ChatSQL将用户提供的纯文本转换为 mysql 查询,基于ChatGPT实现。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、ChatSQL简介
我们需要从一开始就指定一些关于我们数据库的信息,以便 Chatgpt 了解我们的数据库。 info.json 文件可用于此过程。 应在此文件中详细添加数据库信息。
随着数据库复杂性的增加,应该提供更详细的信息。 在一定程度的复杂性之后,必须通过矢量化和自主提取每个传入提示的特定信息结构来保存此数据。 这种方法会更有效、更经济。 因此,ChatSQL更适合中小型数据库。 如果以后时间充裕,我会做一个关于大数据库的新项目。
Openai api 密钥和数据库信息应添加到 conf.json 文件中。 你想尝试这个项目,但你可能没有样本数据集。 可以使用 books.csv 文件进行测试。
2、ChatSQL安装
在开始之前安装所有包。 本次安装过程使用以下命令(本项目使用python 3.8):
make install
或者
pip3 install --default-timeout=900 -r requirements.txt
然后运行 sample_data_creator.py 将示例数据集插入到自己的数据库中。 可以使用以下命令(默认表名是“bt”)。
python3 sample_data_creator.py
3、ChatSQL快速上手
现在我们的数据已经准备好,所可以开始使用它了。
有两种不同的使用方法。 首先是运行 chatsql.py 文件。 在此方法中,提示被添加为标志。 在第二种方法中,它是通过 grpc 服务器使用的。
3.1 使用 ChatSql
可以在下面查看数据库示例。
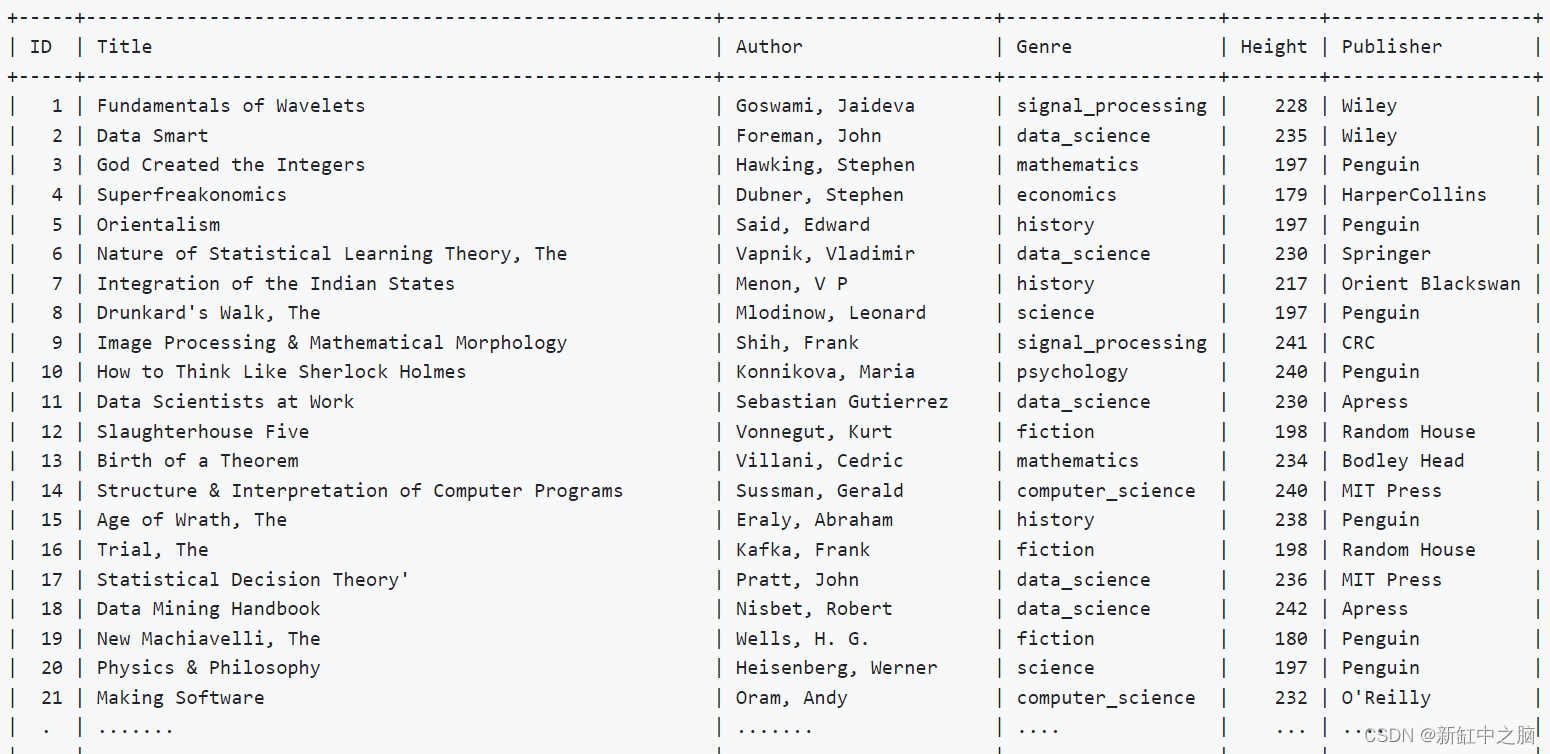
这是我们的示例提示:
Show me the book type fiction which they height bigger than 175 and smaller than 178. The author shoudn’t be ‘Doyle, Arthur Conan’
查询高度大于 175 且小于 178 、作者非‘Doyle, Arthur Conan’的小说
使用如下命令传入提示:
python3 chatsql.py -p 'Show me the book type fiction which they height bigger than 175 and smaller than 178. The author shouldn't be 'Doyle, Arthur Conan'. '
结果如下:
CHATGPT QUERY------------------:
SELECT * FROM bt WHERE Genre = 'Fiction' AND Height > 175 AND Height < 178 AND Author != 'Doyle, Arthur Conan'
RAW RESULT------------------:
[(32, 'Pillars of the Earth, The', 'Follett, Ken', 'fiction', 176, 'Random House'), (37, 'Veteran, The', 'Forsyth, Frederick', 'fiction', 177, 'Transworld'), (38, 'False Impressions', 'Archer, Jeffery', 'fiction', 177, 'Pan'), (72, 'Prisoner of Birth, A', 'Archer, Jeffery', 'fiction', 176, 'Pan'), (87, 'City of Joy, The', 'Lapierre, Dominique', 'fiction', 177, 'vikas'), (128, 'Rosy is My Relative', 'Durrell, Gerald', 'fiction', 176, 'nan')]
PROCESSED RESULT------------------ :
The books 'Pillars of the Earth, The' by Ken Follett, 'Veteran, The' by Frederick Forsyth, 'False Impressions' by Jeffery Archer, 'Prisoner of Birth, A' by Jeffery Archer, 'City of Joy, The' by Dominique Lapierre, and 'Rosy is My Relative' by Gerald Durrell are all fiction books with 176 or 177 pages published by Random House, Transworld, Pan, Vikas, and Nan, respectively.
