目录
- 1.SpringBoot 中的 @SpringBootApplication注解的作用是什么?
- 2.SpringBoot 中你们是如何加载配置信息的?
- 3.RabbitMQ 如何保证消息不丢失?
- 4.如果消费者这边消费到一半宕机了怎么办?
- 5.RabbitMQ 如何保证消息没有被重复消费?
- 6.JVM 运行时区域有哪几块?
- 7.JVM 垃圾回收算法了解吗?有哪几种?
- 8.JVM 是怎么判断一个对象是否可以被回收呢?
- 9.为什么 HotSpot 虚拟机最终选择了可达性分析而没有选择引用计数法?
- 10.那你说说有哪些对象可以作为可达性分析中的 GC Root ?
- 11.Linux用过吗?说说怎么查看一个进程的进程号?
- 12.Linux怎么查看正在运行的Java程序的日志?
- 13.Linux怎么修改文件的权限?
- 14.命令chomod 777是什么意思?
- 15.一个7就可以代表读写执行权限,为什么有3个7?
1.SpringBoot 中的 @SpringBootApplication注解的作用是什么?
@SpringBootApplication 是一个组合注解,它包含了 @Configuration、@EnableAutoConfiguration 和 @ComponentScan 这三个注解的功能。它的作用是标识一个 Spring Boot 应用的主类,用于启动 Spring Boot 应用程序。
- @SpringBootConfiguration 注解表示该类是一个配置类,它会被 Spring IOC 容器用来生成 Bean 定义。
- @ComponentScan 注解表示扫描指定的包及其子包下的所有组件用于定义 Spring 的扫描路径,等价于在 xml 文件中配置 <context:component-scan > ,假如不配置扫描路径,那么 Spring 就会默认扫描当前类所在的包及其子包中的所有标注了 @Component , @Service , @Controller 等注解的类。,将它们注册到 Spring IOC 容器中。
