大家好,我是带我去滑雪!
深度学习算法是一种神经网络,而神经网络就是数据结构的图形结构,函数集的运算是向量和矩阵运算,调整函数集的参数需要使用微分和偏微分来找出最优解。深度学习可以通过几何学来进行解释,从几何学上看,深度学习是一种平面坐标的转换。假设在一个三维空间中,在手中有两张蓝色和红色的纸,用手将两张纸揉成团,那么这个由纸构成的团就为深度学习中的输入数据。很明显,这是一个分类问题,我们需要将这个由蓝红两张纸构成的团,分成蓝色和红色两类。神经网络的工作就是将这个团,通过多个神经层来转换这个团,直到将两张纸分开。下面学习一些神经网络的常用知识。
目录
1、神经网络的学习方式、学习目标、训练循环
(1)神经网络的学习方式与学习目标
(2)神经网络的训练循环
2、神经网络到底学到了什么?
3、激活函数与损失函数
(1)激活函数
(2)损失函数
4、梯度下降法与反向传播算法
(1)梯度下降法
(2)反向传播算法
5、神经网络的样本和标签数据
6、样本数据—特征标准化
(1)特征标准化
(2)训练集、验证集、测试集
(3)训练周期、批次、批次尺寸
1、神经网络的学习方式、学习目标、训练循环
(1)神经网络的学习方式与学习目标
神经网络的学习目标:找出正确的权重值来缩小损失(损失是指实际值与预测值之间的差距)。神经网络的学习方式:神经网络的输入值X,在经过每一层 f 的数据转换的计算后,可以得到预测值Y',因为是监督学习,输入数据X有对应的真实目标值Y,也称为标签,可以使用损失函数计算Y‘与Y之间差异的损失分数,随后通过优化器来更新权重,找出最好的权重减少损失分数,以便缩小预测值与目标值之间的差异。
(2)神经网络的训练循环
神经网络可以自行使用数据来自自我训练,这个训练步骤不是只会进行一次,而是一个训练循环,其需要重复输入数据来训练很多次,这个被称为迭代。训练循环会进行到训练出最优的预测模型为止。
在神经网络的训练循环环节可以分为正向传播、评估损失、反向传播三大阶段,输入的数据经过正向传播计算出预测值,与真实目标值比较后计算出损失,然后使用反向传播计算出每一层神经层的错误比例,使用梯度下降法来更新权重。因为神经网络本身是一张计算图,决定如何从输入数据计算出预测值,并反过来计算各权重的更新比例。事实上,整个训练循环的步骤均是围绕着权重的初始化、使用和更新操作。
上述训练循环会一直重复进行,直到符合一定条件才会停止训练,神经网络的循环步骤如下:
- 第一步:初始化权重。整个训练循环从初始化权重开始,通常使用随机数来初始化每一层的权重,这些权重构成神经网络的参数;
- 第二步:使用正向传播计算预测值。使用输入数据以正向传播的方式,通过整个神经网络来计算出预测值,使用第一步中的权重计算出这些预测值,使用 f(wx+b)。wx为点积运算,f()为激活函数;
- 第三步:评估预测值与真实值误差的损失。在经过反向传播计算出预测值之后,使用损失函数计算这些预测值与真实值之间的误差,根据不同的问题,可以选择不同的损失函数进行计算;
- 第四步:使用反向传播计算更新权重的比例。当使用损失函数计算出损失分数后,可以使用连锁律(由于神经网络具有很多层,前一层的输出会变成后一层的输入,连锁率是指从外向内一层一层进行微分)和偏微分反向从输出层到输入层,使用反向传播算法计算出每一层神经网络的权重所造成的损失比,即梯度;
- 更新权重并继续下一次训练。在使用反向传播算法计算出各层权重的梯度后,就可以使用梯度下降法更新权重,即更新整个神经网络的参数,以达到减少整体损失并创建更好的神经网络预测模型。最好,可以使用更新参数进行下一次训练,即重复第二步到第五步,直到训练出最优的预测模型。
2、神经网络到底学到了什么?
