目录
MySQL概述
MySQL初期概念
小结
主流数据库
连接服务器
服务器,数据库,表关系
数据逻辑存储
MySQL架构
SQL分类
存储引擎
存储引擎
查看存储引擎
MySQL概述
#问:什么是数据库?
MySQL初期概念

这个所谓的mysql严格意义上来讲并不是数据库,他是数据库的客户端。mysqld叫做mysql的服务端,mysql其实是一套网络服务。
因为mysql是一个服务:

状态Llisten的,可以认识到原来mysqld服务端就是一个网络服务器。因为mysqld是一个网络服务器,所以就注定了其采用的是TCP协议,在引用层。所以mysqld的本质和以前网络学习中的http / https / 网络版本计算器,任何的应用层软件本质没有差别,mysqld就是一个应用层服务,在网络的角度,mysqld就是一个应用层服务,在系统视角,它就是用户层的一个进程,这就是mysql后端服务。
- mysql
不是数据库,他是MySQL的客户端。
- mysqld
严格意义上来讲其叫数据库,但是准确上叫其数据库服务 - 数据库服务端,其实是一个应用程序,启动之后变成进程。特殊说明下(有没有将数据库起来?)其可以叫数据库 - 狭义。
- 数据存储
特殊说明下(不做任何特殊说明 / 有没有建数据库?)的数据库是:

以特定的格式保存好的文件,我们叫做数据库 - 狭义。
广义上:
三者合起来,提供较为便捷的数据的存取服务的软件集合,解决方案 - MySQL数据库。
#问:存储数据用文件就可以了,为什么还要弄个数据库?
有一个文件,文件里有一万个IP地址。这个IP地址,每一个IP地址开头都可能不一样,而这些IP地址有一个需求:对这一万个IP地址中,120开头的IP全部改成119,并且统计一下最终一共有多少个IP被改了。如果当我们听到这个话的时候,我们如果用文件的方案来存,首先这一万个数据当然可以存,数据库也可以存。所以我们首先要有一个共识,就是文件或者数据库,其实都可以进行数据的存储。
- 如果用文件:
我们将文件打开之后,然后按行进行读取,读取之后。紧接着把对应的这一行的字符串进行确认,如果是120开头的IP地址,就利用字符串替换,将120替换为199,即处理完一行,然后搞一个计数器,利用计数器计数并周而复始的进行确认、替换 - 数据内容的管理工作,需要程序员自己做。
- 如果用数据库:
不用读文件、打开文件,不用按行读取,根本不用关心。只需要直接根据SQL语句,告诉数据库需要查什么、改什么,然后就利用两条SQL,就可以按照我们的需求,把我们的数据都给处理掉了。
数据库本质:是对文件的内容提供基本的内容操作,不用程序员(用户)手动的进行数据管理。
也就是说程序员(用户)对磁盘中的文件(如:IP文件),进行直接的操作,问题就是成本太高(其他问题:效率太低、安全性差)。而现在变为,直接在程序员(用户)与磁盘文件之间,加了一层软件层(mysqld),于是用户不用直接访问文件了,而是交给mysqld,mysqld再去帮我们访问对应的文件列表 - 用户使用sql语句对内容的操作。
所以,拥有MySQL的原因:MySQL是一层软件层,能够对我们所对应的文件进行控制(数据管理)。
融汇贯通的理解:
计算机中的哲学:如果我们现在面临着一个软件问题,那么最简单的做法就是在两个软件层之间添加一层软件层,就可以解决软件问题。
小结
文件保存数据有以下几个缺点:
- 文件的安全性问题 - 误操作删数据、回文、撤销……
- 文件不利于数据查询、管理和海量数据的存储 - 需要极优的程序和算法
- 文件在程序中控制不方便 - 如:查找还需要自行遍历
- 磁盘 - 为主
- 内存 - 为辅
为了解决上述问题,专家们设计出更加利于管理数据内容的东西 -- 数据库,它能更有效的管理数据,数据库的水平是衡量一个程序员水平的重要指标。
一句话:
数据库它是数据库专家统一给我们编写的一套数据库服务,这个数据库服务以mysqld的形式呈现,最终在磁盘上会有大量的文件来保存数据库,并且把服务端 + 一大堆的数据 = 统称为数据库。
主流数据库
- SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
- Oracle: 甲骨文产品,银行用的多,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
- MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
- PostgreSQL:加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。
- SQLite:是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的(或单机应用使用),而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
- H2:是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
连接服务器
- 输入:
mysql -h 127 .0.0.1 -P 3306 -u root -p
-h:指定主机,后面跟的就是IP地址 - 127.0.0.1 本地环回
-P:指明连接的MYSQL对应的端口号 - 默认3306(如果想修改端口号,在配置文件内直接加上port=62344(想修改的端口号),注意:记住重启)。
上述可以省略,默认不指明IP和不指明端口,默认就是本地 + 3306。
-u:表示登陆的时候想以哪一个用户登陆。
-p:后面可以直接跟密码(但是这样就将密码明文了,所以不好)。
通过 -h 和 -P 更加的可以强调一点,MySQL是一套网络服务。
- 输出:

