前言
参考: 《数字图像处理与机器视觉》 第五章 空间域图像增强,
图像卷积: 空间域图像增强
图像增强是根据特定需要突出一副图像中的某些信息,同时削弱或去除
某些不需要信息的处理方法,其主要目的是是的处理后的图像对某种特定的应用来说
比原始图像更适用。因此这类处理时为例某种特殊应用,去改善图像的质量,处理
的结果更适合于人的观察或机器的识别系统
目录
1: 卷积
2: LeNet-5
3: Conv2d
一 卷积
卷积神经网络的核心是卷积层
1.1 卷积定义
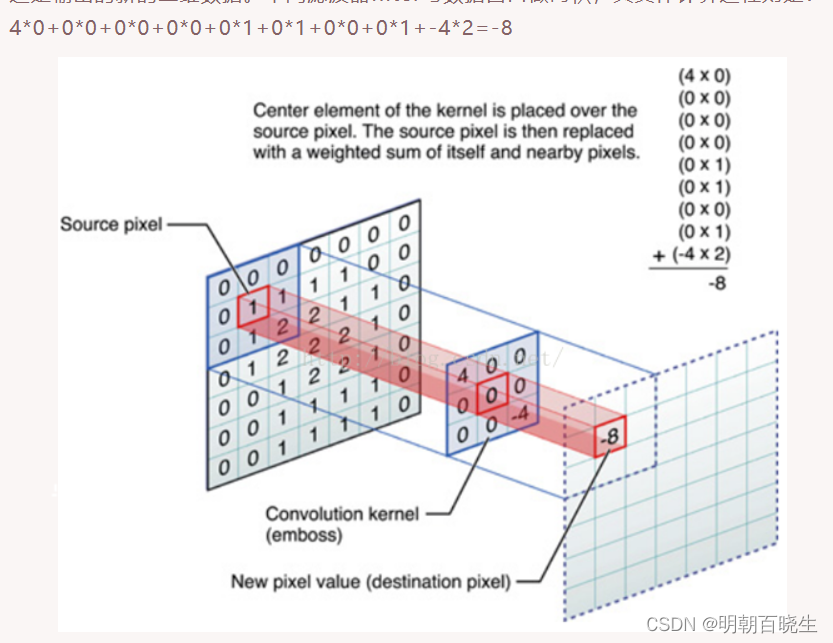
对图像的每一个点(x,y)执行以下操作
1: 对预先定义的以(x,y)为中心点的领域内的像素运算
2: 将1中的运算结果作为(x,y)点新的响应
用数学公式来表示
图像
卷积核
如 下图
1.2 卷积网络中的卷积
在 传统的 数字图像处理里面,卷积核权重系数大小是固定的,
深度学习里面需要预先定义一下,通过训练得到里面权重系数
| kernel channel | 卷积核的个数 |
| kernel size | 卷积核大小 |
| stride | 滑动的步伐,决定滑动多少步可以到图像边缘 |
| padding | 填充系数,填0 或边缘像素的扩展,总长能被步长整除。 |
1.3 input
| N | 图片的个数 |
| channel | 图片的通道,如RGB c=3, 灰度图 c=1 |
| width | 图片的宽度 |
| height | 图片的高度 |
例:

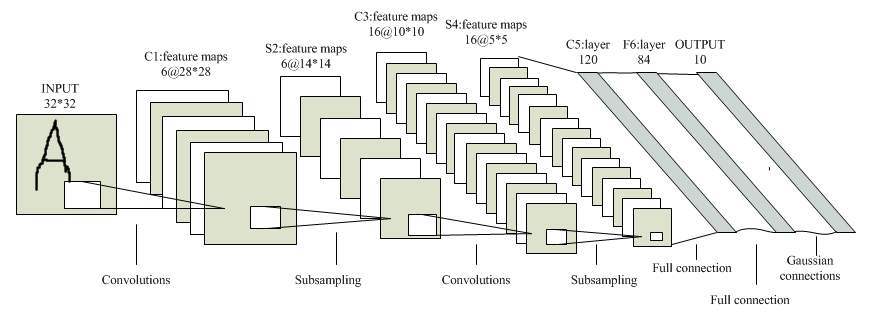
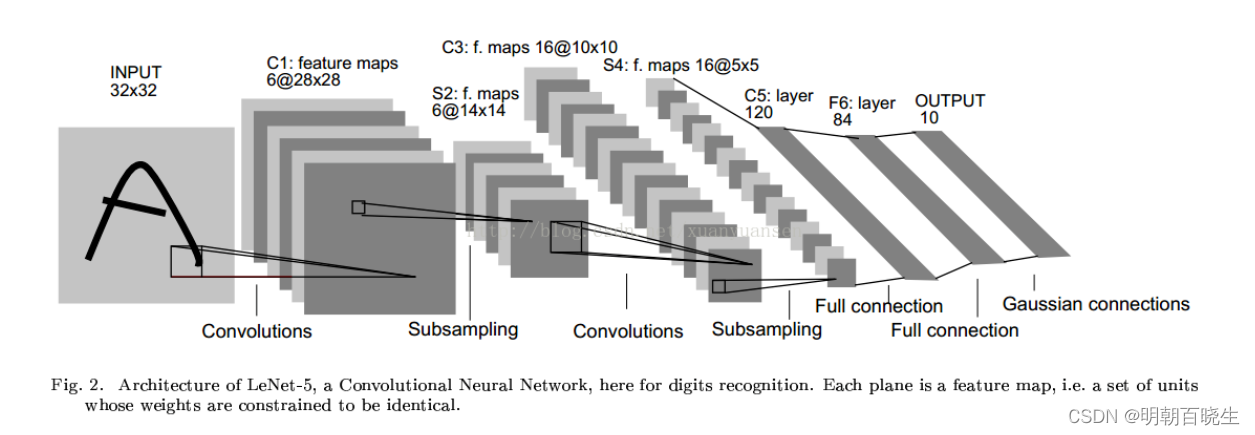
二 LeNet-5
输入
[1,1,28,28]
| 1 | 1 | 28 | 28 |
| 图像个数 | 网络输入的通道数,灰度图=1 | 图像宽 | 图像高 |
LeNet-5 共包含 8 层
C1 卷积层
[6,1,5,5]
| m=6 | channel=1 | width=5 | height=5 |
