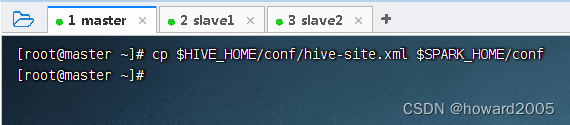
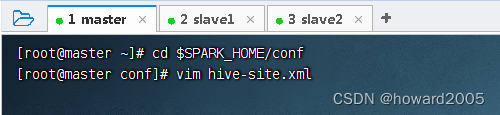
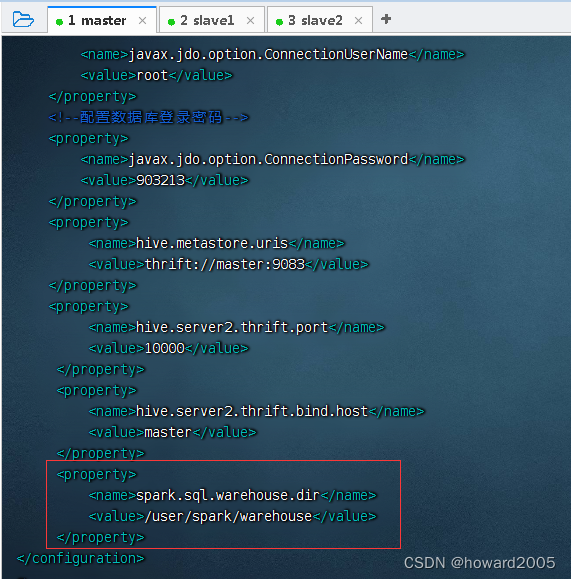
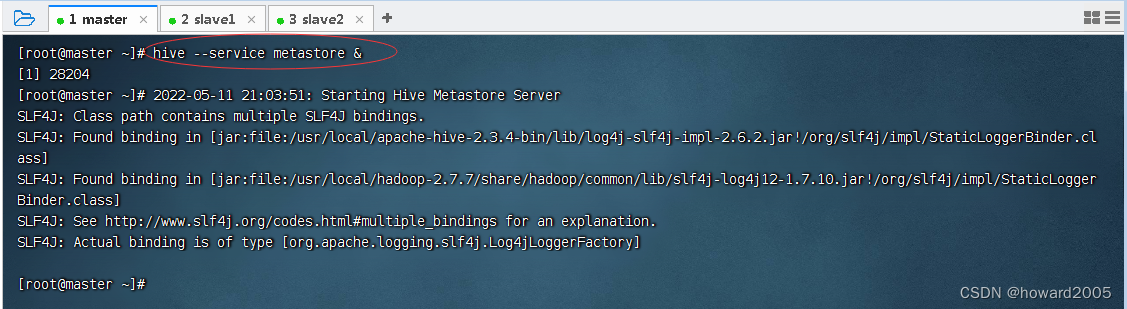
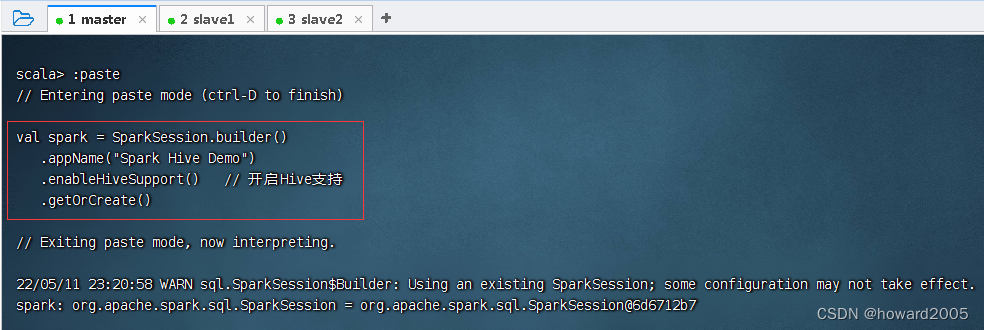
val spark = SparkSession.builder().appName("Spark Hive Demo").enableHiveSupport()// 开启Hive支持 .getOrCreate()
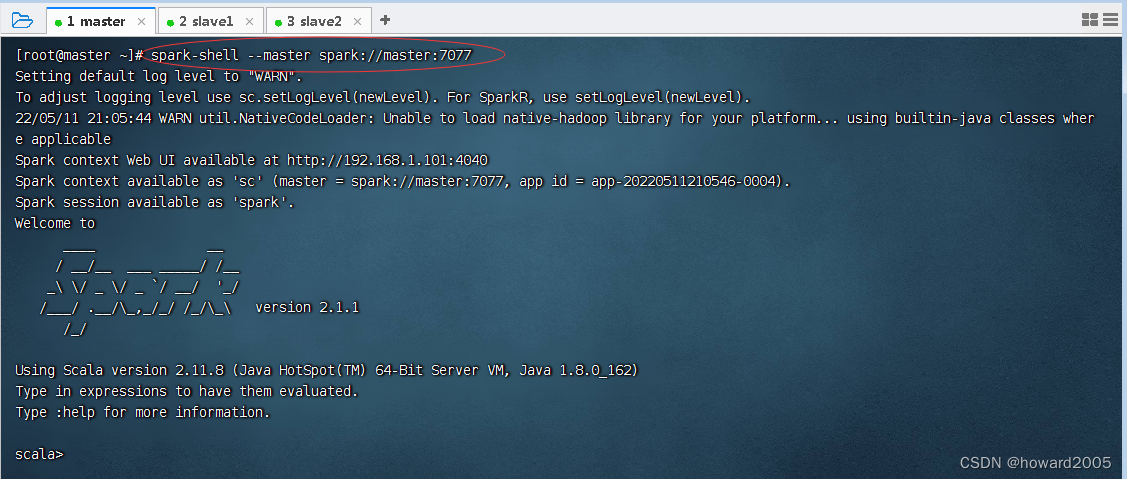
执行上述命令
(三)执行HiveQL语句
调用SparkSession对象的sql()方法可以传入需要执行的HiveQL语句。
1、创建Hive表
创建一张Hive表student,并指定字段分隔符为半角逗号“,”,执行命令:spark.sql("CREATE TABLE IF NOT EXISTS student(id INT, name STRING, gender STRING, age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','")
