1.C++11
- auto 范围for 新容器 线程库
- 列表初始化
- 右值引用和移动语义 lambda表达式
- 容器支持花括号列表初始化 本质是增加一个initializer_list的构造函数
- initializer_list支持花括号
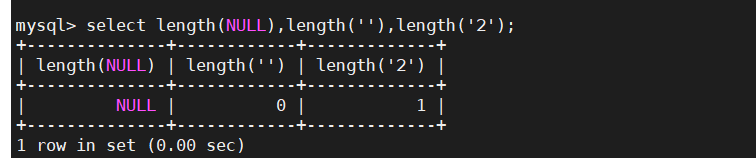
2.列表初始化
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <vector>
#include <list>
#include <string>
#include <map>
using namespace std;
//列表初始化 不过我们要能看懂 实际中用的也不多
class Point
{
public:
Point(int x = 0, int y = 0)
:_x(x),
_y(y)
{}
private:
int _x;
int _y;
};
int main()
{
int x = 1;
//int y{ 2 };//C++11支持
//C++11 花括号初始化
vector<int> v1{ 1,2,3,4,5 };//C++11
vector<int> v2 = { 1,2,3,4,5 };
list<int> l1{ 1,2,3,4,5 };//C++11
list<int> l2 = { 1,2,3,4,5 };
map<string, int> m1{ {"苹果",1},{"西瓜",2},{"香蕉",3} };//C++11
map<string, int> m2 = { {"苹果",1},{"西瓜",2},{"香蕉",3} };
Point p1(1, 2);
Point p2{ 1,2 };
Point p3 = { 1,2 };
//容器如何支持花括号? 构造函数
return 0;
}
利用花括号进行初始化 容器支持花括号需要构造函数
3.类型推导
//类型推导 属于RTTI run time type identification
//程序运行起来对对象的类型识别
//(了解)
int main()
{
int a = 10;
double b = 20;
auto c = a + b;
//typeid(c)构造对象 .name 调用成员函数 拿到类型名称
cout << typeid(c).name() << endl;
string s;
//拿到类型名称的字符串
cout << typeid(s).name() << endl;
//假设我想定义一个跟c和s一样类型的对象
//decltype通过对象去推类型
decltype(c) d;
decltype(s) e;
cout << typeid(d).name() << endl;
cout << typeid(e).name() << endl;
return 0;
}
auto 可推导
decltype 通过对象去推类型
typeid().name() 拿到类型名称的字符串

4.auto和范围for
//auto和范围for->简化代码的写法
//熟悉
int main()
{
std::map<std::string, std::string> dict{ {"insert","插入"},{"sort","排序"} };
std::map<std::string, std::string>::iterator it1 = dict.begin();
auto it2 = dict.begin();
//这里it1和it2可以认为是完全一个类型的对象
//唯一差别是it2的类型是编译器自动推导出来
//auto的优势就是可以把在类型比较复杂地方 简化代码的写法
//这里要注意当容器村对象比较大 或者这个对象要做深拷贝 如string
//最好给&和const 可以减少拷贝提高效率
//容器支持范围for原理 范围for会被编译器替换成迭代器 也就是意味着支持迭代器就支持范围for
//for(auto e : dict)
for (const auto& e : dict)
{
cout << e.first << ":" << e.second << endl;
}
//auto不能去做形参和返回值的
//正常是这样的
//for (std::pair<const std::string,std::string>& e: dict)
//{
// cout << e.first << ":" << e.second << endl;
//}
//除了STL的容器使用范围for 数组也可以(原生指针可以认为也是天然迭代器 比如
//vector/string的迭代器就是原声指针)
int a[] = { 1,2,3,3,5,4 };
for (auto e : a)
{
cout << e << " ";
}
cout << endl;
return 0;
}

5.final和override
final与override(了解)
这两个关键字分别的作用是什么?