- @EnableAutoConfiguration 注解表示开启自动配置,Spring Boot 会根据项目中的依赖自动配置应用程序。
这个注解才是实现自动装配的关键,点进去之后发现,它是一个由 @AutoConfigurationPackage 和 @Import 注解组成的复合注解。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
看起来很多注解,实际上关键在 @Import 注解,它会加载
AutoConfigurationImportSelector 类,然后就会触发这个类的 selectImports() 方法。根据返回的 String 数组(配置类的 Class 的名称)加载配置类。
我们重点看下
AutoConfigurationImportSelector 。
AutoConfigurationImportSelector中的selectImport是自动装配的核心实现,它主要是读取META-INF/spring.factories文件,经过去重、过滤,返回需要装配的配置类集合。
@Override
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return NO_IMPORTS;
}
AutoConfigurationEntry autoConfigurationEntry = getAutoConfigurationEntry(annotationMetadata);
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
我们点进 getAutoConfigurationEntry() 方法:
- getAttributes 获取 @EnableAutoConfiguration 中的 exclude 、 excludeName 等。
- getCandidateConfigurations 获取所有自动装配的配置类,也就是读取 - spring.factories 文件,后面会再次说明。
- removeDuplicates 去除重复的配置项。
- getExclusions 根据 @EnableAutoConfiguration 中的 exclude 、 - excludeName 移除不需要的配置类。
- fireAutoConfigurationImportEvents 广播事件。
最后根据多次过滤、判重返回配置类合集。
现在我们结合 getAutoConfigurationEntry() 的源码来详细分析一下:
第 1 步:判断自动装配开关是否打开。
默认
spring.boot.enableautoconfiguration=true ,可在 application.properties 或 application.yml 中设置。
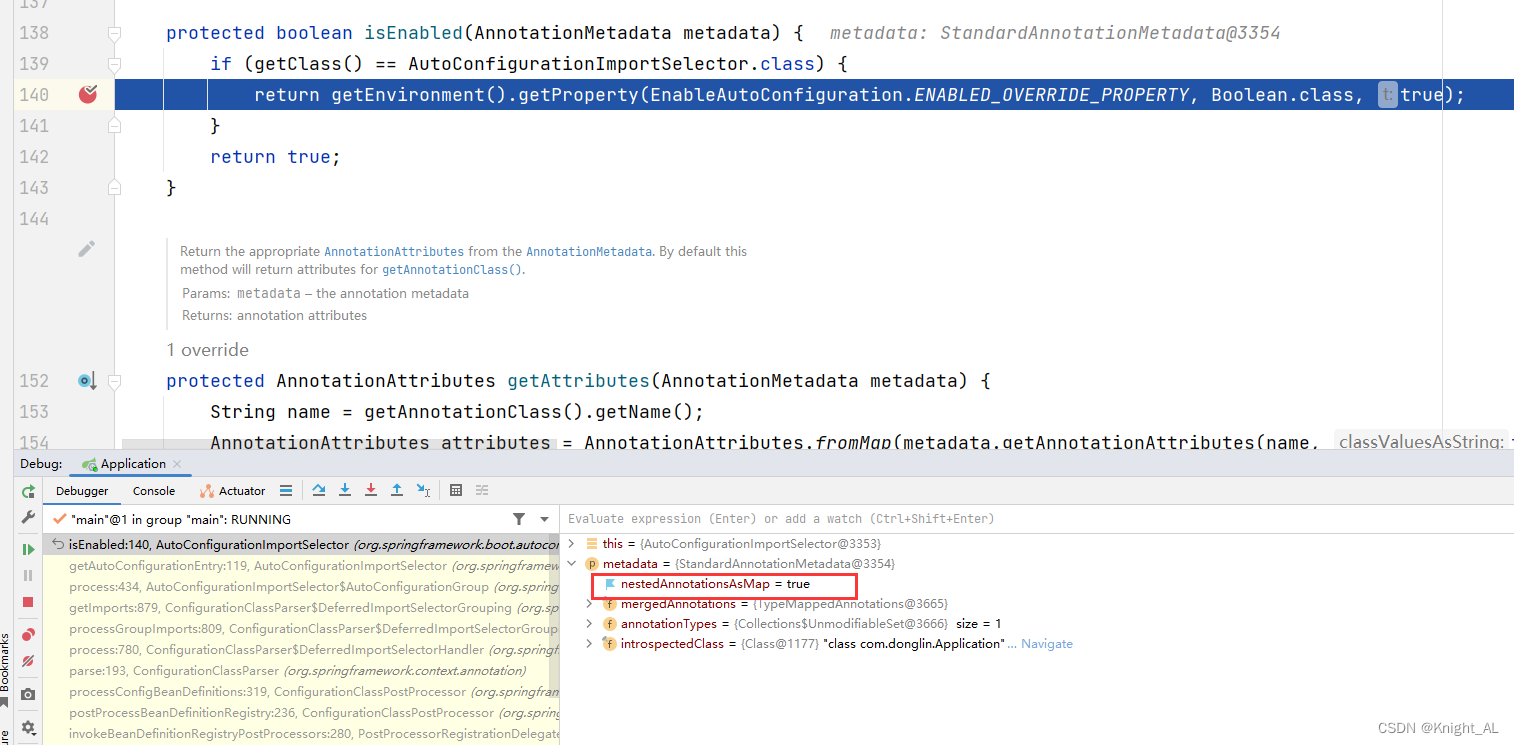
第 2 步 :
用于获取 EnableAutoConfiguration 注解中的 exclude 和 excludeName 。
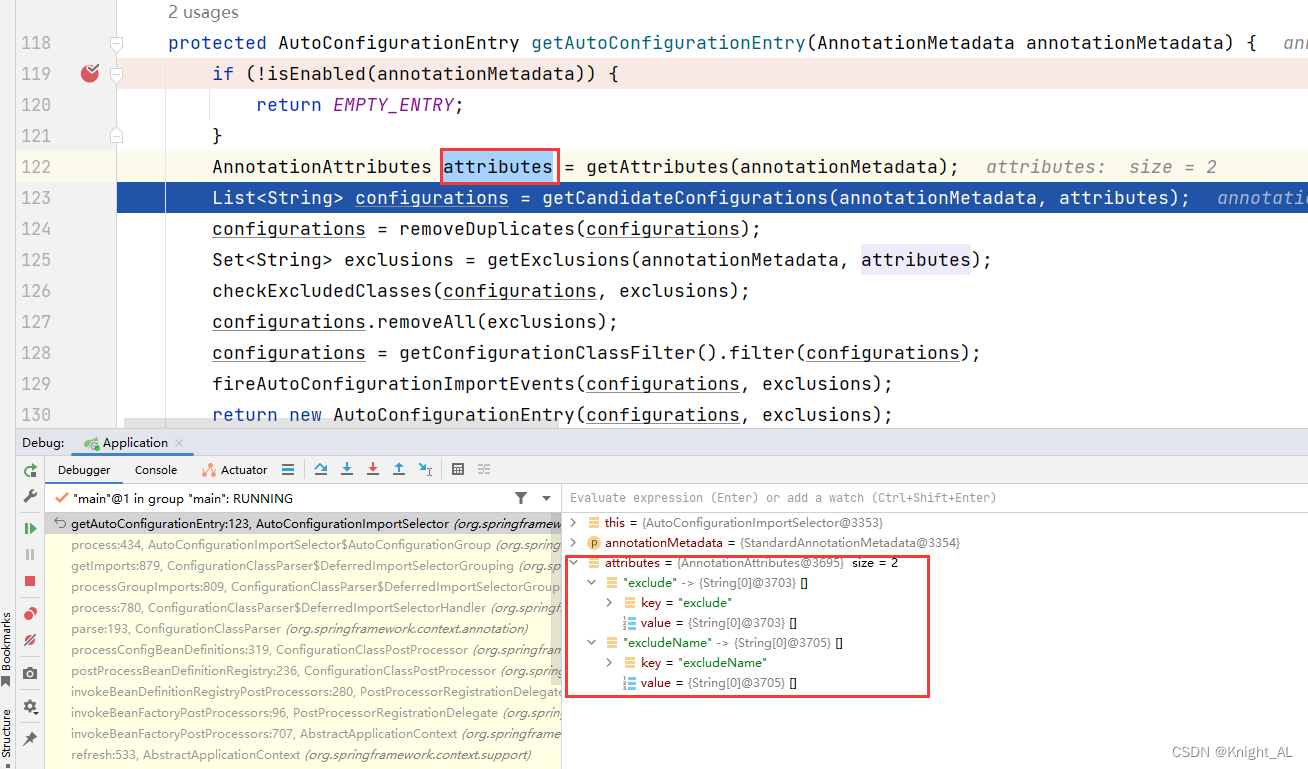
第 3 步:
获取需要自动装配的所有配置类,读取 META-INF/spring.factories 。

我们点进
getCandidateConfigurations() 方法:
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