从上面可以看出,得到了三种不同的输出结果。 第一个结果是将给定提示转换为 sql 查询。 原始结果是作为此查询的结果从数据库返回的原始数据。 最后,处理后的数据是chatgpt将sql结果解释为纯文本。
3. 2 通过 gRPC 使用ChatSQL
启动gRPC 服务器:
python3 main.py -p 9001
运行 gRPC 服务器后,可以使用自己的客户端连接到此服务器并发送提示。 如果想查看示例,可以查看 client.py 文件。
python3 client.py
结果如下:
{'query': "SELECT * from bt WHERE Genre = 'Fiction' AND Height > 175 AND Height < 178 AND Author != 'Doyle, Arthur Conan'", 'raw_result': "[(32, 'Pillars of the Earth, The', 'Follett, Ken', 'fiction', 176, 'Random House'), (37, 'Veteran, The', 'Forsyth, Frederick', 'fiction', 177, 'Transworld'), (38, 'False Impressions', 'Archer, Jeffery', 'fiction', 177, 'Pan'), (72, 'Prisoner of Birth, A', 'Archer, Jeffery', 'fiction', 176, 'Pan'), (87, 'City of Joy, The', 'Lapierre, Dominique', 'fiction', 177, 'vikas'), (128, 'Rosy is My Relative', 'Durrell, Gerald', 'fiction', 176, 'nan')]", 'processed_result': "\n1. Ken Follett's 'Pillars of the Earth, The' is a fiction novel with 176 pages that was published by Random House.\n2. Frederick Forsyth's 'Veteran, The' is a fiction novel with 177 pages that was published by Transworld.\n3. Jeffery Archer's 'False Impressions' is a fiction novel with 177 pages that was published by Pan.\n4. Jeffery Archer's 'Prisoner of Birth, A' is a fiction novel with 176 pages that was published by Pan.\n5. Dominique Lapierre's 'City of Joy, The' is a fiction novel with 177 pages that was published by Vikas.\n6. Gerald Durrell's 'Rosy is My Relative' is a fiction novel with 176 pages that was published by Nan."}
Time: 10.407907724380493
3.3 通过 Docker 使用gRPC
如果你想通过 docker 创建 gRPC 服务器(默认镜像名称 --> chatsql):
make docker
使用如下命令启动容器:
make docker_run p=9001
然后就可以利用客户端查询了:
python3 client.py
结果如下:
'query': "SELECT * FROM bt WHERE Genre = 'Fiction' AND Height > 175 AND Height < 178 AND Author != 'Doyle, Arthur Conan'", 'raw_result': "[(32, 'Pillars of the Earth, The', 'Follett, Ken', 'fiction', 176, 'Random House'), (37, 'Veteran, The', 'Forsyth, Frederick', 'fiction', 177, 'Transworld'), (38, 'False Impressions', 'Archer, Jeffery', 'fiction', 177, 'Pan'), (72, 'Prisoner of Birth, A', 'Archer, Jeffery', 'fiction', 176, 'Pan'), (87, 'City of Joy, The', 'Lapierre, Dominique', 'fiction', 177, 'vikas'), (128, 'Rosy is My Relative', 'Durrell, Gerald', 'fiction', 176, 'nan')]", 'processed_result': '\nThe books "Pillars of the Earth, The" by Ken Follet, "Veteran, The" by Frederick Forsyth, "False Impressions" by Jeffery Archer, "Prisoner of Birth, A" by Jeffery Archer, "City of Joy, The" by Dominique Lapierre and "Rosy is My Relative" by Gerald Durrell are all fiction books with page count 176 or 177 and published by Random House, Transworld, Pan, Vikas or Nan.'}
Time: 7.1615989208221436
注意:如果你想使用docker,应该在docker中配置网络。
例如,如果使用的是 mac 设备并通过本地主机连接到 mysql 数据库,则应设置“host.docker.internal”而不是“localhost”(在 conf.json 文件中 - “HOST”:“host.docker. 内部”)。
4、额外信息
在目前的例子中,数据库中的列名总是有意义的。 ChatGPT 可以通过了解列名来生成查询。 但是,在某些情况下,列名是无意义的,或者 chatgpt 可能无法理解它们。 如果我们在 info.json 文件中添加足够多的关于数据库的详细信息,我们将继续得到我们想要的结果。 例如,让我们将列名称更改为 aa、bb、cc、dd、ee。

如果我们详细解释列名并运行 client.py -->
{'query': "SELECT aa, bb, cc, dd FROM bt WHERE cc = 'fiction' AND dd > 175 AND dd < 178 AND bb != 'Doyle, Arthur Conan'", 'raw_result': "[('Pillars of the Earth, The', 'Follett, Ken', 'fiction', 176), ('Veteran, The', 'Forsyth, Frederick', 'fiction', 177), ('False Impressions', 'Archer, Jeffery', 'fiction', 177), ('Prisoner of Birth, A', 'Archer, Jeffery', 'fiction', 176), ('City of Joy, The', 'Lapierre, Dominique', 'fiction', 177), ('Rosy is My Relative', 'Durrell, Gerald', 'fiction', 176)]", 'processed_result': '\nThe books "Pillars of the Earth, The" by Ken Follett, "Veteran, The" by Frederick Forsyth, "False Impressions" by Jeffery Archer, "Prisoner of Birth, A" by Jeffery Archer, "City of Joy, The" by Dominique Lapierre and "Rosy is My Relative" by Gerald Durrell are all fiction and have page lengths of 176 or 177.'}
我的下一个项目可能会使用免费模型 (Llama) 从提示生成查询(mongo、sql),请继续关注!
原文链接:ChatSQL:文本生成SQL — BimAnt