目录
1. 为什么要⽤ ThreadLocal?
2. ThreadLocal 的原理是什么?
3. 为什么⽤ ThreadLocal 做 key?
4. Entry 的 key 为什么设计成弱引⽤?
5. ThreadLocal 真的会导致内存泄露?
6. 如何解决内存泄露问题?
7. ThreadLocal 是如何定位数据的?
8. ThreadLocal 是如何扩容的?
9. ⽗⼦线程如何共享数据?
10. 线程池中如何共享数据?
11. ThreadLocal 有哪些⽤途?
1. 为什么要⽤ ThreadLocal?
答:为了解决并发编程时,公共资源数据安全问题。(也可使⽤锁的⽅式)
2. ThreadLocal 的原理是什么?
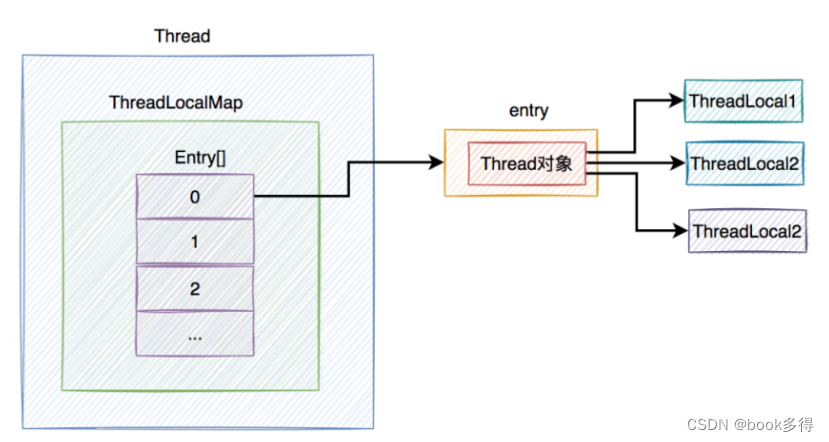
答:在每个 Thread 类中,都有⼀个 ThreadLocalMap 的成员变量,该变量包含了⼀个 Entry 数 组 ,该数组真正保存了 ThreadLocal 类 set 的数据。
public class ThreadLocal<T> {
。。。
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的成员变量ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
//根据threadLocal对象从map中获取Entry对象
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
//获取保存的数据
T result = (T) e.value;
return result;
}
}
//初始化数据
return setInitialValue();
}
private T setInitialValue() {
//获取要初始化的数据
T value = initialValue();
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的成员变量ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
//如果map不为空
if (map != null)
//将初始值设置到map中,key是this,即threadLocal对象,value是初始值
map.set(this, value);
else
//如果map为空,则需要创建新的map对象
createMap(t, value);
return value;
}
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的成员变量ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
//如果map不为空
if (map != null)
//将值设置到map中,key是this,即threadLocal对象,value是传⼊的value
map.set(this, value);
else
//如果map为空,则需要创建新的map对象
createMap(t, value);
}
static class ThreadLocalMap {
...
}
...
}static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
...
private Entry[] table;
...
}public class Thread implements Runnable {
...