| 网络输出的通道数: 卷积核个数 | 网络输入的通道数:图像的通道 | 卷积核的宽 | 卷积核的高 |
卷积核的channel 数必须和输入的channel 一致
偏置 bias: 每个卷积核对应一个bias,共6个
输出6张28*28特征图
C1 有 156 个可训练参数(每个滤波器 5x5=25 个 bunit 参数和一个 bias 参数,一共 6 个滤波器,共(5x5+1)x6=156个参数,共 156x(28x28)=122,304个连接。
S2 采样层
有 6 个 14x14 的特征图。特征图中的每个单元与 C1 中相对应特征图的 2x2 邻域相连接。S2层每个单元的 4 个输入相加,乘以一个可训练参数,再加上一个可训练偏置。每个单元的 2x2 感受野并不重叠,因此 S2 中每个特征图的大小是 C1 中特征图大小的 1/4(行和列各 1/2)。
2*2池化层
输出 6个14*14 特征图
S2 层有 12个(6x(1+1)=12)个可训练参数和 5880(14x14 (2 2+1) 6=5880)个连接。
C3 卷积层
卷积核
| m=16 | channel=1 | width=5 | height=5 |
| 输出的通道数 | 输入的通道数 | 卷积核的宽 | 卷积核的高 |
输出 16个10*10的feature map
S4 下采样层
由 16 个 5x5 大小的特征图构成。特征图中的每个单元与 C3 中相应特征图的 2x2 邻域相连接,跟 C1 和 S2 之间的连接一样。S4 层有 32 个可训练参数(每个特征图1个因子和一个偏置16x(1+1)=32)和 2000(16 (2 2+1)x5 x5=2000)个连接。
C5 卷积层
卷积核
| m=120 | channel=1 | width=1 | height=1 |
| 卷积核个数 | 图像的通道 | 卷积核的宽 | 卷积核的高 |
输出 有 120 。由于 S4 层特征图的大小也为 5x5 (同滤波器一样),故 C5 特征图的大小为 1x1(5-5+1=1),这构成了 S4 和 C5 之间的全连接。