当训练神经网络时,并不是进行越多次训练循环就越能够训练出最好的预测模型,随着训练循环次数的增加,神经网络的更新权重数量和次数也相应赠加,神经网络的学习曲线会经历低度拟合、最优化、过度拟合三个阶段。低度拟合:训练误差太大,神经网络压根儿没有学习成功,最优化:理想的神经网络训练目标,过度拟合:神经网络模型已经过度学习,所建立的模型缺乏泛化性。拟合是指将获取的数据吻合一个连续函数,即一条曲线。泛化性是指预测模型对于未知的数据也具有很好的预测性。
想要理解神经网络到底学习了什么?可以这样理解,以学生考试为例,学生需要在短时间内准备期末考试,刚开始会疯狂背书,尽可能的将知识点都死记硬背住,但随着复习的进行,你逐渐对知识点有了新的认识,能够融会贯通举一反三,并记住了知识点的核心内容,这就类似泛化性。相反,如果知识死记硬背,无法融会贯通、举一反三,就是过度拟合。
3、激活函数与损失函数
(1)激活函数
对神经网络的神经元使用激活函数,可以让神经元执行非线性数据的转化。神经网络如果没有使用激活函数,那么前一层神经层输出的是张量(张量是机器学习、深度学习最最常用的基本数据结构,以程序语言来说,张量就是不同大小维度的多维数组,例如(样本数,特征1,特征2、特征3、特征4))的点积运算(点积运算是两个张量对应元素的行和列的乘积和,类似矩阵的乘法运算),不论经过多少层神经层,其拟合的都是一条线性函数。激活函数的功能就是打破线性关系,让神经网络拟合更多非线性问题,实现可以用曲线来拟合。
常用的激活函数:
- 隐藏层:常使用ReLU()函数;
- 输出层:使用Sigmoid()函数、Tanh()函数、Softmax()函数,前两个在二元分类中使用,后一个在多元分类中使用。
(2)损失函数
深度学习的目标函数就是损失函数,损失函数可以评估预测值和真实值之间的差异,损失函数是一个非负实数的函数,损失函数越小,表示预测模型越好。深度学习的回归问题的损失函数常使用均方误差,而分类问题常使用交叉熵。
均方误差(MSE)是计算预测值与真实值之间差异的平方,其计算公式:
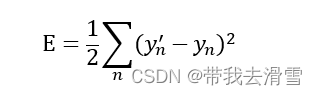
这里均方差的计算公式中为什么乘以二分之一,这只是为了方便反向传播计算梯度的微分,可以抵消平方的2,平方的目的是避免负值。
熵是物理学中用来测量混乱的程度,熵低表示混乱程度低。在信息论中的熵是用来测量不确定性。信息量是信息的量化值(单位为比特),其大小和事件发生的概率的大小相反,很少发生的事情才能引起关注,司空见惯的事情不会引起注意。信息熵是量化信息的混乱程度,计算方式为所有可能的概率乘以该概率的信息量并求和,混乱程度越低,信息熵越小。交叉熵是使用信息熵来评估两组概率向量之间的差异程度,交叉熵越小,就表示两组概率向量越接近。在深度学习中利用交叉熵计算真实值和预测值的损失分数,交叉熵越小,说明预测值越接近目标值。
4、梯度下降法与反向传播算法
(1)梯度下降法
梯度下降法是最优化理论中一种找出最佳解的方法,就是往梯度的反方向走来找出局部最小值。使用梯度下降法需要考量的重要因素是学习率,如果学习率过小,神经网络就需要多次训练来调整权重,如果学习率过大,就也可能错过全局最小值。
梯度意义:
- 在单变量函数中:梯度是函数的微分,即函数在某特定点的斜率;
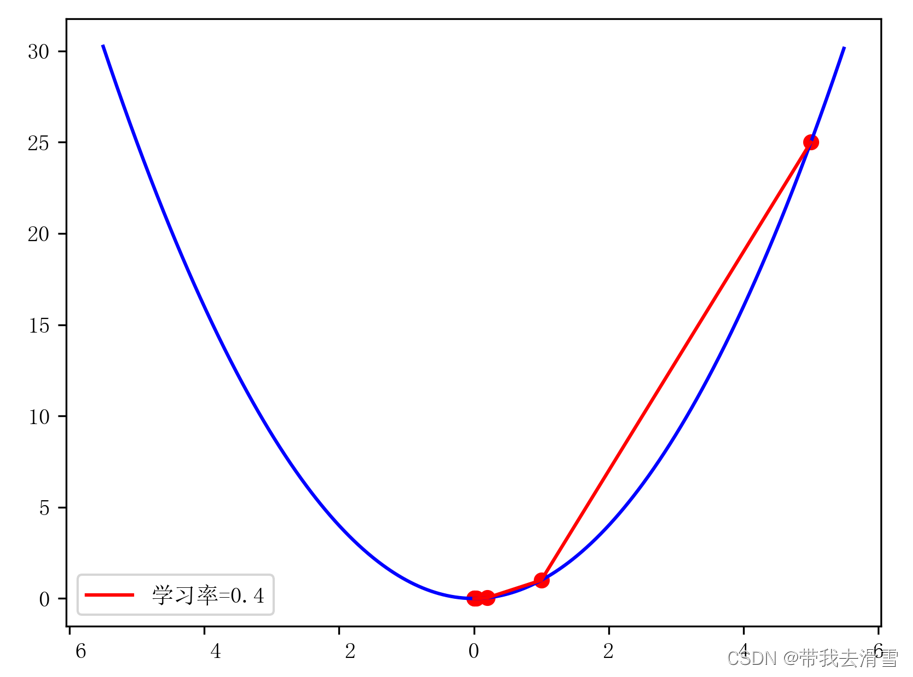
假设单变量函数为L(w)=w^2,假设起点为5,训练周期为5,学习率为0.4,使用python实现梯度下降法,代码如下:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimSun'] #'画图使中文正常显示为宋体def L(w):