ThreadLocal.ThreadLocalMap threadLocals = null;
}
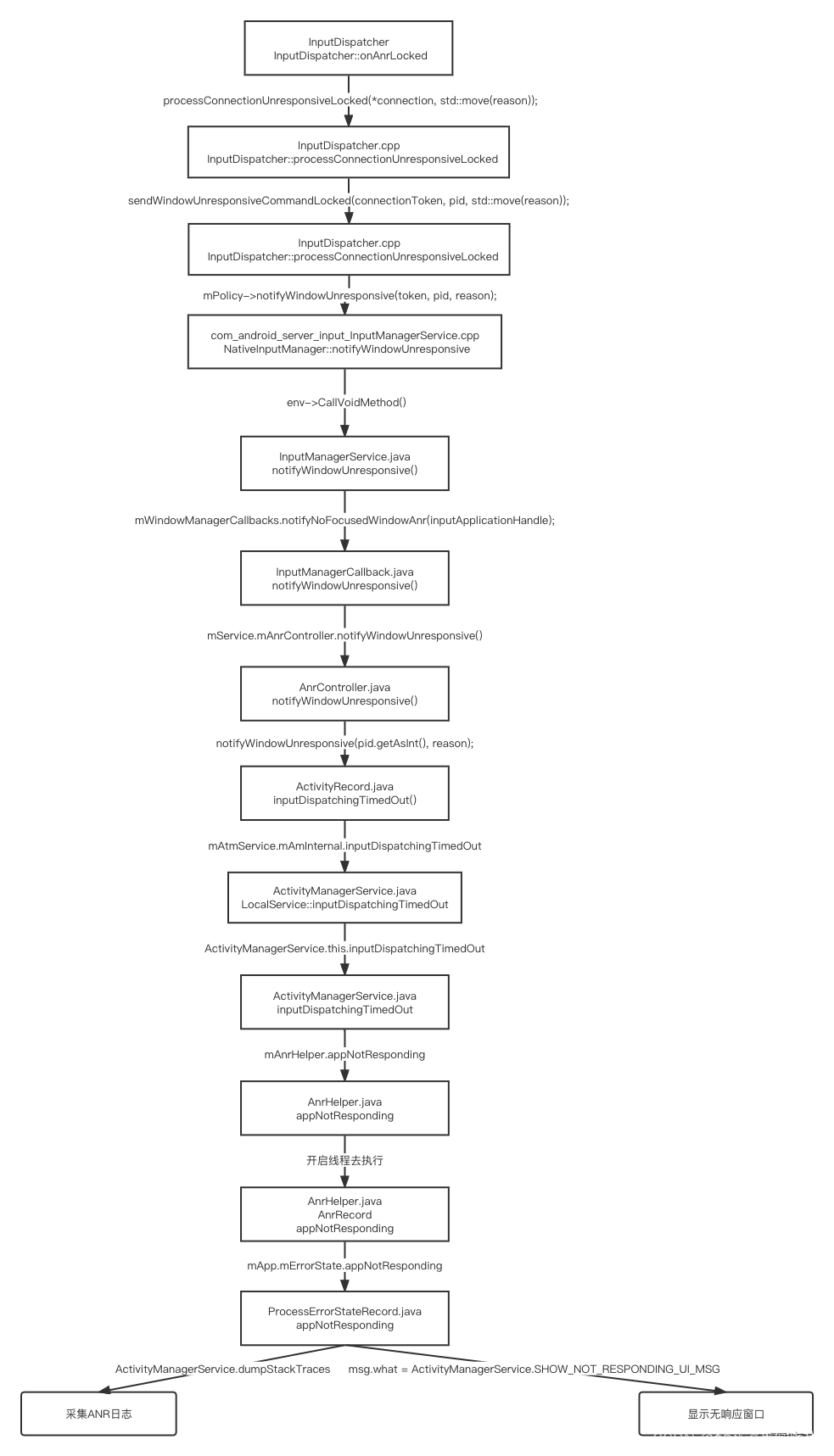
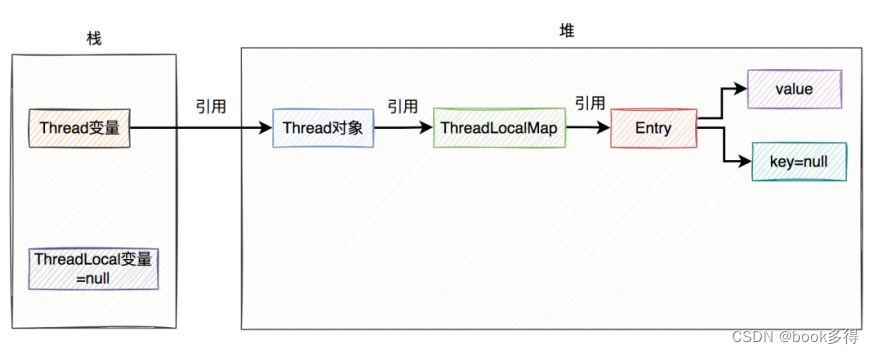
从上图中看出,在每个 Thread 类中,都有⼀个 ThreadLocalMap 的成员变量,该变量包含了⼀个 Entry 数组 ,该数组真正保存了 ThreadLocal 类 set 的数据。

上图中除了 Entry 的 key 对 ThreadLocal 对象是 弱引⽤ ,其他的引⽤都是强引⽤ 。
3. 为什么⽤ ThreadLocal 做 key?
