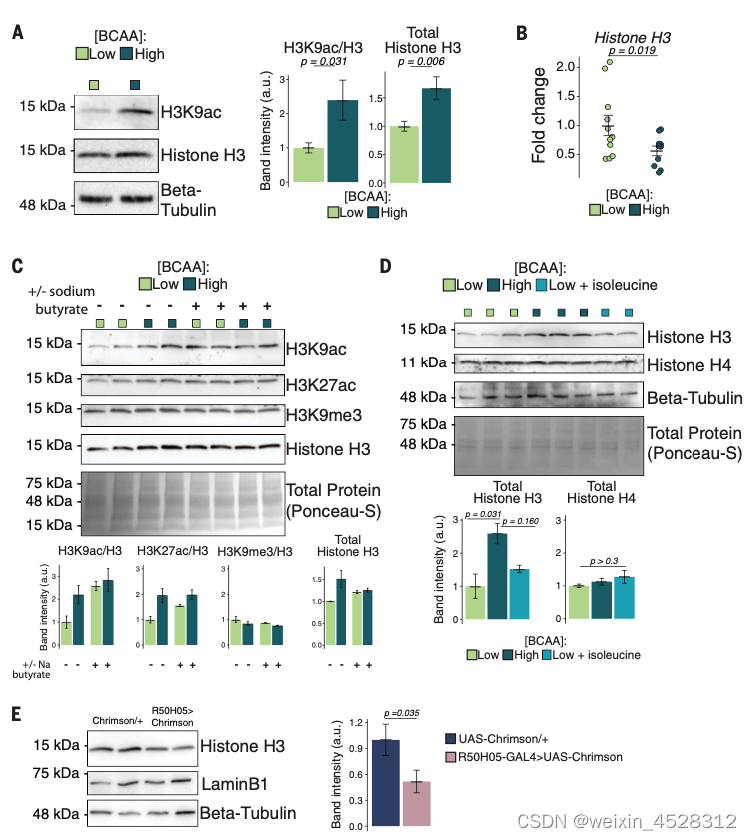
文章目录
- 一、数据集介绍
- 二、源代码 + 结果
- 三、代码逐行解读
一、数据集介绍
CELEBA 数据集(CelebFaces Attributes Dataset)是一个大规模的人脸图像数据集,旨在用于训练和评估人脸相关的计算机视觉模型。该数据集由众多名人的脸部图像组成,提供了丰富的人脸属性标注信息。
以下是 CELEBA 数据集的一些详细信息:
- 规模:CELEBA 数据集包含超过 20 万张名人的脸部图像样本。
- 图像内容:数据集中的图像涵盖了各种不同种族、年龄、性别、发型、妆容等的人脸图像,以提供更广泛的人脸表征。
- 标注信息:除了图像本身,CELEBA 数据集还提供了一系列的属性标注信息。这些属性包括性别、年龄、眼镜、微笑等。每个图像都有对应的二进制属性标签,用于指示该图像是否具有某个属性。
- 数据集组织:CELEBA 数据集的图像以 JPEG 格式存储,并使用标注文件进行关联。标注文件( list_attr_celeba.txt )包含每个图像的文件名及其相关属性标签。
- 应用领域:CELEBA 数据集被广泛用于人脸属性识别、人脸检测、人脸生成、人脸识别等计算机视觉任务的研究和开发。
CELEBA 数据集的丰富性和规模使其成为人脸相关算法的重要基准数据集之一。研究人员和开发者可以利用该数据集来训练和评估人脸相关的深度学习模型,推动人脸识别、人脸属性分析等领域的进展。
需要注意的是,CELEBA 数据集的具体细节和使用方式可能会有更新和改变。建议在使用数据集时查阅最新的文档和数据集发布者的说明。
CELEBA 数据集每一部分的解释和名称如下:
CELEBA 数据集由多个部分组成,每个部分包含不同的信息和用途。以下是 CELEBA 数据集的一些主要部分及其解释和名称:
- 图像文件夹(img_align_celeba):该部分包含了 CELEBA 数据集的人脸图像文件,以 JPEG 格式存储。图像文件夹通常包含大量的人脸图像,用于进行人脸相关任务的训练、测试和评估。
- 标注文件(list_attr_celeba.txt):该部分是 CELEBA 数据集的属性标注文件,它提供了每个图像的属性信息。属性标注文件是一个文本文件,包含了图像文件名及其对应的属性标签。这些属性标签描述了图像中的人脸属性,例如性别、年龄、微笑、眼镜等。
- 划分文件(list_eval_partition.txt):这个部分是 CELEBA 数据集的划分文件,用于将数据集划分为训练集、验证集和测试集。划分文件是一个文本文件,包含了每个图像的文件名及其所属的划分集合。
- 人脸边界框文件(list_bbox_celeba.txt):这个部分包含了 CELEBA 数据集中每个图像的人脸边界框信息。人脸边界框文件是一个文本文件,包含了每个图像的文件名以及对应的人脸边界框的坐标信息。
- 人脸关键点文件(list_landmarks_celeba.txt):这个部分包含了 CELEBA 数据集中每个图像的人脸关键点信息。人脸关键点文件是一个文本文件,包含了每个图像的文件名以及对应的人脸关键点的坐标信息。
这些部分是 CELEBA 数据集中常用的部分,用于获取图像、属性标注、划分信息以及人脸边界框和关键点信息。使用这些部分的数据,可以进行各种人脸相关任务的训练、评估和分析。
二、源代码 + 结果
import clip
import torch
import torchvision
import time
device = "cuda" if torch.cuda.is_available() else "cpu"
def model_load(model_name):
# 加载模型
model, preprocess = clip.load(model_name, device) #ViT-B/32 RN50x16
return model, preprocess
def data_load(data_path):
# 加载数据集和文字描述
celeba = torchvision.datasets.CelebA(root = './39.AIGC/CELEBA', split = 'test', download = True)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in celeba.attr_names]).to(device)
return celeba, text_inputs
def test_model(start, end, celeba, text_inputs, model, preprocess):
# 测试模型
length = end - start + 1
face_accuracy = 0
