前情提要:https://blog.csdn.net/weixin_45434953/article/details/130604086
正规方程
正规方程能以更好的方式求得假设函数中 θ \theta θ的最优值。它提供了一种用于求 θ \theta θ的解析方法,而不是梯度下降那样的迭代方法。也就是只需要一次运算就可以得出结果。设有一个代价函数 J ( θ 0 , θ 1 . . . , θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta_0,\theta_1...,\theta_n) = \frac{1}{2m}\sum_{i=1}^{m} (h_\theta(x^{(i)})-y^{(i)})^2 J(θ0,θ1...,θn)=2m1i=1∑m(hθ(x(i))−y(i))2那么我们对于每一个 j ∈ ( 0 , m ) j\in(0,m) j∈(0,m)令 ∂ ∂ θ j J ( θ ) = 0 \frac{\partial}{\partial \theta_j}J(\theta)=0 ∂θj∂J(θ)=0,然后求出 θ j \theta_j θj的值。根据微积分,我们知道函数 f ( x ) f(x) f(x)若在 x = x 0 x=x_0 x=x0取得最小值 f ( x 0 ) = f m i n ( x ) f(x_0)=f_{min}(x) f(x0)=fmin(x),那么在 x 0 x_0 x0处 f ( x ) f(x) f(x)的导数 f ′ ( x 0 ) f'(x_0) f′(x0)一定为0。反过来,导数为0的位置不一定是最值。
假设现在的数据样本如下:
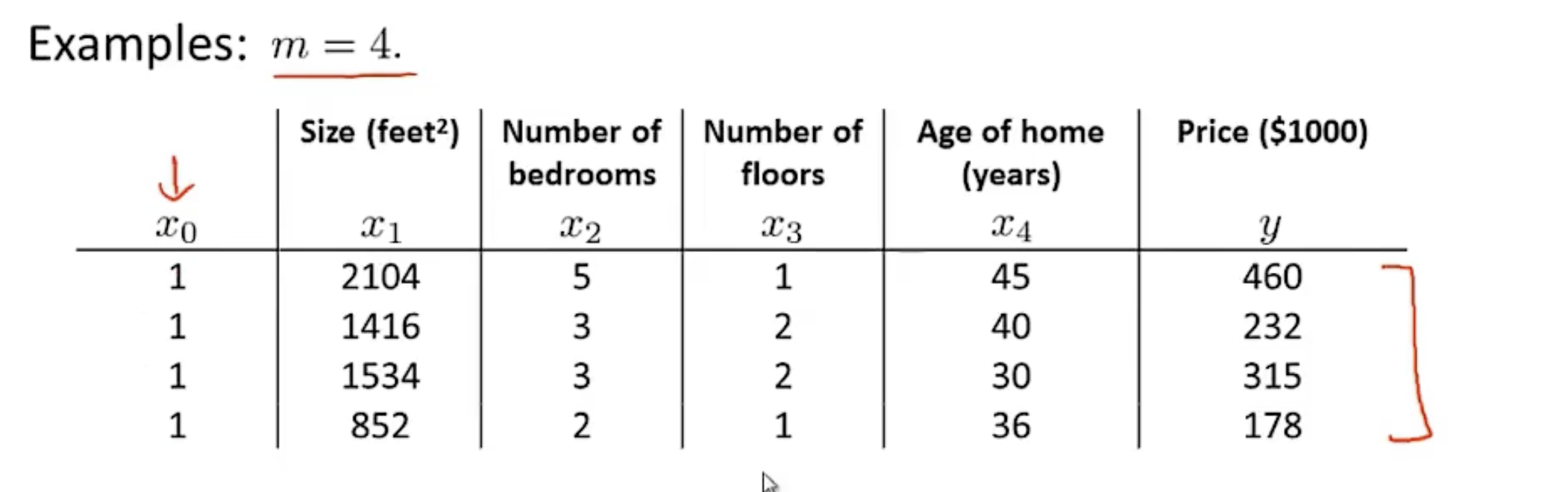
前面说过,
x
0
x_0
x0是恒等于1的。那么实际上我们可以根据上述的数据构建如下的矩阵:
X
=
[
1
2104
5
1
45
1
1416
3
2
40
1
1534
3
2
30
1
852
2
1
36
]
,
y
=
[
460
232
315
178
]
X=\begin{bmatrix} 1& 2104& 5 & 1 & 45\\ 1& 1416& 3 & 2 & 40\\ 1& 1534& 3 & 2 & 30\\ 1& 852& 2 & 1 & 36\end{bmatrix}, y=\begin{bmatrix} 460\\ 232\\ 315\\ 178 \end{bmatrix}
X=
11112104141615348525332122145403036
,y=
460232315178
那么,计算
θ
\theta
θ的方法是:
θ
=
(
X
T
X
)
−
1
X
T
y
\theta=(X^TX)^{-1}X^Ty
θ=(XTX)−1XTy
需要注意的是,正规方程不需要使用特征缩放。
正规方程和梯度下降的对比:
梯度下降需要选择学习速率,并且需要迭代,而正规方程不需要。但是对于特征量n较大的情况,
(
X
T
X
)
−
1
(X^TX)^{-1}
(XTX)−1会消耗大量的时间,通常认为正规方程的时间复杂度为O(n3),因此梯度下降更适合应对n较大的情况,一般以n=10000为分界线。而且梯度下降在很多算法中都会广泛的应用,但是正规方程一般只用于线性回归。