答: 如果使⽤线程当key,创建多个ThreadLocal的时, 线程不唯⼀,值会被覆盖。
public class ThreadLocalService {
private static final ThreadLocal<Integer> threadLocal1 = new ThreadLoca
l<>();
private static final ThreadLocal<Integer> threadLocal2 = new ThreadLoca
l<>();
private static final ThreadLocal<Integer> threadLocal3 = new ThreadLoca
l<>();
}
4. Entry 的 key 为什么设计成弱引⽤?
答: 如果使⽤了线程池,线程池⾥的核⼼线程是⼀直存在的,线程⾥的ThreadLocalMap也会⼀直存在,如果使⽤了弱引⽤,当 ThreadLocal 变量指向 null 之后,在 GC 做垃圾清理的时候,key 会被⾃ 动回收,其值也被设置成 null。

弱引⽤的对象,在 GC 做垃圾清理的时候,就会被⾃动回收了

接下来,最关键的地⽅来了。

- key 为 null 的条件是,ThreadLocal 变量指向 null ,并且 key 是弱引⽤。如果 ThreadLocal 变量没有断开对 ThreadLocal 的强引⽤,即 ThreadLocal 变量没有指向 null,GC 就贸然的把弱引⽤的 key 回收了,不就会影响正常⽤户的使⽤?
- 如果当前 ThreadLocal 变量指向 null 了,并且 key 也为 null 了,⾃身肯定是不能够触发remove 了,但如果没有其他 ThreadLocal 变量触发 get 、 set 或 remove ⽅法,也会造成内存泄露。
public static void main(String[] args) {
WeakReference<Object> weakReference0 = new WeakReference<>(new Object()
);
System.out.println(weakReference0.get());
System.gc();
System.out.println(weakReference0.get());
}java.lang.Object@1ef7fe8e
nullpublic static void main(String[] args) {
Object object = new Object();
WeakReference<Object> weakReference1 = new WeakReference<>(object);
System.out.println(weakReference1.get());
System.gc();
System.out.println(weakReference1.get());
}java.lang.Object@1ef7fe8e
java.lang.Object@1ef7fe8epublic static void main(String[] args) {
Object object = new Object();
WeakReference<Object> weakReference1 = new WeakReference<>(object);
System.out.println(weakReference1.get());
System.gc();
System.out.println(weakReference1.get());
object=null;
System.gc();
System.out.println(weakReference1.get());
}java.lang.Object@6f496d9f
java.lang.Object@6f496d9f
null由此可⻅,如果强引⽤和弱引⽤同时关联⼀个对象,那么这个对象是不会被 GC 回收。也就是说这种情况下 Entry 的 key,⼀直都不会为 null,除⾮强引⽤主动断开关联。
此外,你可能还会问这样⼀个问题:Entry 的 value 为什么不设计成弱引⽤?
答:Entry 的 value 假如只是被 Entry 引⽤,有可能没被业务系统中的其他地⽅引⽤。如果将 value 改成了弱引⽤,被 GC 贸然回收了(数据突然没了),可能会导致业务系统出现异常。
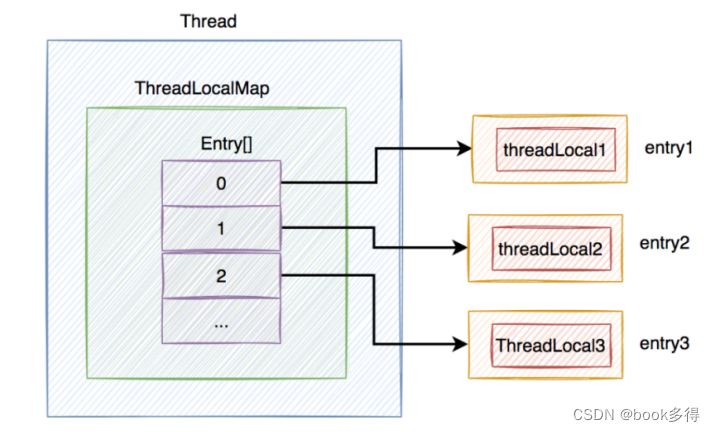
5. ThreadLocal 真的会导致内存泄露?
答:会,假如 ThreadLocalMap 中存在很多 key 为 null 的 Entry,但后⾯的程序,⼀直都没有调⽤过有效的 ThreadLocal 的 get 、 set 或 remove ⽅法。Entry 的 value 值⼀直都没被清空。就有可 能导致内存泄漏。
如下图所示:
6. 如何解决内存泄露问题?