final修饰类 类就变成了最终类 不能被继承
final还可以修饰虚函数 这个虚函数不能被重写
override是子类重写虚函数 检查是否完成重写
不满足重写的条件 则报错
6.C++11新容器
新容器
C++98容器
string/vector/list/map/set + stack/queue/priority_queue
C++11新容器
array(定长数组)/forword_list(单链表)
**array(**定长数组):实际中用的很少
缺点:定长+存储数据的空间在栈上 栈的空间本来就不大
forword_list(单链表):实际中用得少
缺点:不支持尾插尾删 + insert数据也是在当前位置的后面
unordered_map/unordered_set:推荐
因为他们的效率高于map/set
#include <array>
int main()
{
array<int, 100> a;
return 0;
}
//默认成员函数控制
class A
{
public:
A() = default;//指定显示去生成默认构造函数
A(const int& a)//拷贝构造 写了拷贝构造不会有默认构造函数
:_a(a)//没有构造函数用不了
{}
private:
int _a = 10;
};
int main()
{
A aa1;
A aa2(aa1);
aa1 = aa2;
return 0;
}
要求A的对象不能拷贝和赋值(防拷贝)
//C++98
class A
{
public:
A() = default;
//C++98
//只声明 不定义 这样就没办法用(拷贝对象)
//缺陷:别人可以在类外面定义
//为了解决这个缺陷 private限定
//类外面也没办法了
private:
A(const A& aa);
A& operator=(const A& aa);
private:
int _a = 10;
};
//类外面定义
A::A(const A& aa)
{}
int main()
{
A aa1;
A aa2(aa1);
aa1 = aa2;
return 0;
}
//C++11做法
class A
{
public:
A() = default;
//C++11
//delete搞成删除函数
A(const A& aa) = delete;
A& operator=(const A& aa) = delete;
private:
int _a = 10;
};
int main()
{
A aa1;
A aa2(aa1);
aa1 = aa2;
return 0;
}
C++11做法更加优秀
7.右值引用
1°概念和语法
C++98就提出了引用的概念 引用就是给一个对象取别名
C++98 左值引用
C++11 右值引用
不管是左值引用还是右值引用 他们都是给对象取别名
左值引用主要给左值取别名 右值引用主要给右值取别名
什么是左值?什么是右值?
左边就是左值?右边就是右值?
注意这个是一个C语法留下的坑 就像左移和右移一样
这里左右不是方向 左边的值不一定是左值 右边的不一定是右值
int x1=10;int x2=x1;这里x1是左值 10是右值 x2是左值
可以修改就可以认为是左值 左值通常是变量
右值通常是常量 表达式或者函数返回值(临时对象)
int main()
{
int x = 1, y = 2;
//左值引用的定义
int a = 0;
int& b = a;
//左值引用不能引用右值 const左值引用可以
//int& e = 10;
//int& f = x + y;
const int& e = 10;
const int& f = x + y;
//右值引用的定义
int&& c = 10;
int&& d = x + y;
//右值引用不能引用左值 但是可以引用move后左值
//int&& m = a;
int&& m = move(a);
return 0;
}
//C++98
template<class T>
void f(const T& a)
{
cout << "void f(const T& a)" << endl;
}
template<class T>
void f(const T&& a)
{
cout << "void f(const T&& a)" << endl;
}
int main()
{
int x = 10;
f(x);//这里会匹配左值引用
f(10);//这里会匹配右值引用
return 0;
}

C++11又将右值区分为:纯右值和将亡值
纯右值:基本类型的常量或者临时对象
将亡值:自定义类型的临时对象
结论:所有深拷贝类(vector/list/map/set) 都可以加两个右值引用移动拷贝和移动赋值
2°移动构造和移动赋值
//MyString
class String
{
public:
String(const char* str = "")
{
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
//s2(s1) 左值
String(const String& s) noexcept
{
cout << "String(const String& s)-深拷贝-代价大-效率低" << endl;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
//s3(右值-将亡值) 右值
String(String&& s) noexcept
:_str(nullptr)
{
std::cout << "String(String&& s)-移动拷贝-效率高" << endl;
swap(_str, s._str);
}
~String()
{
delete[] _str;
}
// s3 = s4
String& operator=(const String& s) noexcept
{
cout << "String& operator=(const String& s)-拷贝赋值" << endl;
if (this != &s)
{
char* newstr = new char[strlen(s._str) + 1];
strcpy(newstr, s._str);
delete[] _str;
_str = newstr;
}
return *this;
}
//s3 = 右值-将亡值
String& operator=(String&& s) noexcept
{
cout << "String& operator=(String&& s)-移动赋值-效率高" << endl;
swap(_str, s._str);