获取候选配置了使用了 Spring Framework 自定义的 SPI 机制,使用 SpringFactoriesLoader#loadFactoryNames 加载了类路径下
/META-INF/spring.factories 文件中的配置类,里面是以 key/value 形式存储,其中一个 key 是 EnableAutoConfiguration 类的全类名,而它的 value 是一个以 AutoConfiguration 结尾的类名的列表。以 spring-boot-autoconfigure 模块为例,其 spring.factories 内容如下。
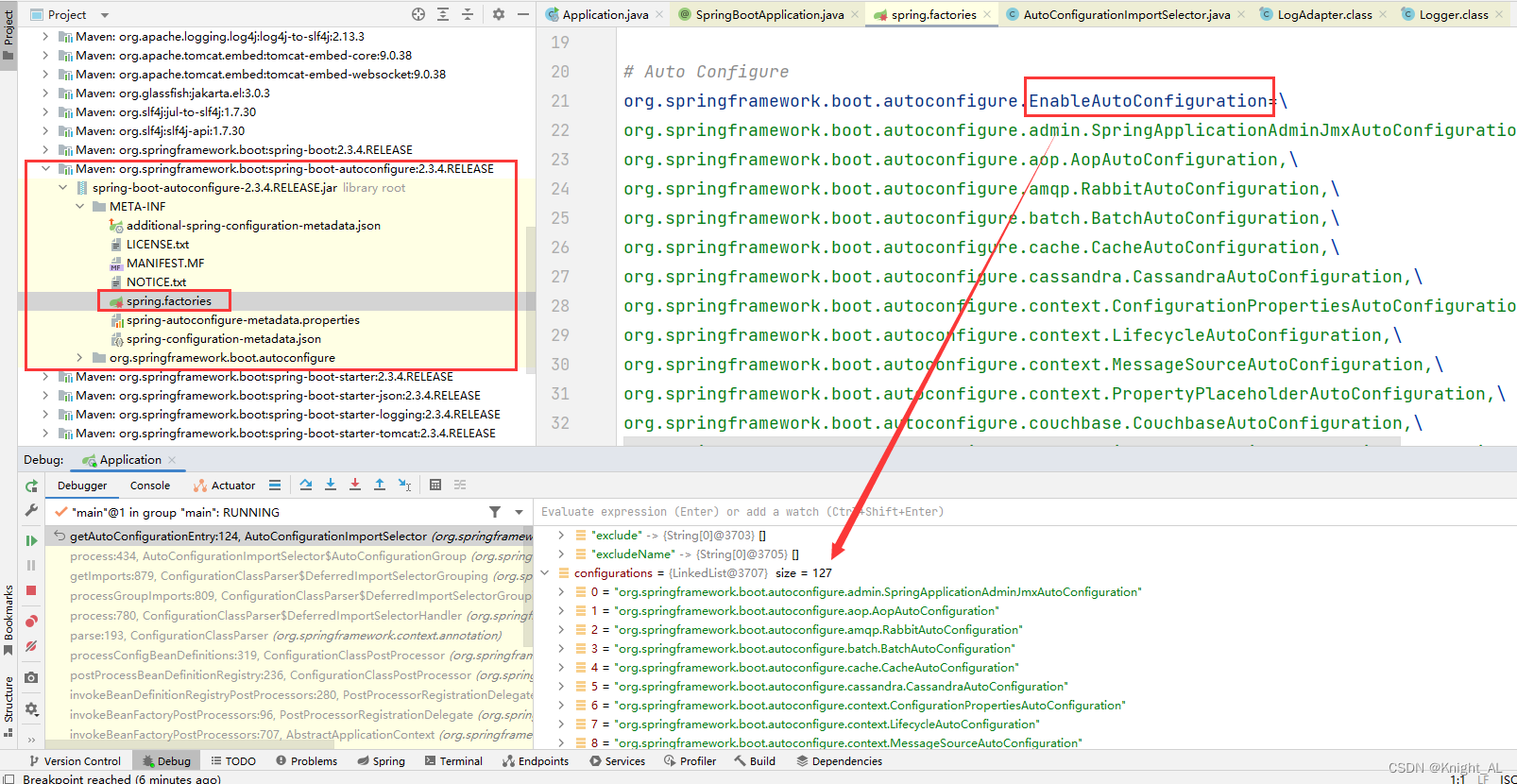
不光是这个依赖下的 META-INF/spring.factories 被读取到,所有 Spring Boot Starter 下的 META-INF/spring.factories 都会被读取到。
如果,我们自定义一个 Spring Boot Starter,就需要创建 META-INF/spring.factories 文件。
第 4 步 :
到这里可能面试官会问你:“ spring.factories 中这么多配置,每次启动都要全部加载么?”。
很明显,这是不现实的。我们 debug 到后面你会发现, configurations 的值变小了。
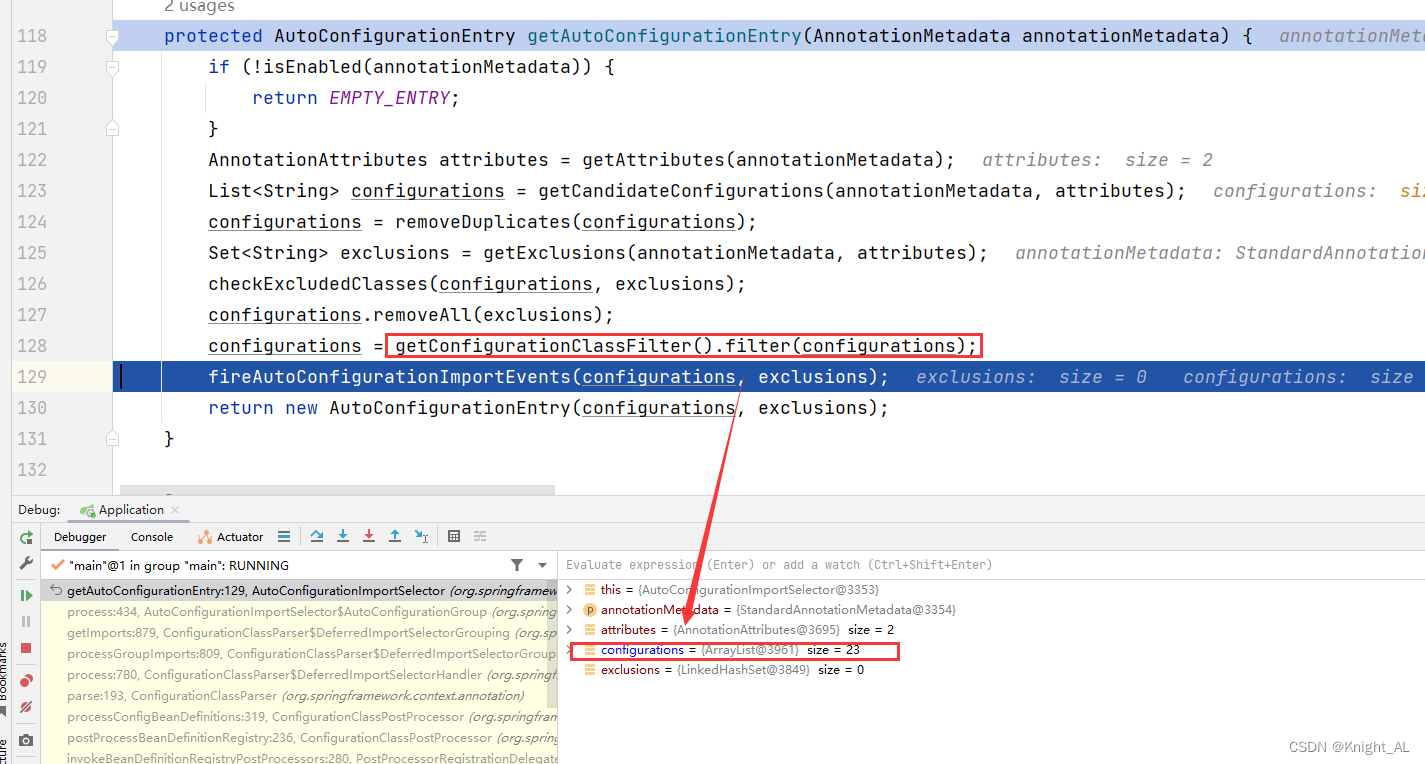
虽然 127 个全场景配置项的自动配置启动的时候默认全部加载。但实际经过后续处理后只剩下 23 个配置项真正加载进来。很明显,Spring Boot 只会加载实际你要用到的场景中的配置类。这是如何做到的了?
按需加载
这里我们分析剩下的 23 个自动配置类,观察到每一个自动配置类都有着 @Conditional 或者其派生条件注解。
@ConditionalOnBean:当容器里有指定 Bean 的条件下
@ConditionalOnMissingBean:当容器里没有指定 Bean 的情况下
@ConditionalOnSingleCandidate:当指定 Bean 在容器中只有一个,或者虽然有多个但是指定首选 Bean
@ConditionalOnClass:当类路径下有指定类的条件下
@ConditionalOnMissingClass:当类路径下没有指定类的条件下
@ConditionalOnProperty:指定的属性是否有指定的值
@ConditionalOnResource:类路径是否有指定的值
@ConditionalOnExpression:基于 SpEL 表达式作为判断条件
@ConditionalOnJava:基于 Java 版本作为判断条件
@ConditionalOnJndi:在 JNDI 存在的条件下差在指定的位置
@ConditionalOnNotWebApplication:当前项目不是 Web 项目的条件下
@ConditionalOnWebApplication:当前项目是 Web 项 目的条件下
@Configuration(
proxyBeanMethods = false
)
// 检查是否有该类才会进行加载
@ConditionalOnClass({
RedisOperations.class})
// 绑定默认配置信息
@EnableConfigurationProperties({
RedisProperties.class})
@Import({
LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class})
public class RedisAutoConfiguration {
public RedisAutoConfiguration() {
}
...