答:在finally块调⽤ remove ⽅法。
不是在⼀开始就调⽤ remove ⽅法,⽽是在使⽤完 ThreadLocal 对象之后。列如:
先创建⼀个 CurrentUser 类,其中包含了 ThreadLocal 的逻辑。
public class CurrentUser {
private static final ThreadLocal<UserInfo> THREA_LOCAL = new ThreadLoc
al();
public static void set(UserInfo userInfo) {
THREA_LOCAL.set(userInfo);
}
public static UserInfo get() {
THREA_LOCAL.get();
}
public static void remove() {
THREA_LOCAL.remove();
}
}public void doSamething(UserDto userDto) {
UserInfo userInfo = convert(userDto);
try{
CurrentUser.set(userInfo);
...
//业务代码
UserInfo userInfo = CurrentUser.get();
...
} finally {
CurrentUser.remove();
}
}7. ThreadLocal 是如何定位数据的?
答:Hash算法。。。。。。blablabla
在 ThreadLocal 的 get、set、remove ⽅法中都有这样⼀⾏代码:
int i = key.threadLocalHashCode & (len-1); 1假设 len=16,key.threadLocalHashCode=31于是: int i = 31 & 15 = 15相当于:int i = 31 % 16 = 15
计算的结果是⼀样的,但是使⽤ 与运算 效率跟⾼⼀些。
延伸题:为什么与运算效率更⾼?
答:因为 ThreadLocal 的初始⼤⼩是 16 ,每次都是按 2 倍扩容,数组的⼤⼩其实⼀直都是 2 的 n 次⽅。这种数据有个规律就是⾼位是 0,低位都是 1。在做与运算时,可以不⽤考虑⾼位,因为与运算的结果 必定是0。只需考虑低位的与运算,所以效率更⾼。
延伸题:ThreadLocal 是如何解决 hash 冲突的呢?
private Entry getEntry(ThreadLocal<?> key) {
//通过hash算法获取下标值
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
//如果下标位置上的key正好是我们所需要寻找的key
if (e != null && e.get() == key)
//说明找到数据了,直接返回
return e;
else
//说明出现hash冲突了,继续往后找
return getEntryAfterMiss(key, i, e);
}private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
//判断Entry对象如果不为空,则⼀直循环
while (e != null) {
ThreadLocal<?> k = e.get();
//如果当前Entry的key正好是我们所需要寻找的key
if (k == key)
//说明这次真的找到数据了
return e;
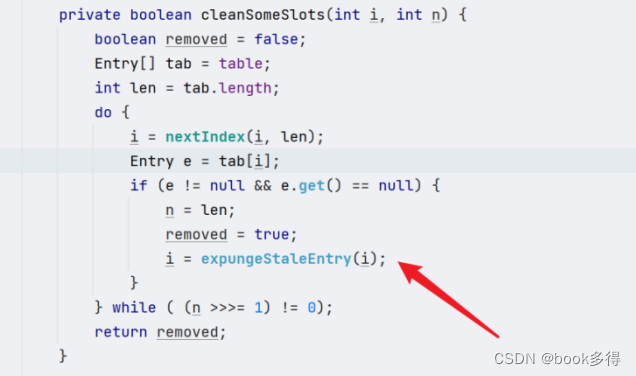
if (k == null)
//如果key为空,则清理脏数据
expungeStaleEntry(i);
else
//如果还是没找到数据,则继续往后找
i = nextIndex(i, len);
e = tab[i];
}
return null;
