法(如通用业务处理或者外围服务接口调用或者中间件的封装调用)。而service层中方法存放的都是一些定制化业务逻辑接口,它不太考虑复用,毕竟都是根据需求定制化的接口。
当然对于简单的业务,可以不使用Manager层。
Manager层使用案例
这里我们举个例子说明一下Manager层的使用场景:
假设你有一个用户系统,他有一个获取用户信息的接口,它调用逻辑Service层的 getUser 方法,getUser方法又和 User DB 交互获取数据。如下图左边展示部分。
这时,产品提出一个需求,在 APP 中展示用户信息的时候,如果用户不存在,那么要自动给用户创建一个用户。同时,要做一个 HTML5 的页面,HTML5 页面要保留之前的逻辑,也就是不需要创建用户。
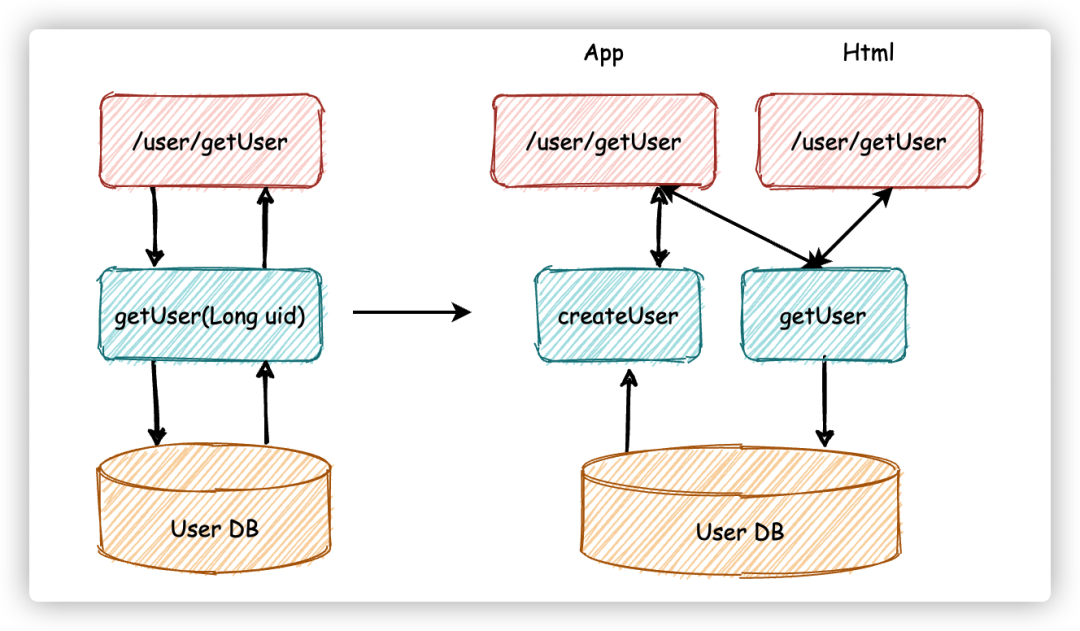
此时按照传统的三层架构,逻辑层的边界就变得不清晰,表现层也承担了一部分的业务逻辑,因为我们往往会在表现层Controller中增加业务逻辑处理,将获取用户和创建用户接口编排起来。
而添加Manager层以后,Manager 层提供创建用户和获取用户信息的接口,而 Service 层负责将这两个接口组装起来。这样就把原先散布在表现层的业务逻辑都统一到了 Service 层,每一层的边界就非常清晰了。
接下来我们看一段实际代码说明一下Service层与Manager层如何进行区分?
@Transactional(rollbackFor = Throwable.class)
public Result<String> upOrDown(Long departmentId, Long swapId) {
// 验证 1
DepartmentEntity departmentEntity = departmentDao.selectById(departmentId);
if (departmentEntity == null) {
return Result.error("部门xxx不存在");
}
// 验证 2
Long count = employeeDao.countByDepartmentId(departmentId);
if (count != null && count > 0) {
return Result.error("员工不存在");
}
// 操作数据库 3
Long departmentSort = departmentEntity.getSort();
......
return Result.OK("success");
}
上面代码在我们在我们采用三层架构时经常会遇到,那么它有什么问题呢?
