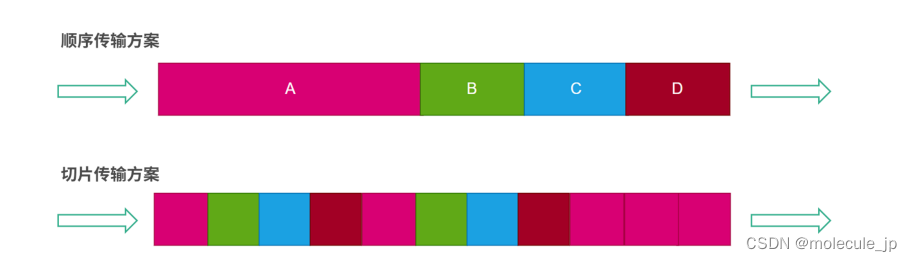文章目录
- 前言
- 一、内存对齐是什么?
- 二、这一行是什么?
- 高速缓存行: CacheLine
- 为啥补齐到64?
- 总结
前言
著名的Java并发编发锁编程大师Doug lea在JDK 7的并发包里新增一个队列集合LinkedTransferQueue,它在使用volatile变量时,用一种追加字节的方式来优化队列出队和入队的性能;
意思是,通过追加字符串,然后提升性能;这种方式看起来很神奇,但如果深入理解处理器架构就能理解其中的奥秘。
一、内存对齐是什么?
LinkedTransferQueue的代码如下:
/** 队列中的头部节点 */
private transient f?inal PaddedAtomicReference<QNode> head;
/** 队列中的尾部节点 */
private transient f?inal PaddedAtomicReference<QNode> tail;
static f?inal class PaddedAtomicReference <T> extends AtomicReference T> {
// 使用很多4个字节的引用追加到64个字节
Object p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;
PaddedAtomicReference(T r) {
super(r);
}
}
public class AtomicReference <V> implements java.io.Serializable {
private volatile V value;
// 省略其他代码
}
LinkedTransferQueue这个类,它使用一个内部类类型来定义队列的头节点(head)和尾节(tail),而这个内部类PaddedAtomicReference相对于父类AtomicReference只做了一件事情,就是将共享变量追加到64字节。我们可以来计算下,一个对象的引用占4个字节,它追加了15个变量(共占60个字节),再加上父类的value变量,一共64个字节;
上述内容用图表示,大概如下

为什么追加到64字节能够提高并发编程的效率呢?因为对于英特尔酷睿i7、酷睿、Atom和NetBurst,以及Core Solo和Pentium M处理器的L1、L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行,这意味着,如果队列的头节点和尾节点都不足64字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头、尾节点,当一个处理器试图修改头节点时,会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作则需要不停修改头节点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Doug lea使用追加到64字节的方式来填满高速缓冲区的缓存行,避免头节点和尾节点加载到同一个缓存行,使头、尾节点在修改时不会互相锁定。
说人话就是: head 与tail 不在同一行,当修改的head 和tail的时候,应该是两个线程在操作; 如果不追加,将导致head 和tail 在同一行,那么修改head 和tail 的两个线程,需要相互通知,等待,因为相当于在操作同一个资源; 这就是内存补齐(补齐到计算机的进制位数大小),能提高速度的原因;

未补齐的大致样子
二、这一行是什么?
没错,这一行是什么,就是上面我画的这一行是什么东西?
高速缓存行: CacheLine
这篇文章写的不错 传送门
我做出如下总结:
- 每一行其实都是从内存中读取的数据的缓存,相当于从主内存获取的数据,然后放到自己的工作线程中的一个缓存;
为啥补齐到64?
这个不是绝对的,看你使用的计算机,如果是64位,那么做如上处理就没问题了~~
总结
来自: java并发编程的艺术~




![### Cause: dm.jdbc.driver.DMException: 列[URI]长度超出定义](https://img-blog.csdnimg.cn/d8a23449cf6946dcb97bca8db35e991d.png)