《百面机器学习》学习笔记:基于梯度提升决策树的组合特征方法
- 基于梯度提升决策树的组合特征方法
- 梯度提升决策树
- 这里举一个例子来说明梯度提升决策树的思想方法
- 假设对于某种类型的输入,经过上述介绍的梯度提升决策树构建流程得到的模型如下图所示
基于梯度提升决策树的组合特征方法
梯度提升决策树
梯度提升决策树(Gradient Boosting Decision Trees)是一种集成学习方法,它通过逐步迭代地训练决策树模型来提高预测性能。该方法的原理可以分为两个主要部分:梯度提升和决策树。
梯度提升(Gradient Boosting)
梯度提升是一种迭代的优化过程,通过逐步优化模型的损失函数来提高模型的预测能力。它基于前一轮迭代的模型的预测结果和真实标签之间的残差(即差异),来训练下一轮迭代的模型。具体步骤如下:
a. 首先,使用一个初始的弱模型(如决策树)作为基础模型进行预测。
b. 计算基础模型的预测结果与真实标签之间的残差。
c. 使用这些残差作为目标值,训练下一个弱模型,以尝试减少这些残差。
d. 将当前模型的预测结果与新模型的预测结果相加,形成一个新的预测结果。
e. 重复步骤b-d,直到达到预先定义的迭代次数或损失函数收敛。
决策树(Decision Trees)
决策树是一种基本的机器学习模型,它通过一系列的决策规则对数据进行分类或回归。在梯度提升中,决策树被用作弱模型,也称为弱学习器。每一轮迭代中,都会训练一个新的决策树来捕捉之前模型预测的残差。决策树的生成过程如下:
a. 首先,选择一个特征和切分点,将数据集划分为两个子集。
b. 使用某种准则(如最小化基尼指数或最小化均方差)来确定最佳的特征和切分点。
c. 递归地重复步骤a-b,直到达到预定义的停止条件(如达到最大深度或节点中的样本数量小于某个阈值)。
d. 每个叶节点上的值为该叶节点中样本的平均值(对于回归问题)或多数类别(对于分类问题)。
梯度提升决策树通过反复迭代上述两个步骤,每一轮迭代都试图减少前一轮模型的残差,从而提高整体模型的预测性能。在每一轮迭代中,新的决策树被训练来捕捉前一轮模型预测的残差,然后将其加入到模型中,形成一个更强大的集成模型。
最终的模型是所有迭代过程中生成的决策树的加权和,其中每棵树的权重取决于其在迭代过程中的性能表现。在预测阶段,新样本通过依次经过所有决策树,并将它们的预测结果相加,得到最终的预测值。
这里举一个例子来说明梯度提升决策树的思想方法
假设任务为使用现有的训练数据集来拟合一个模型,使其具有根据房屋面积来预测房屋价格的能力。
给出训练数据如下:
| 房屋面积 | 价格(标签) |
|---|---|
| 1000 | 550000 |
| 1500 | 650000 |
| 2000 | 720000 |
| 2500 | 820000 |
| 3000 | 900000 |
在初始阶段,首先选定一个基本的弱模型,这里选择决策树模型作为基础模型。然后使用上述5组数据的价格平均数作为初始的模型预测值,那么初始的预测值如下表所示:
| 房屋面积(特征) | 价格(标签) | 初始预测价格 |
|---|---|---|
| 1000 | 550000 | 704000 |
| 1500 | 650000 | 704000 |
| 2000 | 720000 | 704000 |
| 2500 | 820000 | 704000 |
| 3000 | 900000 | 704000 |
然后,使用当前模型的预测结果与真实标签之间的残差,即实际价格和预测价格之间的差值。然后,这些残差将成为下一轮模型迭代的目标值。
| 房屋面积(特征) | 价格(标签) | 初始预测价格 | 残差 |