return w * w
def dL(w):
return 2 * w
def gradient_descent(w_start, df, lr, epochs):#定义一个梯度函数,其参数分别是起点、微分函数名称、学习率、走几步的训练周期
w_gd = []#使用列表保留每一步计算的新位置,在指定初始位置后,使用for循环重复步数来#计算下一步梯度下降的新位置,w为目前位置,pre_w为前一个位置,最好返回每一步的位#置值
w_gd.append(w_start)
pre_w = w_startfor i in range(epochs):
w = pre_w - lr * df(pre_w)
w_gd.append(w)
pre_w = w
return np.array(w_gd)
w0 = 5
epochs = 5
lr = 0.4
w_gd = gradient_descent(w0, dL, lr, epochs)
print(w_gd)#绘制梯度下降法的图表
t = np.arange(-5.5, 5.5, 0.01)
plt.plot(t, L(t), c='b')
plt.plot(w_gd, L(w_gd), c='r', label='学习率={}'.format(lr))
plt.scatter(w_gd, L(w_gd), c='r')
plt.legend()
plt.savefig("squares1.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
- 在多变量函数中:梯度是各变量偏微分的向量,向量是有方向的,梯度就是该点变化率最大的方向。
假设有如下双变量函数:
![]()
设置起点为[2,4],学习率为0.1,使用python实现双变量函数的梯度下降法,代码如下:
import numpy as np
import matplotlib.pyplot as pltdef L(w1, w2):
return w1**2 + w2**2def dL(w):
return np.array([2*w[0], 2*w[1]])def gradient_descent(w_start, df, lr, epochs):
w1_gd = []
w2_gd = []
w1_gd.append(w_start[0])
w2_gd.append(w_start[1])
pre_w = w_startfor i in range(epochs):
w = pre_w - lr*df(pre_w)
w1_gd.append(w[0])
w2_gd.append(w[1])
pre_w = wreturn np.array(w1_gd), np.array(w2_gd)
w0 = np.array([2, 4])
lr = 0.1
epochs = 40x1 = np.arange(-5, 5, 0.05)
x2 = np.arange(-5, 5, 0.05)w1, w2 = np.meshgrid(x1, x2)
fig1, ax1 = plt.subplots()
ax1.contour(w1, w2, L(w1, w2), levels=np.logspace(-3, 3, 30), cmap='jet')
min_point = np.array([0., 0.])