F6 全连接层
有 84 个单元(之所以选这个数字的原因来自于输出层的设计)
,与 C5 层全相连。有 10164(84x(120x(1x1)+1)=10164)个可训练参数。如同经典神经网络,F6 层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给 sigmoid 函数产生单元i的一个状态。
最后,输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有 84 个输入。
三 Conv2d函数详解
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: _size_2_t,
stride: _size_2_t = 1,
padding: _size_2_t = 0,
dilation: _size_2_t = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros' # TODO: refine this type
):
| 参数 | 意义 |
| in_channels | 网络输入的通道数,RGB =3 |
| out_channels | 网络输出的通道数, 卷积核的个数 |
| kernel_size | 卷积核的大小 |
| stride | 是卷积过程中移动的步长。默认情况下是1。一般卷积核在输入图像上的移动是自左至右,自上至下 |
| padding | 填充,默认是0填充 |
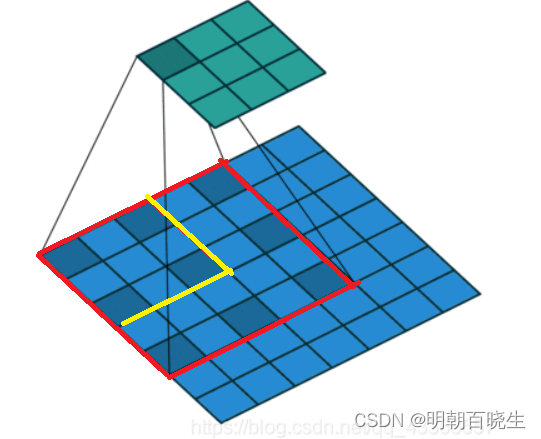
| dilation | dilation:扩张。一般情况下,卷积核与输入图像对应的位置之间的计算是相同尺寸的,也就是说卷积核的大小是3X3,那么它在输入图像上每次作用的区域是3X3,这种情况下dilation=0。当dilation=1时,表示的是下图这种情况 |