return *this;
}
//s1 + s2 s1不变
String operator+(const String& s2)
{
String ret(*this);//拷贝
//ret.append(s2._str);
return ret;//拷贝 返回的是右值 临时对象
}
//s1 += s2 s1会变 可以引用返回
String& operator+=(const String& s2)
{
//this->append(s2);
return *this;//这里无拷贝 返回的是左值
}
private:
char* _str;
};
String f(const char* str)
{
String tmp(str);
return tmp;//这里不会返回tmp tmp生命周期到了 这里返回的实际是tmp的临时对象
}
int main()
{
String s1("左值");
String s2(s1); //参数是左值
String s3(f("右值-将亡值"));//参数是右值-将亡值(传递给你用 用完我就析构) move
String s4(move(s1)); //move以后就是将亡值
String s5("左值");
s5 = f("右值-将亡值");
return 0;
}

3°传值返回
int main()
{
String s1("s1");
String s2("s2");
String s3 = s1 += s2;//拷贝构造
String s4 = s1 + s2; //拷贝构造+移动构造
//现实中不可避免存在传值返回的场景 传值返回的拷贝返回对象的临时对象
//如果vector只实现参数为const左值引用深拷贝 那么下面的代价就很大
//vector(const vector<T>& v)->深拷贝
//但是如果vector实现了参数右值引用的移动拷贝 那么这里效率就会很高
//vector(vector<T>&& v)->移动拷贝
//结论:右值引用本身没太多意义 右值引用实现了移动构造和移动赋值
//那么面对接收函数传值返回对象(右值)等等场景 可以提高效率
//3.当传值返回值 返回时右值 结合前面学的移动构造和移动赋值 可以减少拷贝
return 0;
}
#include <string>
string f(const char* str)
{
string tmp(str);
return tmp;//这里不会返回tmp tmp生命周期到了 这里返回的实际是tmp的临时对象
}
int main()
{
string s1("左值");
string s2(s1);
string s3(f("右值"));
return 0;
}
4°右值引用作函数参数
std::vector::push_back void push_back(const value_type& val); void push_back(value_type&& val);
std::list::push_back void push_back(const value_type& val); void push_back(value_type&& val);
std::set::insert void push_back(const value_type& val); void push_back(value_type&& val);
std::vector::emplace_back template<class.. Args> void emplace_back(Args&&... args) //模板的可变参数(了解) 网上有人说:emplace版本比push和insert高效 这句话不准确 没有深入去分析
...其他容器插入数据结构也基本都是两个重载实现 一个左值引用 一个右值引用
int main()
{
vector<string> v;
string s1("左值");
int val = 1234;
//push_back中调用的是string的拷贝构造
v.push_back(s1);//调左值
//push_back中调用的是string的移动构造
v.push_back("右值");//临时对象 隐式类型转成string 调右值
v.push_back(to_string(val));//to_string是传值返回 调右值
v.emplace_back(s1);
v.emplace_back("右值");
vector<pair<string, string>> vp;
vp.push_back(make_pair("右值", "右值"));//调的右值
pair<string, string> kv("左值", "左值");//调的左值
vp.push_back(kv);
vp.emplace_back(make_pair("右值", "右值"));//右值
vp.emplace_back(kv);//左值
vp.emplace_back("右值", "右值"); // 体现emplace_back模板可变参数的特点的地方 右值
return 0;
}
5°总结
右值引用作参数和作返回值减少拷贝的本质是移动构造和移动赋值
左值引用和右值引用本质的作用都是减少拷贝 右值引用本质可以认为是弥补左值引用不足的地方
相辅相成 都是减少拷贝
左值引用:解决的时传参过程中和返回值过程中的拷贝
作参数:void f1(T x) -> void f1(T& x) 解决的是传参过程中减少拷贝
作返回值:T f2() -> T& f2() 解决的返回值过程中的拷贝 但是无法解决接收返回值时的拷贝 比如T ret = f2();
但是要注意这里有限制 如果返回对象出了作用域不在了就不能传引用返回 这个左值引用无法解决
右值引用:解决的是传参后 push/insert函数内部将对象移动到容器空间上的问题
传值返回接收返回值的拷贝
作参数:void push(const T&& x) 解决的push内部不再使用拷贝构造x到容器空间上 而是移动构造过去
作返回值:T f2() 解决的外面调用接收f2()返回对象的拷贝 T ret = f2() 这里就是**右值引用的移动构造 减少了拷贝
8.完美转发
完美转发是指在函数模板中,完全依照模板的参数的类型,将参数传递给函数模板中调用
的另外一个函数。
forward完美转发
//完美转发
void Fun(int& x) { cout << "lvalue ref" << endl; }
void Fun(const int& x) { cout << "const lvalue ref" << endl; }