2、导入本地数据到Hive表
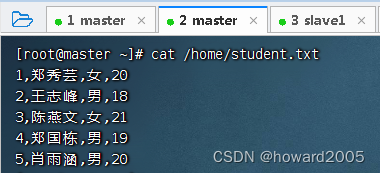
查看本地文件/home/student.txt的内容
将该文件数据导入表student中,执行命令:spark.sql("LOAD DATA LOCAL INPATH '/home/student.txt' INTO TABLE student")
这个报错是hdfs客户端的一个bug,但并不影响作业正常运行,且在2.8版本之后已经修复
3、查询Hive表数据
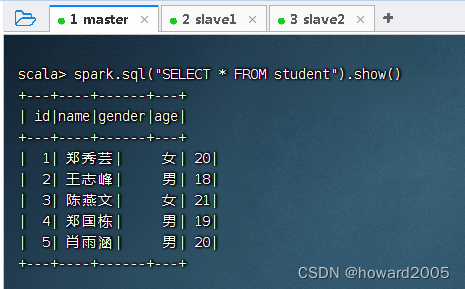
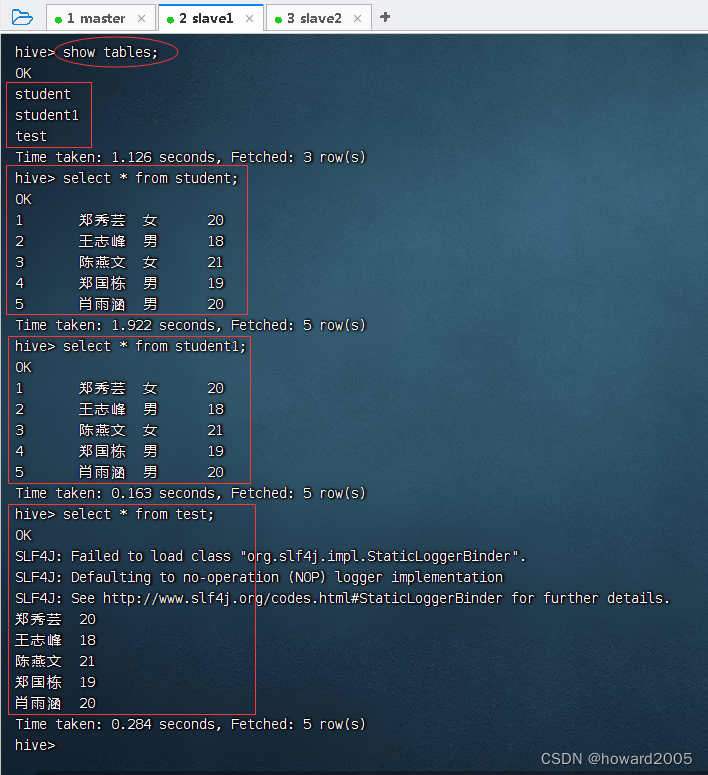
查询表student的数据并显示到控制台,执行命令:spark.sql("SELECT * FROM student").show()
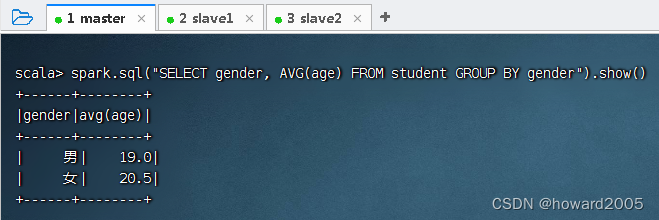
按性别分组统计平均年龄,执行命令:spark.sql("SELECT gender, AVG(age) FROM student GROUP BY gender").show()
4、创建表时指定存储格式
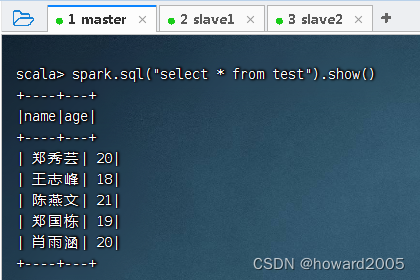