face_score = 0
for i, data in enumerate(celeba):
face_result = 0
if i < start:
continue
image, target = data
image_input = preprocess(image).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
image_features /= image_features.norm(dim = -1, keepdim = True)
text_features /= text_features.norm(dim = -1, keepdim = True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim = -1)
top_score, top_label = text_probs.topk(6, dim = -1)
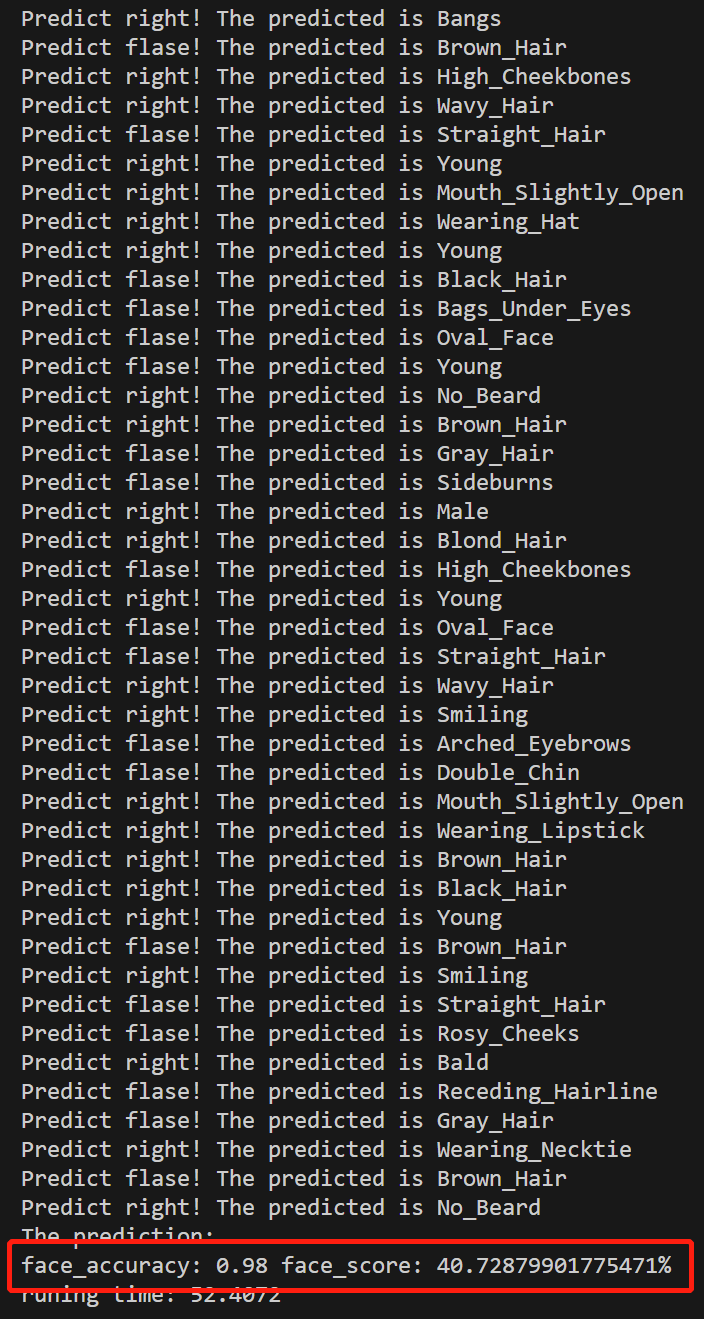
for k, score in zip(top_label[0], top_score[0]):
if k.item() < 40 and target[k.item()] == 1:
face_result = 1
face_score += score.item()
print('Predict right! The predicted is {}'.format(celeba.attr_names[k.item()]))
else:
print('Predict flase! The predicted is {}'.format(celeba.attr_names[k.item()]))
face_accuracy += face_result
if i == end:
break
face_score = face_score / length
face_accuracy = face_accuracy / length
return face_score, face_accuracy
if __name__ == '__main__':
start = 0
end = 1000
model_name = 'ViT-B/32'
data_path = 'CELEBA'
time_start = time.time()
model, preprocess = model_load(model_name)
celeba, text_inputs = data_load(data_path)
face_score, face_accuracy = test_model(start, end, celeba, text_inputs, model, preprocess)
time_end = time.time()
print('The prediction:')
print('face_accuracy: {:.2f} face_score: {}%'.format(face_accuracy, face_score * 100))
print('runing time: %.4f' % (time_end - time_start))
三、代码逐行解读
import clip
import torch
import torchvision
import time
这段代码导入了 clip、torch、torchvision 和 time 库。这些库提供了用于计算机视觉和深度学习任务的功能和工具。
- clip 是一个用于视觉和文本数据的深度学习模型库,可以将图像和文本进行编码和匹配。
- torch 是 PyTorch 库,提供了张量操作、神经网络模型、优化器等工具。
- torchvision 是 PyTorch 的一个扩展库,提供了常用的计算机视觉数据集、模型架构和图像处理工具。
- time 是 Python 标准库,提供了计时和时间相关的函数。
device = "cuda" if torch.cuda.is_available() else "cpu"
这行代码用于选择设备(device),可以是 CUDA 加速的 GPU 设备或者 CPU 设备。它使用了条件表达式(if-else)来检查系统是否有可用的 CUDA 设备。如果有可用的 CUDA 设备,将设备设置为 “cuda” ;否则,将设备设置为 “cpu”。
def model_load(model_name):
# 加载模型
model, preprocess = clip.load(model_name, device) #ViT-B/32 RN50x16
return model, preprocess
这个函数用于加载 CLIP 模型和预处理函数。