min_point_ = min_point[:, np.newaxis]
ax1.plot(*min_point_, L(*min_point_), 'r*', markersize=10)
ax1.set_xlabel('w1')
ax1.set_ylabel('w2')w1_gd, w2_gd = gradient_descent(w0, dL, lr, epochs)
w_gd = np.column_stack([w1_gd, w2_gd])
print(w_gd)ax1.plot(w1_gd, w2_gd, 'bo')
for i in range(1, epochs+1):
ax1.annotate('', xy=(w1_gd[i], w2_gd[i]),
xytext=(w1_gd[i-1], w2_gd[i-1]),
arrowprops={'arrowstyle': '->', 'color': 'r', 'lw': 1},
va='center', ha='center')
plt.savefig("squares2.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

(2)反向传播算法
反向传播算法是一种训练神经网络常用的优化方法,整个算法可以分为如下3个阶段:
- 前向传播阶段:输入值经过神经网络,输出预测值;
- 反向传播阶段:将预测值与真实值计算出误差后,反向传播计算出各层权重误差比例的精度
- 权重更新阶段:依据计算出的各层权重比例的梯度,使用梯度下降法来更新权重。
5、神经网络的样本和标签数据
神经网络的样本是用来训练神经网络的数据集,标签是每一个样本对应的真实目标值。标签是监督学习训练所需样本对应的结果,神经网络在训练时才能计算预测值和真实值之间的损失分数。对于分类数据来说,因为交叉熵是使用概率向量来计算损失,我们需要先对标签执行One-hot编码,才能和Softmax函数输出概率向量进行损失分数的计算。
使用NumPy可以实现One-hot编码,假设我们需要将[5,3,7,4]这样一组标签数组,可以通过如下代码:
import numpy as np
def one_hot_encoding(raw, num):
result = []
for ele in raw:
arr = np.zeros(num)
np.put(arr, ele, 1)
result.append(arr)
return np.array(result)
digits = np.array([5, 3, 7, 4])one_hot = one_hot_encoding(digits, 10)
print('代转换标签数组:',digits)
print('独立热编码后:',one_hot)输出结果:
代转换标签数组: [5 3 7 4] 独立热编码后: [[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]]
6、样本数据—特征标准化
神经网络的样本是一个数据集,在送入神经网络训练前,需要执行特征标准化,将样本分成训练集、验证集和测试集,并确定训练周期、批次、批次尺寸。
(1)特征标准化
特征标准化的目的在于平衡特征值的贡献,一般有以下两种方法:
- 归一化:将数据缩放为0到1之间,如果数据范围是固定的,没有极端值,可以使用归一化方法;
import numpy as np
def normalization(raw):
max_value = max(raw)
min_value = min(raw)
norm = [(float(i)-min_value)/(max_value-min_value) for i in raw]
return norm
x = np.array([255, 128, 45, 0])print('原始数据:',x)
norm = '归一化后的原始数据:',normalization(x)
print(norm)输出结果:
原始数据: [255 128 45 0] ('归一化后的原始数据:', [1.0, 0.5019607843137255, 0.17647058823529413, 0.0])
- 标准化:将数据转换成均值为0,标准差为1,如果数据杂乱且存在极端值,可以使用标准化方法。
import numpy as np
from scipy.stats import zscorex = np.array([255, 128, 45, 0])
z_score = zscore(x)
print(z_score)print(zscore([[1, 2, 3],
[6, 7, 8]], axis=1))输出结果:
[ 1.52573266 0.21648909 -0.63915828 -1.10306348] [[-1.22474487 0. 1.22474487] [-1.22474487 0. 1.22474487]]
(2)训练集、验证集、测试集
一份神经网络数据集,会先分成训练集和测试集,训练集在训练时会再分成训练集和验证集。一般来说训练集、验证集、测试集的比例为70%、20%、10%,它们分别的作用是:
- 训练集:训练神经网络,调整模型权重;
- 验证集:用于评估和优化神经网络,防止训练的神经网络模型过拟合,即训练集的准确率提升,同时验证集的准确率却没有什么变化甚至还出现降低;
- 测试集:用来评估神经网络最终的训练模型,并且测试集数据只会使用一次。
(3)训练周期、批次、批次尺寸
深度学习的数据集一般很大,无法一次将整个训练数据输入神经网络,为了执行效能,会将训练数据分为较小单位,称为批次。每一批的样本数量称为批次尺寸。当整个训练集(分为多个批次)从前向传播至反向传播通过整个神经网络一次,称为一个训练周期。迭代的重复次数是指需要多少个批次来完成一个训练周期。
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!