服务器,数据库,表关系

MySQL是一个关系型数据库,所谓的关系型数据库就是它的数据库当中的数据,行列之间,表跟表之间是有莫大的关系的。
#问:创建一个数据库本质在Linux下是做什么?
show databases显示当前的数据库所支持的数据库列表,因为当前是root,所以数据库里的所有数据库都可以看到。

(MySQL中的命令一定要最后接 ' ;' 号)
在MySQL中,建立一个数据库 create database XXX 。


本质是在Linux下建立了一个空目录!

(db.opt先忽略后面再说)
不要觉得建数据库很神秘,数据库是介于操作系统和磁盘之间的一种应用层软件,所以其是在我们创建数据库的时候,其实是帮我们在特定的路径当中创建了一个目录 -- 这个目录就叫做数据库。
我们查看数据库列表所对应的操作mysql -- 是客户端。所以其实本质是我们把我们的客户端构建了一个SQL,这个SQL语句通过网络 / 本地进程间通讯,交给服务端进程mysqld,服务端进程收到了这个对应的SQL指令,然后在它的进程内部一定有对应的系统调用,帮我们创建了目录 -- 这就叫做数据库。
#问:建表本质在Linux上是在做什么?
如果想建一个表,一定是要在某一个数据库里面建表,那就需要先进入这个数据库。所谓的进入数据库,用数据库语言就是:use 数据库;
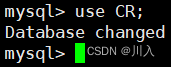
确认当前已经使用这个数据库:select database();。

果然,现在就在CR这个数据库里了 -- 这是数据库的观念。
说简单一点,在Linux中可以认为其实就是cd到了这个目录里面去了 -- mysqld进入了。
然后再建表:
输入:(不用管,看现象即可)

建好之后,确认是否建表成功:

在Linux中可以看到:
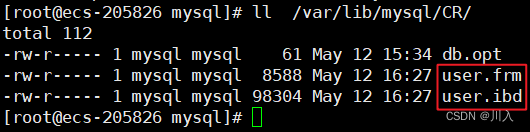
可以发现其实我们所谓的建表的行为,最终在数据库里其会对应上一些文件(几个文件不重要,不同的存储引擎,所对应的文件是有差别的)。最重要的是,我们知道了原来创建一个表本质就是在Linux当中创建一个 / 多个文件 -- 一个数据库里面创建对应的表,对应的Linux语言就是:在一个目录里创建文件。

不管是命令行,还是图形化界面,还是第三方库 -- client,最后都是使用SQL语句向服务器发出请求。
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序(mysqld),这个管理程序可以管理多个数据库(Linux的目录),一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
数据逻辑存储
逻辑存储:比如在Linux的学习中,其实有时候我们看到的真正的具体在硬件上 / 存储的时候,可能就是其具体的存储结构,但实际上在计算机里实际呈现的时候可能会有不同的呈现的方式。比如说:内存,内存对应着一些硬件,然后进程看待这个内存有程序地址空间,所以每一个进程对于内存就都可以以虚拟地址空间的方式看 -- 虚拟地址空间也就可以是一种逻辑结构。还有最经典的Linux下一切接文件,这个文件就称作为逻辑结构。
换而言之,就是对于MySQL也一样,它实际存数据根本就可以说不是以表的形式存的,明确一点就是以二进制的方式去存数据的。

给用户呈现的表结构就是逻辑结构。也就是说给我们看到的和它实际存的是不一样的,是因为操作系统和MySQL做了相关的转化。
#问:MySQL它的逻辑结构是什么?

MySQL的逻辑结构是基于行和列的。
MySQL架构

MySQL在宏观上一共分三层:
1、连接层:主要是做连接管理以及鉴权,还有一些安全策略。
作为一个客户端连接过来,那么MySQL里面一定有while循环获取连接,MySQL底层用的是多线程。所以MySQL收到了对应的连接之后,一定要将连接拿上来,可是有的连接是好的,有的连接又是坏的,有的连接上面有非法请求……。所以MySQL在连接这里需要做一些连接管理,比如长时间连接却不访问,于是便要将连接关掉。再比如说连接连接起来之前,需要做鉴权,先认识你这个用户,看你这个用户是不是一个合法的用户(输密码……)。
2、服务层:在MySQL数据库系统处理底层数据之前的所有工作都是在这一层完成的,包括权限判断、SQL接口、SQL解析、SQL分析优化、缓存查询的处理以及部分内置函数执行等。各个存储引擎提供的功能都集中在这一层,如存储过程、触发器、试图等。
3、存储引擎层:说直白点就是真正办事的,由多种可拔插的存储引擎共同组成,真正负责MySQL中数据的存储和提取,每个存储引擎都有自己的优点和缺陷,服务层是通过存储引擎API来与它们交互的。将数据存储在裸设备的文件系统之上,完成存储引擎的交互。
其实没有到磁盘,因为MySQL实际上是一个在Linux操作系统上跑的软件,所以其不能让MySQL直接访问磁盘,它是通过操作系统的结构实现的。
站在操作系统的角度去理解:

SQL分类
SQL语句可分为如下三类:
- DDL【data definition language】数据定义语言,用来维护存储数据的结构 -- 对数据库和表结构更多的是属性控制。
- 代表指令:create, drop, alter
- DML【data manipulation language】数据操纵语言,用来对数据进行操作 -- 对数据库和表结构更多的是数据内容的操作。
- 代表指令:insert,delete,update
- DCL【Data Control Language】数据控制语言,主要负责权限管理和事务 -- 对整个MySQL的系统安全和账户管理工作 -- 保证MySQL主动和被动下都是比较可靠的。
- 代表指令:grant,revoke,commit
数据库有一个特点,它与一般的服务的是不一样的,一般的服务被请求,最多就是影响一下连接,恶意的无非就是消耗连接 / 利用服务器漏洞做一些非法入侵操作。数据库不一样,数据库内存储的是大量的用户数据,一旦出现了安全问题 / 泄露问题就极有可能对用户造成损失。
所以数据库需要完成基本的功能要求(DDL 与 DML),还要一方防止数据库无意的出现问题,另一方面更要防止有意的出现问题,所以数据库还要有一个既不对数据库 / 表结构做属性操作,有不对内容做操作,而是它有时候需要对:用户的合法性、用户的权限控制(负责主动发起攻击的恶意用户)、……。
#: DML中又单独分了一个DQL,数据查询语言,代表指令: select
存储引擎
存储引擎
融汇贯通的理解:
引擎:就像一辆的汽车的动力引擎 -- 发动机,在一辆汽车的整个动力中,主要都是围绕发动机进行展开的工作。
即,在一整个系统当中,真正给系统提供主要问题的 - 引擎。
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
查看存储引擎
输入:show engines;
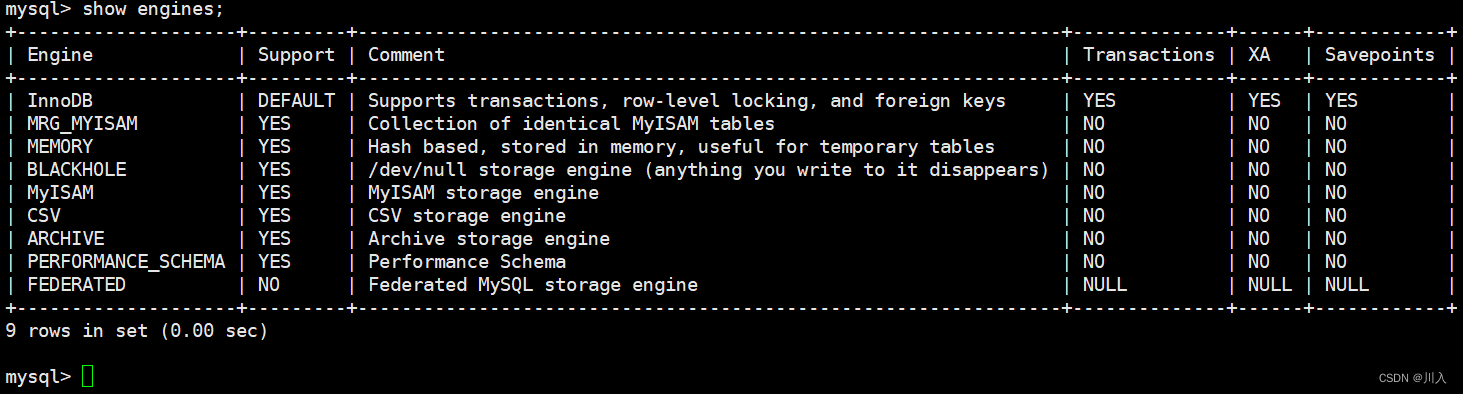
此处默认支持的存储引擎:

这是本人在/etc/my.cnf的配置文件内配置的。

这个意义就是:MySQL有多种存储引擎,然后默认我选择innodb。innodb:MySQL被并发访问的时候的并发情况和数据的安全处理情况的工作做的比较好。




![JavaWeb08(MVC应用02[家居商城]连接数据库)](https://img-blog.csdnimg.cn/6ff31e8ba5ed4f0b9c59f03007db7b41.png)