|---|---|---|---|
| 1000 | 550000 | 704000 | -154000 |
| 1500 | 650000 | 704000 | -54000 |
| 2000 | 720000 | 704000 | 16000 |
| 2500 | 820000 | 704000 | 116000 |
| 3000 | 900000 | 704000 | 196000 |
接着,使用上述表格中的残差作为目标值,训练一个新的决策树来捕捉这些残差的模式。新的决策树将尝试减少上一轮模型的残差。
当新的决策树训练完成之后,可以将其预测结果与之前的预测结果相加,得到一个新的预测结果如下表所示。
| 房屋面积(特征) | 价格(标签) | 初始预测价格 | 残差 | 新预测价格 |
|---|---|---|---|---|
| 1000 | 550000 | 704000 | -154000 | 550000 |
| 1500 | 650000 | 704000 | -54000 | 596000 |
| 2000 | 720000 | 704000 | 16000 | 720000 |
| 2500 | 820000 | 704000 | 116000 | 820000 |
| 3000 | 900000 | 704000 | 196000 | 900000 |
然后,继续计算新预测价格与真实标签之间的残差,再次作为目标值。
| 房屋面积(特征) | 价格(标签) | 初始预测价格 | 残差 | 新预测价格 | 新残差 |
|---|---|---|---|---|---|
| 1000 | 550000 | 704000 | -154000 | 550000 | 0 |
| 1500 | 650000 | 704000 | -54000 | 596000 | 54000 |
| 2000 | 720000 | 704000 | 16000 | 720000 | 0 |
| 2500 | 820000 | 704000 | 116000 | 820000 | 0 |
| 3000 | 900000 | 704000 | 196000 | 900000 | 0 |
然后进行下一轮的迭代,训练另外一个决策树来捕捉新残差的模式,并将其预测结果与之前的预测结果相加。
不断重复上述过程,每一轮迭代都试图减少前一轮模型的残差,直到达到预先定义的迭代次数或损失函数收敛。
最终得到的模型为所有迭代中生成的决策树模型的加权和,其中每棵树的权重取决于其在迭代过程中的性能表现。
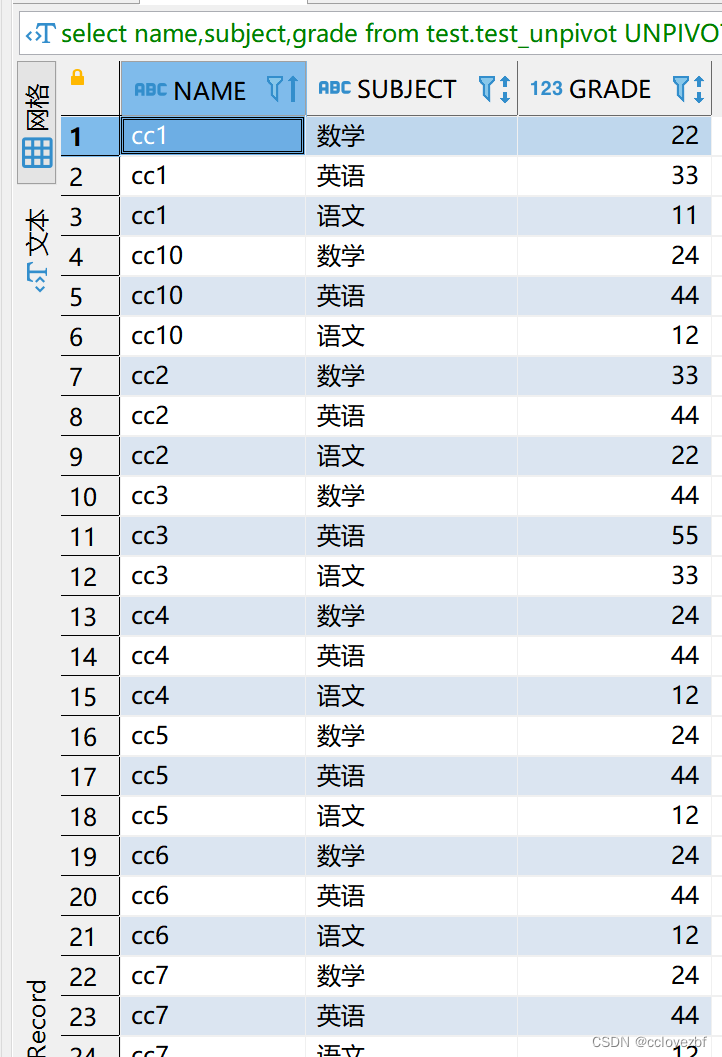
假设对于某种类型的输入,经过上述介绍的梯度提升决策树构建流程得到的模型如下图所示

上图引自《百面机器学习》,图中为典型决策树。其中,共有四种特征组合方式:
(1)用户类型=付费用户+年龄
≤
\leq
≤ 40;
(2)用户类型=付费用户+物品类型=食品;
(3)年龄
≤
\leq
≤ 35+物品类型=护肤;
(4)年龄
≤
\leq
≤ 35+性别=女;
现在给出两个样本,分别如下:
| 是否点击 | 年龄 | 性别 | 用户类型 | 物品类型 |
|---|---|---|---|---|
| 是 | 28 | 女 | 免费 | 护肤 |
| 否 | 36 | 男 | 付费 | 食品 |
那么按照上述四种特征组合方式来说,上表中第一个样本可以编码为(0,0,1,1),因为该样本只满足(3)(4)组合特征,但并不满足(1)(2)组合特征;同理,对于上表中的第二个样本可以编码为(1,1,0,0),因为该样本同时满足(1)(2)组合特征,但不满足(3)(4)组合特征。