创建一个Hive表test,数据存储格式为Parquet(默认为普通文本格式),执行命令:spark.sql("CREATE TABLE test (name STRING, age INT) STORED AS PARQUET")
查询test表数据,执行命令:spark.sql("select * from test").show()
6、导入HDFS数据到Hive表
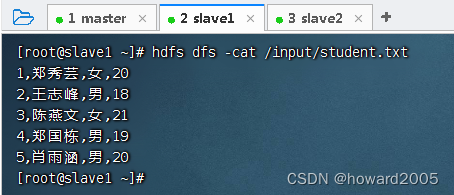
查看HDFS文件/input/student.txt的内容
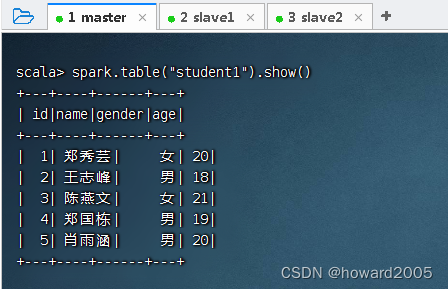
创建Hive表student1,执行命令:spark.sql("CREATE TABLE IF NOT EXISTS student1 (id INT, name STRING, gender STRING, age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','")
将该文件数据导入表student1中,执行命令:spark.sql("LOAD DATA INPATH 'hdfs://master:9000/input/student.txt' INTO TABLE student1")