| groups | 分组。指的是对输入通道进行分组,如果groups=1,那么输入就一组,输出也为一组。如果groups=2,那么就将输入分为两组,那么相应的输出也是两组。另外需要注意的是in_channels和out_channels必须能整除groups。 |
| bias | 偏置参数,该参数是一个bool类型的,当bias=True时,表示在后向反馈中学习到的参数b被应用 |
| padding_mode | 填充模式, padding_mode=‘zeros’表示的是0填充 |
例
# -*- coding: utf-8 -*-
"""
Created on Mon May 15 15:31:26 2023
@author: chengxf2
"""
import torch
import torch.nn as nn
def main():
img = torch.randn(10,3,28,28)
conv = nn.Conv2d(3,16,4,stride=2,padding=0)
output = conv(img)
print(output.shape)
main()
===============
out: torch.Size([10, 16, 13, 13])输入:
10张RGB 图片,图片大小28*28
[10,3,28,28]
卷积核
[16,3,4,4]
输出
输出图像的宽度,高度利用下面的公式
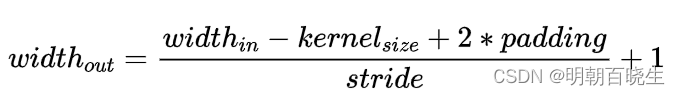
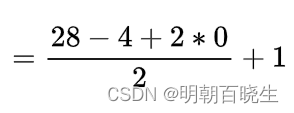
= 13
torch 里面通过F 函数提供另一种,更加直接的方式定义了 卷积核的shape
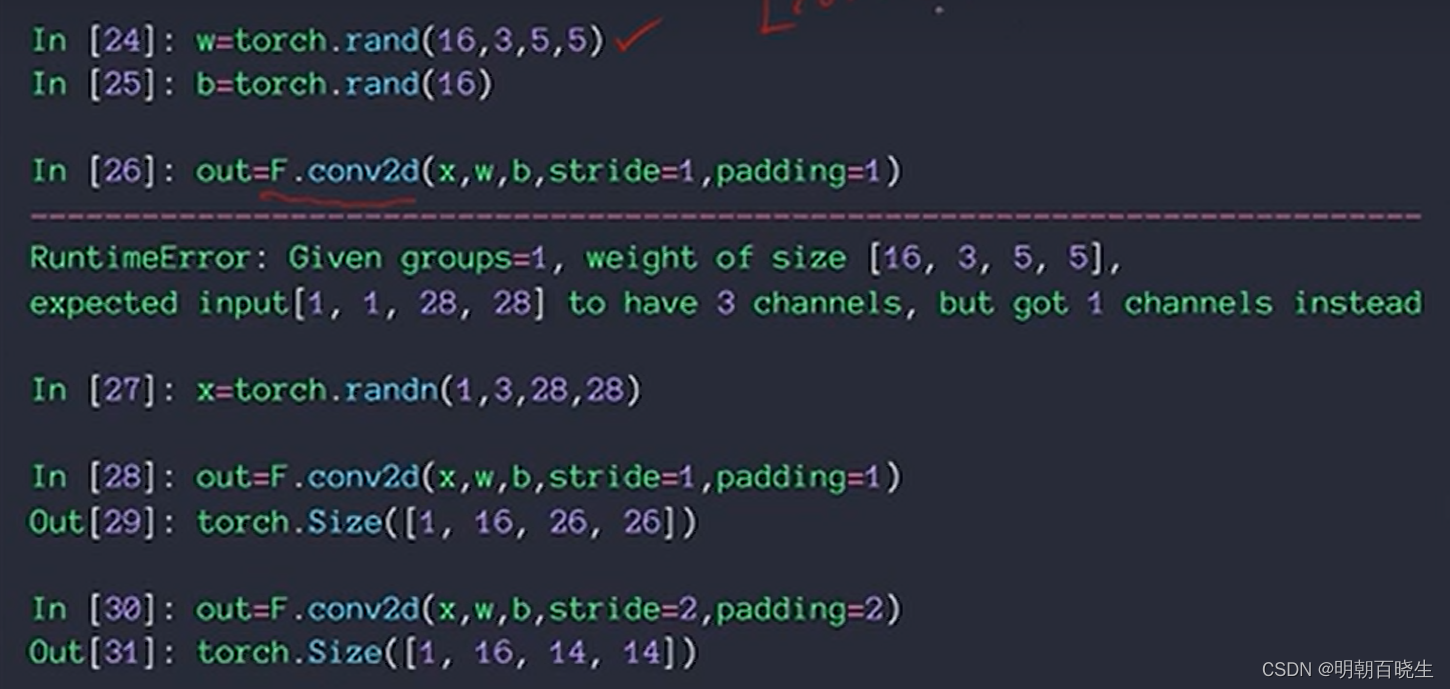
参考:
卷积神经网络简介
卷积神经网络基础知识
CNN中的stride、kernel、padding计算 - 知乎
https://blog.csdn.net/jiaoyangwm/article/details/80011656/
Conv2d函数详解(Pytorch)_phil__naiping的博客-CSDN博客