具体解读如下:
- model_load 是一个函数,接受一个 model_name 参数作为输入。
- 在函数内部,调用了 clip.load(model_name, device) 来加载 CLIP 模型和预处理函数。 model_name 指定了要加载的 CLIP 模型的名称,device 指定了要在哪个设备上加载模型(之前定义的 device 变量)。
- clip.load() 函数返回一个模型对象和一个预处理函数对象。
- 最后,函数将加载的模型对象和预处理函数对象作为结果返回。
def data_load(data_path):
# 加载数据集和文字描述
celeba = torchvision.datasets.CelebA(root = './39.AIGC/CELEBA', split = 'test', download = True)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in celeba.attr_names]).to(device)
return celeba, text_inputs
这个函数用于加载数据集和生成与数据集相关的文字描述。
- data_load 是一个函数,接受一个 data_path 参数作为输入。
- 在函数内部,调用了 torchvision.datasets.CelebA 来加载 CelebA 数据集。root 参数指定了数据集的根目录路径,split 参数指定了要加载的数据集划分(这里使用的是测试集),download 参数指定了是否下载数据集(设为 True 表示下载)。
- 在加载 CelebA 数据集后,通过遍历 celeba.attr_names 中的每个属性名称,使用 clip.tokenize() 函数生成与属性名称相关的文字描述,并使用 torch.cat() 函数将这些描述连接起来。最终,得到的文字描述张量被转移到指定的设备上(之前定义的 device 变量)。
- 最后,函数将加载的数据集对象和生成的文字描述张量作为结果返回。
def test_model(start, end, celeba, text_inputs, model, preprocess):
# 测试模型
length = end - start + 1
face_accuracy = 0
face_score = 0
for i, data in enumerate(celeba):
face_result = 0
if i < start:
continue
image, target = data
image_input = preprocess(image).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
image_features /= image_features.norm(dim = -1, keepdim = True)
text_features /= text_features.norm(dim = -1, keepdim = True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim = -1)
top_score, top_label = text_probs.topk(6, dim = -1)
for k, score in zip(top_label[0], top_score[0]):
if k.item() < 40 and target[k.item()] == 1:
face_result = 1
face_score += score.item()
print('Predict right! The predicted is {}'.format(celeba.attr_names[k.item()]))
else:
print('Predict flase! The predicted is {}'.format(celeba.attr_names[k.item()]))
face_accuracy += face_result
if i == end:
break
face_score = face_score / length
face_accuracy = face_accuracy / length
return face_score, face_accuracy
这个函数用于测试模型的性能。
- test_model 是一个函数,接受 start、end、celeba、text_inputs、model 和 preprocess 作为输入。
- 在函数内部,首先初始化一些变量,包括 length(表示要处理的图像数量)、face_accuracy(用于记录人脸识别的准确率)和 face_score(用于记录人脸识别的得分)。