void Fun(int&& x) { cout << "rvalue ref" << endl; }
void Fun(const int&& x) { cout << "const rvalue ref" << endl; }
template<typename T>
void PerfectForward(T&& t)
{
//Fun(t); //右值引用会在第二次之后的参数传递过程中属性丢失 下一层调用会全部识别为左值
//加上forward进行完美转发 此时左值还是左值 右值还是右值
Fun(std::forward<T>(t));
}
int main()
{
PerfectForward(10); // rvalue ref 走右值
int a;
PerfectForward(a); // lvalue ref 走左值
PerfectForward(std::move(a)); // rvalue ref 走右值
const int b = 8;
PerfectForward(b); // const lvalue ref 走const左值
PerfectForward(std::move(b)); // const rvalue ref 走const右值
string s0("hello");
string s1 = to_string(11111);
return 0;
}

9.lambda表达式
1°排序
//整型排序
#include <algorithm>
#include <functional>
template<class T>
struct Greater
{
bool operator()(const T& x1, const T& x2)
{
return x1 > x2;
}
};
bool g2(const int& x1, const int& x2)
{
return x1 > x2;
}
int main()
{
int array[] = { 4,1,8,5,3,7,0,9,2,6 };
// 默认按照小于比较,排出来结果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
// 如果需要降序,需要改变元素的比较规则
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
Greater<int> g1;//给一个类的对象g1
g1(1, 2);//g1是一个对象 调operator()实现的比较
g2(1, 2);//g2是一个函数指针 这里是的调用他指向的函数
//他们是完全不同的类型对象 但是他们用起来是一样的
std::sort(array, array + sizeof(array) / sizeof(array[0]), g1);
std::sort(array, array + sizeof(array) / sizeof(array[0]), g2);
return 0;
}
仿函数和函数指针
#include <algorithm>
#include <functional>
struct Goods
{
string _name; // 名字
double _price;// 价格
int _num; // 数量
//...
};
//那么这里如果去重载Goods的operator>/operator<是不好的
//因为你不知道需要按哪一项成员去比较
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
struct CompareNumGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._num > gr._num;
}
};
struct CompareNameGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._name > gr._name;
}
};
int main()
{
Goods gds[] = { { "苹果", 2.1 }, { "相交", 3 }, { "橙子", 2.2 }, {"菠萝", 1.5} };
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), ComparePriceGreater());
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), CompareNumGreater());
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), CompareNameGreater());
return 0;
}
此时需要写三个仿函数 很重复 lambda表达式可优化
2°使用
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
注意: 在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空。因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。
int main()
{
[] {};//没有参数 没有返回值可以不写
//定义在函数中的匿名函数
int a = 3, b = 4;
//实现a+b的lambda表达式
//不捕捉
auto add1 = [](int x1, int x2)->int {return x1 + x2; };
add1(a, b);
//直接捕捉
//auto add2 = [a, b]()->int {return a + b; };
auto add2 = [=]()->int {return a + b; };//全部捕捉
add2();
//不捕捉
auto swap1 = [](int& x1, int& x2) {
int x = x1;
x1 = x2;
x2 = x;
};
swap1(a, b);
//捕捉 不用传参
auto swap2 = [&a, &b]() {
int x = a;
a = b;
b = x;
};
swap2();
//全部引用捕捉
auto swap3 = [&]() {
int x = a,
a = b;
b = x;
};
swap3();
return 0;
}
改进后:
int main()
{
//原来
Goods gds[] = { { "苹果", 2.1 }, { "相交", 3 }, { "橙子", 2.2 }, {"菠萝", 1.5} };