}private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}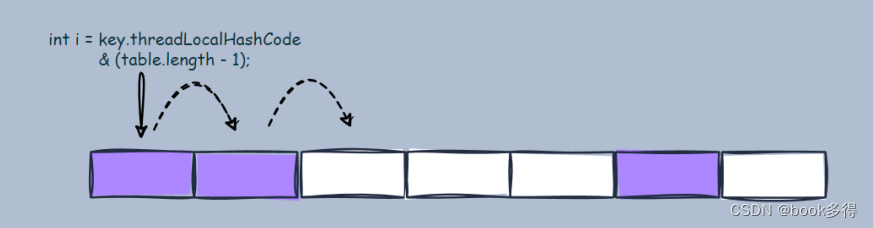
ThreadLocal 从数组中找数据的过程⼤致是这样的:
- 通过 key 的 hashCode 取余计算出⼀个下标。
- 通过下标,在数组中定位具体 Entry,如果 key 正好是我们所需要的 key,说明找到了,则直接返回数据。
- 如果第 2 步没有找到我们想要的数据,则从数组的下标位置,继续往后⾯找。
- 如果第 3 步中找 key 的正好是我们所需要的 key,说明找到了,则直接返回数据。
- 如果还是没有找到数据,再继续往后⾯找。如果找到最后⼀个位置,还是没有找到数据,则再从头,即下标为 0 的位置,继续从前往后找数据。
- 直到找到第⼀个 Entry 为空为⽌。
以上就是⾮常典型的开放地址法(Open Addressing)解决哈希冲突。
常⻅有哪些⽅法解决哈希冲突呢?1. 开放地址法(Open Addressing)解决哈希冲突:将哈希桶本身作为存储单元,当某个桶被占⽤时,往后依次查找空桶,直到找到⼀个空桶为⽌。开放地址法的实现较为复杂,需要考虑探测序列 的选取和删除操作的影响,但是可以节省额外的存储空间。1.1. 线性探测(Linear Probing):当哈希冲突发⽣时,按照⼀定步⻓(通常为 1)依次往后查找 下⼀个空槽位,直到找到为⽌。1.2. ⼆次探测(Quadratic Probing):当哈希冲突发⽣时,按照⼀定步⻓的平⽅(1,4,9, 16,...)依次往后查找下⼀个空槽位,直到找到为⽌。1.3. 随机探测(Random Probing):当哈希冲突发⽣时,按照⼀个随机步⻓(通常为⼀个随机 数)依次往后查找下⼀个空槽位,直到找到为⽌。2. 链地址法( Separate Chaining):将每个哈希桶设计为⼀个链表或者其他的数据结构,当发⽣哈 希冲突时,将新的键值对插⼊到该桶对应的链表中。这种⽅法实现简单,适⽤于各种数据类型和负 载因⼦,但是需要额外的存储空间。3. 再哈希法、双重散列(Double Hashing):当发⽣哈希冲突时,使⽤另⼀个哈希函数重新计算哈希值,直到找到⼀个空桶为⽌。这种⽅法可以避免探测序列的形成,但是需要选取不同的哈希函 数。4. 公共溢出区(Overflow Area):将哈希表分为主区和溢出区,当主区某个位置发⽣哈希冲突时,将该键值对插⼊到溢出区中。这种⽅法的实现较为简单,但是查找效率会降低。
8. ThreadLocal 是如何扩容的?
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}private void setThreshold(int len) {
threshold = len * 2 / 3;
}private void rehash() {
//先尝试回收⼀次key为null的值,腾出⼀些空间
expungeStaleEntries();
if (size >= threshold - threshold / 4)
resize();
}16 * 2 * 4 / 3 * 4 - 16 * 2 / 3 * 4 = 8
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
//按2倍的⼤⼩扩容
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}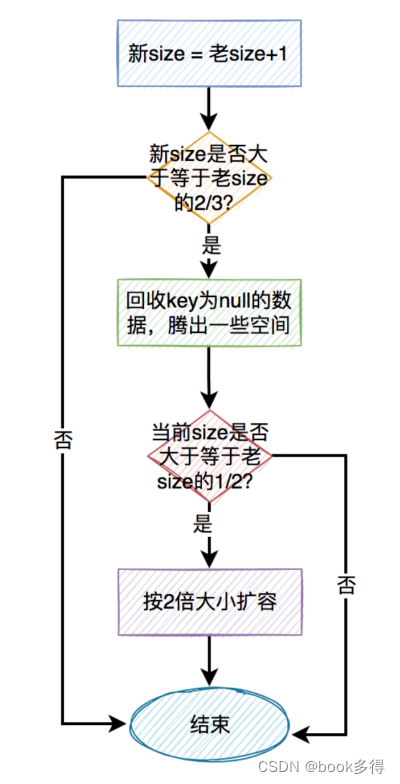
扩容的关键步骤如下:
- ⽼ size + 1 = 新 size
- 如果新 size ⼤于等于⽼ size 的 2/3 时,需要考虑扩容。
- 扩容前先尝试回收⼀次 key 为 null 的值,腾出⼀些空间。
- 如果回收之后发现 size 还是⼤于等于⽼ size 的 1/2 时,才需要真正的扩容。
- 每次都是按 2 倍的⼤⼩扩容。
9. ⽗⼦线程如何共享数据?