- 然后,使用 enumerate(celeba) 遍历 CelebA 数据集,其中i表示当前迭代的索引,data 表示当前迭代的数据。
- 在每次迭代中,首先将 face_result 初始化为 0。然后,通过 data 获取当前图像和目标标签。
- 接下来,将图像输入预处理函数 preprocess 进行预处理,并通过 unsqueeze(0) 在批次维度上添加一个维度。然后将处理后的图像输入到模型中,分别使用 model.encode_image() 和 model.encode_text() 来获取图像特征和文字特征。
- 对于图像特征和文字特征,进行归一化处理,将每个特征向量除以其范数,以使其长度为 1。
- 使用归一化后的特征计算图像特征与文字特征之间的相似度,通过矩阵乘法和 softmax 操作得到预测的文本概率分布 text_probs。
- 接下来,使用 topk() 函数获取预测概率最高的 6 个标签,并遍历每个标签和对应的得分。
- 如果预测的标签索引小于 40 且目标标签中对应索引的值为 1(表示该属性为真),则将 face_result 设置为 1,并将得分累加到 face_score 中,同时打印预测正确的信息;否则,打印预测错误的信息。
- 最后,将 face_result 累加到 face_accuracy 中,判断是否达到了指定的结束索引 end,如果是,则终止循环。
- 计算平均得分和平均准确率,并将其作为结果返回。
总的来说,这个函数的作用是对模型进行测试,并计算人脸识别的平均得分和平均准确率。在测试过程中,它遍历 CelebA 数据集中的图像,计算图像与文字特征之间的相似度,并根据预测的结果评估模型的性能。
if __name__ == '__main__':
start = 0
end = 1000
model_name = 'ViT-B/32'
data_path = 'CELEBA'
time_start = time.time()
model, preprocess = model_load(model_name)
celeba, text_inputs = data_load(data_path)
face_score, face_accuracy = test_model(start, end, celeba, text_inputs, model, preprocess)
time_end = time.time()
print('The prediction:')
print('face_accuracy: {:.2f} face_score: {}%'.format(face_accuracy, face_score * 100))
print('runing time: %.4f' % (time_end - time_start))
这段代码是整个程序的入口点,它实现了整个流程的控制和输出结果。
- if name == ‘main’:是 Python 中的条件语句,表示当该脚本被直接运行时(而不是作为模块导入时),以下的代码块将被执行。
- 在该代码块中,首先定义了一些变量,包括 start(开始索引)、end(结束索引)、model_name(模型名称)和 data_path(数据集路径)。
- 通过 time.time() 获取当前时间,将其记录为 time_start,以便后续计算程序的运行时间。
- 调用 model_load(model_name) 函数加载指定名称的模型,并将返回的 model 和 preprocess 赋值给 model 和 preprocess 变量。
- 调用 data_load(data_path) 函数加载数据集,并将返回的 celeba 和 text_inputs 赋值给 celeba 和 text_inputs 变量。
- 调用 test_model(start, end, celeba, text_inputs, model, preprocess) 函数对模型进行测试,获取人脸识别的得分和准确率,分别赋值给 face_score 和 face_accuracy 变量。
- 通过 time.time() 获取当前时间,将其记录为 time_end,以便计算程序的运行时间。
- 使用 print() 函数输出预测结果,包括人脸准确率、人脸得分和运行时间。
总的来说,该部分代码是整个程序的入口,它负责加载模型、加载数据集、测试模型并输出结果。通过设定的参数对模型进行测试,并打印出人脸识别的准确率、得分和程序运行时间。






![[离散数学]图论](https://img-blog.csdnimg.cn/8ffc7dd092fe43ac936d46772ede3c9d.png)