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), ComparePriceGreater());
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), CompareNumGreater());
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), CompareNameGreater());
//lanbda表达式
auto price_greater = [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price;
};
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), price_greater);
//lanbda表达式直接作参数
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price;});
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price; });
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods& g1, const Goods& g2) {
return g1._name > g2._name; });
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods& g1, const Goods& g2) {
return g1._name < g2._name; });
//我们会发现在这里使用lambda表达式更方便一些
return 0;
}
第三个参数直接传lambda表达式
通过对象+.+成员可以直接看到比较的是什么 仿函数命名好也可以
lambda表达式其实定义函数内存的匿名函数函数
int main()
{
//[捕捉列表](参数)->返回值类型[函数体]
int a = 0, b = 1;
//实现一个a+b的lambda表达式
auto add1 = [](int x1, int x2)->int {return x1 + x2; };
cout << add1(a, b) << endl;
//捕捉列表就是捕捉跟我一个作用域的对象
//传值捕捉 [a] 捕捉a [a,b] 捕捉a b [=]捕捉所有对象
//传引用捕捉 [&a] 捕捉a [&a,&b] 捕捉a b [&] 捕捉同一作用域中的所有对象
//传值捕捉的对象是不能改变的 有const属性(加上mutable就可以改变了)
auto add2 = [a, b]()->int {return a + b; };
add2();
//实现a和b交换
//auto swap1 = [](int& a, int& b) {int c = a;a = b;b = c;};
auto swap1 = [](int& x, int& y) {
int z = x;
x = y;
y = z;
};
swap1(a, b);
cout << a << " " << b << endl;
//实际还是不能完成交换
//auto swap2 = [a,b]()mutable {
// int z = a;
// a = b;
// b = z;
//};
//swap2();
//只交换a和b
auto swapab = [&a, &b]() {
int z = a;
a = b;
b = z;
};
swapab();
cout << a << " " << b << endl;
return 0;
}
仿函数很依赖命名 命名号就很容易看懂
如果命名写的不好 要具体看仿函数内部的代码才知道按什么比较的
lambda优势就是会让代码可读性强 一看就知道按照什么比的
int main()
{
int a = 1, b = 2;
//对象 = 对象(编译器生成的lambda_uuid仿函数的对象) auto推出对象
auto add = [](int x, int y)->int {return x + y; };
add(a, b);
//底层还是依靠仿函数来实现 也就是说你定义了一个lambda表达式
//实际上编译器会生成一个叫lambda_uuid类 仿函数的operator()的参数和实现
//就是我们写的lambda表达式的参数和实现
//跟范围for一样 范围for的本质是迭代器 写范围for是为了简便
//lambda表达式的本质是仿函数 写lambda表达式更简便
return 0;
}
10.线程库
1°C++11线程库
C++11 线程库
windows 自己的一套API 如:CreateThread
Linux 使用posix的pthread 如:pthread_create
C++98中 如果你想写多线程的程序 既可以在windows下跑 也可以在Linux下跑
那么怎么办?
用条件编译
#ifdef _WIN32
CreateThread(...)
#else
pthread_create(...)
#endif
C++11线程库
特点:跨平台 面向对象封装的类(每个线程是一个类对象)
实现原理:封装库时使用了条件编译 也就是说他的底层还是分别调用了不同平台的线程API
扩展:吐槽一下C++ C++缺点之一:就是更新有用的东西太慢了 比如线程库C++11(2011)才更新的
而且现在也没有更新一个官方的封装好的靠谱网络库 其次一些不痛不痒的语法更新了一堆 增加学习成本
2°函数指针配合thread
#include <thread>
#include <mutex>
#include <atomic>
mutex mtx;//只允许一个线程进
//int x = 0;
atomic<int> x = 0;//++调的operator++
//支持整型/浮点型的原子++或者-- 不需要加锁
//扩展学习:CAS->无锁编程
//两个线程去一起对x加n次
void Add(int n)
{
//加到外面和里面 哪个效率高
//锁加到外面 串行 一个线程跑完了 另一个线程接着跑
mtx.lock();
for (int i = 0; i < n; i++)
{
++x;
}
mtx.unlock();
//锁加到里面 并行
/*for (int i = 0; i < n; i++)
{
mtx.lock();//t2刚切出去 t1就解锁了 马上就把t2切回来
++x;
mtx.unlock();
}*/
//串行更快
//思考为什么串行还快一些?