public class ThreadLocalTest {
public static void main(String[] args) {
ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
threadLocal.set(6);
System.out.println("⽗线程获取数据:" + threadLocal.get());
new Thread(() -> {
System.out.println("⼦线程获取数据:" + threadLocal.get());
}).start();
}
}⽗线程获取数据:6
⼦线程获取数据:null答:使⽤ InheritableThreadLocal ,它是 JDK ⾃带的类,继承了 ThreadLocal 类。
修改代码之后:
public class ThreadLocalTest {
public static void main(String[] args) {
InheritableThreadLocal<Integer> threadLocal = new InheritableThrea
dLocal<>();
threadLocal.set(6);
System.out.println("⽗线程获取数据:" + threadLocal.get());
new Thread(() -> {
System.out.println("⼦线程获取数据:" + threadLocal.get());
}).start();
}
}执⾏结果:
⽗线程获取数据:6
⼦线程获取数据:6
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;10. 线程池中如何共享数据?
private static void fun1() {
InheritableThreadLocal<Integer> threadLocal = new InheritableThreadLoc
al<>();
threadLocal.set(6);
System.out.println("⽗线程获取数据:" + threadLocal.get());
ExecutorService executorService = Executors.newSingleThreadExecutor();
threadLocal.set(6);
executorService.submit(() -> {
System.out.println("第⼀次从线程池中获取数据:" + threadLocal.get());
});
threadLocal.set(7);
executorService.submit(() -> {
System.out.println("第⼆次从线程池中获取数据:" + threadLocal.get());
});
}⽗线程获取数据:6
第⼀次从线程池中获取数据:6
第⼆次从线程池中获取数据:6答:使⽤TransmittableThreadLocal ,它并⾮ JDK ⾃带的类,⽽是阿⾥巴巴开源 jar 包中的类。
通过如下 pom ⽂件引⼊该 jar 包:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.11.0</version>
<scope>compile</scope>
</dependency>private static void fun2() throws Exception {
TransmittableThreadLocal<Integer> threadLocal = new TransmittableThrea
dLocal<>();
threadLocal.set(6);
System.out.println("⽗线程获取数据:" + threadLocal.get());
ExecutorService ttlExecutorService = TtlExecutors.getTtlExecutorServic
e(Executors.newFixedThreadPool(1));
threadLocal.set(6);
ttlExecutorService.submit(() -> {
System.out.println("第⼀次从线程池中获取数据:" + threadLocal.get());
});
threadLocal.set(7);
ttlExecutorService.submit(() -> {
System.out.println("第⼆次从线程池中获取数据:" + threadLocal.get());
});
}⽗线程获取数据:6
第⼀次从线程池中获取数据:6
第⼆次从线程池中获取数据:7以 TtlRunnable 类为例,它实现了 Runnable 接⼝,同时还实现了它的 run ⽅法:
public void run() {
Map<TransmittableThreadLocal<?>, Object> copied = (Map)this.copiedRef.
get();
if (copied != null && (!this.releaseTtlValueReferenceAfterRun || this.
copiedRef.compareAndSet(copied, (Object)null))) {
Map backup = TransmittableThreadLocal.backupAndSetToCopied(copied)
;
try {
this.runnable.run();
} finally {
TransmittableThreadLocal.restoreBackup(backup);
}
} else {
throw new IllegalStateException("TTL value reference is released a
fter run!");
}
}- 把当时的 ThreadLocal 做个备份,然后将⽗类的 ThreadLocal 拷⻉过来。
- 执⾏真正的 run ⽅法,可以获取到⽗类最新的 ThreadLocal 数据。
- 从备份的数据中,恢复当时的 ThreadLocal 数据。
11. ThreadLocal 有哪些⽤途?
下⾯列举⼏个常⻅的场景:
- 在 spring 事务中,保证⼀个线程下,⼀个事务的多个操作拿到的是⼀个 Connection。
- 在 hiberate 中管理 session。
- 在 JDK8 之前,为了解决 SimpleDateFormat 的线程安全问题。
- 获取当前登录⽤户上下⽂。
- 临时保存权限数据。
- 使⽤ MDC(⽇志追踪traceId) 保存⽇志信息。