集成Hudi包
Spark-shell 方式启动
Spark SQL方式启动
SQL方式创建hudi建表
集成Hudi包
以下为hudi与spark版本的兼容
| Hudi | Supported Spark 3 version |
| 0.12.x | 3.3.x,3.2.x,3.1.x |
| 0.11.x | 3.2.x(default build, Spark bundle only),3.1.x |
| 0.10.x | 3.1.x(default build), 3.0.x |
| 0.7.0-0.9.0 | 3.0.x |
| 0.6.0 and prior | Not supported |
hudi集成到spark只需要将编译好的jar包拷贝到spark的jars目录中即可

拷贝
cp hudi-spark3.2-bundle_2.12-0.12.0.jar /opt/spark/jars
Spark-shell 方式启动
以下针对spark3.2启动写法
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Spark SQL方式启动
启动Hive的Metastore
nohup hive --service metastore &启动spark-sql
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
创建存放hudi表的数据库
create database spark_hudi
SQL方式创建hudi建表
建表参数 :
| 参数名 | 默认值 | 说明 |
| primaryKey | uuid | 表的主键名,多个字段用逗号分隔。 同 hoodie.datasource.write.recordkey.field |
| preCombineField | 表的预合并字段。 同 hoodie.datasource.write.precombine.field | |
| type | cow | 创建的表类型: type = 'cow' type = 'mor' 同hoodie.datasource.write.table.type |
创建非分区表
创建一个cow表,默认primaryKey 'uuid',不提供preCombineField
create table hudi_cow_nonpcf_tbl (
uuid int,
name string,
price double
) using hudi;
创建一个mor非分区表
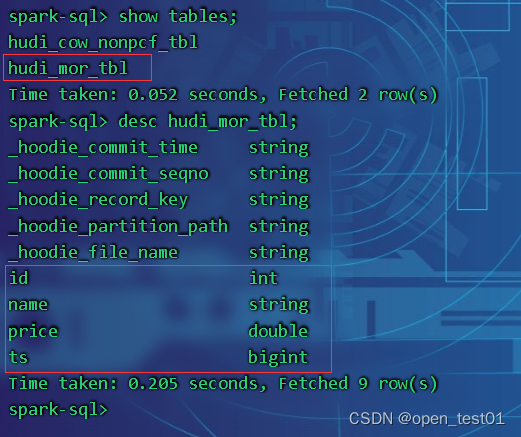
create table hudi_mor_tbl (
id int,
name string,
price double,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
);参数解读:
type = '指定表的类型',
primaryKey = '指定主键',
preCombineField = '指定预聚合字段'
创建一个cow分区外部表,指定primaryKey和preCombineField
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/user/hive/warehouse/spark_hudi.db/hudi_cow_pt_tbl';在已有的hudi表上创建新表
不需要指定模式和非分区列(如果存在)之外的任何属性,Hudi可以自动识别模式和配置。
非分区表 :
create table hudi_cp using hudi
location '/user/hive/warehouse/spark_hudi.db/hudi_cow_pt_tbl';分区表:
create table hudi_cp_pt using hudi
partitioned by (dt, hh)
location '/user/hive/warehouse/spark_hudi.db/hudi_cow_pt_tbl';
通过CTAS (Create Table As Select)建表
通过CTAS创建cow非分区表,不指定preCombineField
create table hudi_ctas_cow_nonpcf_tbl
using hudi
tblproperties (primaryKey = 'id')
as
select 1 as id, 'a1' as name, 10 as price;通过CTAS创建cow分区表,指定preCombineField
create table hudi_ctas_cow_pt_tbl
using hudi
tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts')
partitioned by (dt)
as
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt;通过CTAS从其他表加载数据
# 创建内部表
create table parquet_mngd using parquet location 'file:///tmp/parquet_dataset/*.parquet';
# 通过CTAS加载数据
create table hudi_ctas_cow_pt_tbl2 using hudi location 'file:/tmp/hudi/hudi_tbl/' options (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (datestr) as select * from parquet_mngd;Hive与Hudi建表指定分区的区别
hive:
create table hive_tb ( uuid int, name string, price double, ) partitioned by (day string)hudi:
create table hudi_tb ( uuid int, name string, price double, day ) partitioned by (day string)在hive创建分区表时指定的分区字段为外加上的字段,所以在表结构中不需要写出。
而hudi创建分区表时则需要在表结构中写出分区字段并指定为分区字段




![[刷题]贪心入门](https://img-blog.csdnimg.cn/1c2ea4f5788f4b83a7aa13c3a3604490.png)