//因为这里锁的粒度太小了 时间都花到切换上下文
}
int main()
{
thread t1(Add, 10000);//函数名 参数
thread t2(Add, 10000);//次数一多就会出问题
//同时加的时机不一样 最后结果不一定是20000
//解决:加锁 注意线程安全
//main是主线程 t1 t2没走完 主线程会走完 直接抛异常
t1.join();
t2.join();
//join就是等t1 t2先走完
cout << x << endl;
return 0;
}

3°仿函数配合thread
atomic<int> x = 0;
struct Add
{
void operator()(int n)
{
for (int i = 0; i < n; ++i)
{
++x;
}
}
};
int main()
{
Add add;//对象
thread t1(add, 100000);//对象调operator() 后面为operator()的参数
thread t2(add, 100000);
//thread t2(Add(),100000);//匿名对象
cout << t1.get_id() << endl;
cout << t2.get_id() << endl;
t1.join();
t2.join();
cout << x << endl;
}

4°lambda表达式配合thread
int main()
{
atomic<int> x = 0;
auto add = [&x](int n) {
for (int i = 0; i < n; ++i)
{
++x;
}
};
thread t1(add, 100000);//接收对象作为函数名 然后传参
thread t2(add, 100000);
cout << t1.get_id() << endl;
cout << t2.get_id() << endl;
t1.join();
t2.join();
cout << x << endl;
return 0;
}

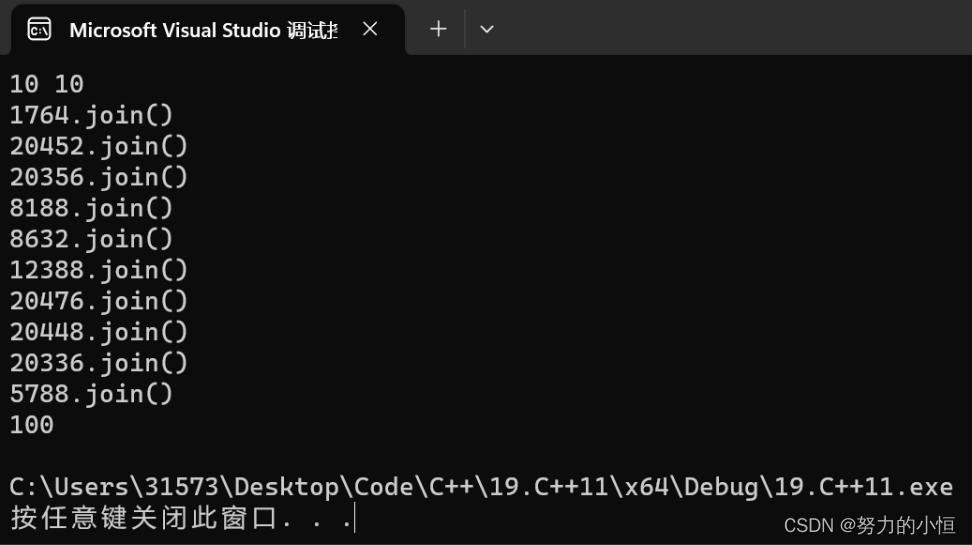
int main()
{
atomic<int> x = 0;
//m个线程对x加n次
int m, n;
cin >> m >> n;
//法1
//vector<thread> vthreads;
//for (int i = 0; i < m; ++i)
//{
// vthreads.push_back(thread([&x](int count) {
// for (int i = 0; i < count; ++i)
// {
// ++x;
// }
// },n));
//}
//法2 注意的是thread支持移动拷贝和移动赋值 不支持深拷贝的拷贝构造和拷贝赋值
vector<thread> vthreads(m);
for (int i = 0; i < m; ++i)
{
//移动赋值 右边是匿名对象(将亡值)
vthreads[i] = thread([&x](int count) {
for (int i = 0; i < count; ++i)
{
++x;
}
}, n);
}
for (auto& t : vthreads)
{
cout << t.get_id() << ".join()" << endl;
t.join();
}
cout << x << endl;
return 0;
}
5°交替打印
//使用两个线程打印0-n之间的数 一个线程打印奇数 一个线程打印偶数 要求依次打印 打印1后打印2
#include <mutex> //互斥锁
#include <condition_variable> //条件变量
int main()
{
int n = 100;
mutex mtx1, mtx2;
condition_variable cv1, cv2;
//1代表线程1 2代表线程2
thread t1([&]()
{
//偶数
for (int i = 0; i < n; i+=2)
{
unique_lock<mutex> locker1(mtx1);
//不加条件 两边都在等
if (i != 0)
{
cv1.wait(locker1);
}
if (i % 2 == 0)
cout << this_thread::get_id() << ":" << i << endl;
cv2.notify_one();// t1打印偶数以后 通知t2
}
});
thread t2([&]()
{
//奇数
for (int i = 1; i < n; i+=2)
{
unique_lock<mutex> locker2(mtx2);
cv2.wait(locker2);
if (i % 2)
cout << this_thread::get_id() << ":" << i << endl;
cv1.notify_one(); // t2打印奇数以后 通知t1
}
});
t1.join();
t2.join();
return 0;
}

【C++】19.C++11 完


![心法利器[84] | 最近面试小结](https://img-blog.csdnimg.cn/img_convert/90a5f9e6bbc1e3a556ef065f1394a837.png)