- 典型的长事务问题(类似的还有调用第三方接口),前2步都需要使用 connection 进行验证操作,但由于方法上有@Transactional 注解,所以验证和业务处理这三步都是使用的同一个 connection。
- 对于复杂业务、复杂的验证逻辑,会导致整个验证过程始终占用该 connection 连接,占用时间可能会很长,直至方法结束,connection 才会交还给数据库连接池。
对于复杂业务的不可预计的情况,长时间占用同一个 connection 连接不是好的事情,应该尽量缩短占用时间。
*说明:对于@Transactional 注解,当 spring 遇到该注解时,会自动从数据库连接池中获取 connection,并开启事务然后绑定到 ThreadLocal 上,所以对于@Transactional注解包裹的整个方法都是使用同一个connection连接。但实际上如果业务并没有进入到最终的操作数据库环节,那么就没有必要获取连接并开启事务,应该直接将 connection 返回给数据库连接池,供其他使用。因为一旦数据库连接一直被占用不释放。如果类似操作过多,进而导致数据库连接池耗尽。
所以我们在加入Manager层以后可以这样写:
DepartmentService.java
public Result<String> upOrDown(Long departmentId, Long swapId) {
// 验证 1
DepartmentEntity departmentEntity = departmentDao.selectById(departmentId);
if (departmentEntity == null) {
return Result.error("部门xxx不存在");
}
// 验证 2
Long count = employeeDao.countByDepartmentId(departmentId);
if (count != null && count > 0) {
return Result.error("员工不存在");
}
// 操作数据库 3
departmentManager.upOrDown(departmentSort,swapEntity);
return Result.OK("success");
}
DepartmentManager.java
@Transactional(rollbackFor = Throwable.class)
public void upOrDown(DepartmentEntity departmentEntity ,DepartmentEntity swapEntity){
Long departmentSort = departmentEntity.getSort();
departmentEntity.setSort(swapEntity.getSort());
departmentDao.updateById(departmentEntity);
swapEntity.setSort(departmentSort);
departmentDao.updateById(swapEntity);
}
将数据在 service 层准备好,然后传递给 manager 层,由 manager 层添加@Transactional事务注解进行数据库操作。这样就只会在实际处理数据库数据的时候才会加上事务处理。但这个例子其实并不是那么好,如果是一个并发比较大的情况下,可能前一秒验证数据并不存在,下一秒就有其他线程插入了数据,此时如果只在操作数据库层面加事务就会造成错误,应在验证+操作整体加事务。这里只是为了举manager层可以解决长事务长时间占用数据库连接这一问题。
个人思考
为什么会出现分层架构呢?
软件设计原则就是高内聚低耦合,如果一个项目很庞大并且不分层的话,那么就会出现大量接口调用耦合在一起,导致后续开发和维护都会变的非常困难。分层思想就可以将这些接口根据职责分成不同的层次,每个层次有独立的职责,多个层次协同提供完整的功能,共同组成一个整体软件系统。
分层好处
分层的好处显而易见:
-
简化设计: 可以将需求拆到不同层中进行实现,每个层各司其职,不必堆到一个方法中实现。
-
高复用: 因为一个需求拆成了多个部分进行实现,后续有需求有重复设计时可以直接调用方法进行复用。比如manager层中就封装了很多通用的业务逻辑处理方法。
-
高并发: 横向扩展是高并发设计思想之一,而分层正可以帮助系统更容易地进行横向拓展。因为系统分层之后,每个层次我们都可以独立进行部署,将那些并发比较大的服务单独部署,针对具体的问题来做细致的扩展。但如果系统没有分层,当流量增加时我们需要针对整体系统来做扩展,这样难免会造成资源浪费。比如业务逻辑里面包含有比较复杂的计算,导致CPU成为性能的瓶颈,那这样就可以把逻辑层单独抽取出来独立部署,然后只对逻辑层来做扩展,这相比于针对整体系统扩展所付出的代价就要小的多了。
所以在我看来高并发系统一定是分层架构的,正如现在的微服务是系统架构风格趋势一般。
分层坏处
但万物都有两面性,分层有好处也有其坏处:
- 增加代码复杂度: 简单的请求本可以在接收请求后直接查询DB获得结果,却非要在中间多层设计,每层只简单地做数据传递。 有时增加一个小需求,可能还需更改所有层的代码,增加了开发成本,也增加了调试复杂度,如果模块之间是分组负责的还会增加组间的沟通成本。
- 性能损耗: 如果做了拓展,每层独立部署,层间互相调用(如网络交互)时就会造成性能损耗,那整个多层架构的系统势必就会在性能上有所损耗。
总结
但我们开发软件系统仍然要选择分层架构,因为任何的方案架构都是有优势有缺陷的,天地尚且不全何况我们的架构呢?分层架构固然会增加系统复杂度,也可能会有性能的损耗,但是相比于它能带给我们的好处来说,这些都是可以接受的或者可以考虑设计其它的方案解决。在做决策的时候不可以以偏概全,因噎废食。
分层架构是软件设计思想的外在体现,是一种实现方式。一些软件设计原则都在分层架构中有所体现。
比方单一职责原则规定每个类只有单一的功能,在这里可引申为每层拥有单一职责,且层与层之间边界清晰; 迪米特法则原意是一个对象应当对其它对象尽可能少的了解,在分层架构的体现是数据的交互不能跨层,只能在相邻层之间进行;
开闭原则要求软件对扩展开放,对修改关闭。它的含义其实就是将抽象层和实现层分离,抽象层是对实现层共有特征的归纳总结,不可修改,但具体实现可无限扩展,随意替换。
感谢耐心看到这里的同学,觉得文章对您有帮助的话希望同学们不要吝啬您手中的赞,动动您智慧的小手,您的认可就是我创作的动力!
之后还会勤更自己的学习笔记,感兴趣的朋友点点关注哦。