}
所以当 classpath 下存在某一个 Class 时,某个配置才会生效。
上面所有的注解都在做一件事:注册 bean 到 Spring 容器。他们通过不同的条件不同的方式来完成:
@SpringBootConfiguration 通过与 @Bean 结合完成 Bean 的 JavaConfig 配置;
- @ComponentScan 通过范围扫描的方式,扫描特定注解注释的类,将其注册到 Spring 容器;
- @EnableAutoConfiguration 通过 spring.factories 的配置,并结合 @Condition 条件,完成bean的注册;
- @Import 通过导入的方式,将指定的 class 注册解析到 Spring 容器;
我们在这里画张图把 @SpringBootApplication 注解包含的几个注解分别解释一下。
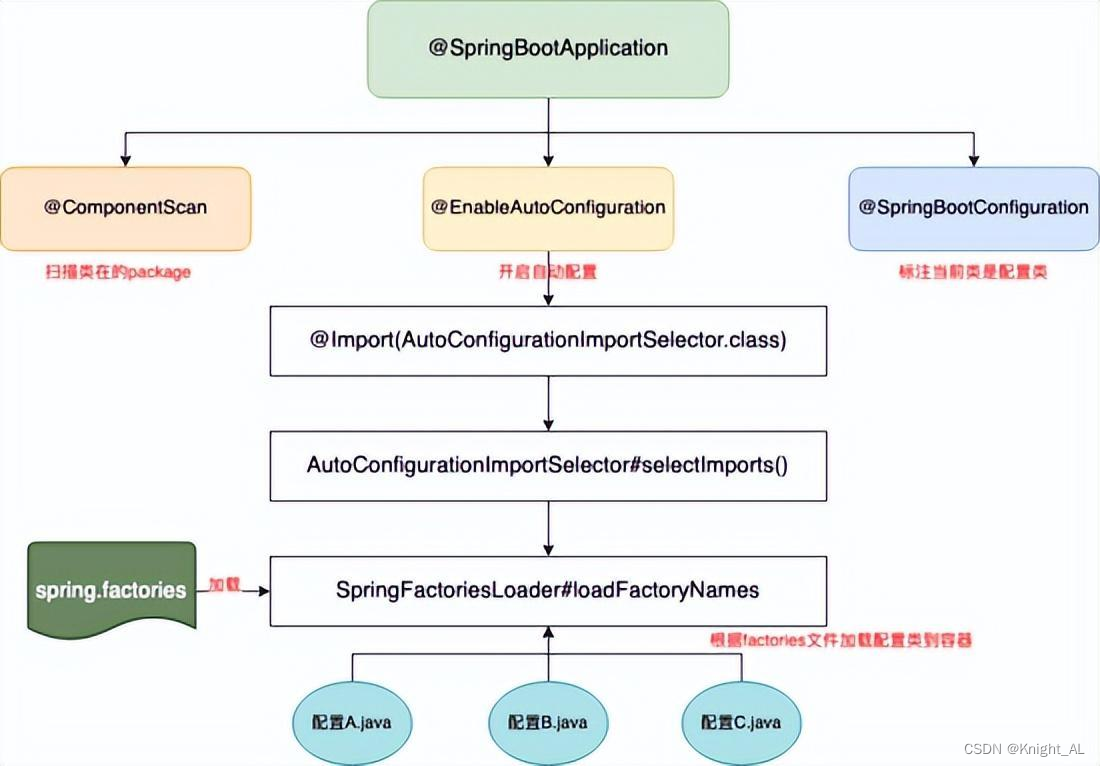
Spring Boot 通过 @EnableAutoConfiguration 开启自动装配,通过 SpringFactoriesLoader 最终加载 META-INF/spring.factories 中的自动配置类实现自动装配,自动配置类其实就是通过 @Conditional 按需加载的配置类,想要其生效必须引入 spring-boot-starter-xxx 包实现起步依赖。
2.SpringBoot 中你们是如何加载配置信息的?
Spring Boot 通过 @EnableAutoConfiguration 开启自动装配,通过 SpringFactoriesLoader 最终加载 META-INF/spring.factories 中的自动配置类实现自动装配,自动配置类其实就是通过 @Conditional 按需加载的配置类,想要其生效必须引入 spring-boot-starter-xxx 包实现起步依赖。
3.RabbitMQ 如何保证消息不丢失?
首先明确一点一条消息的传送流程:生产者->MQ->消费者
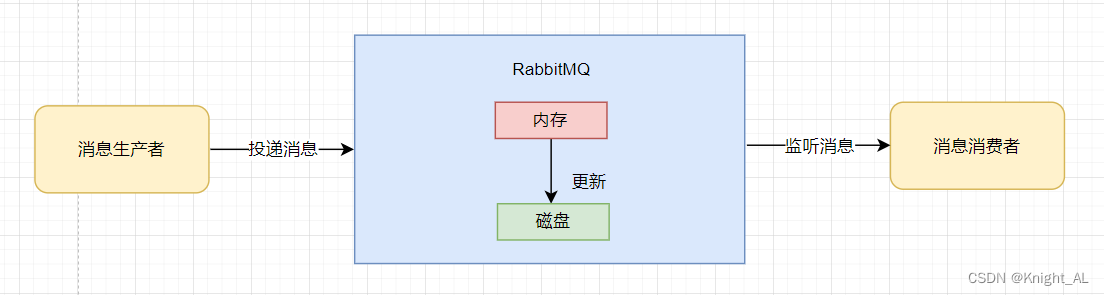
我们根据这三个依次讨论
1.生产者没有成功把消息发送到MQ
丢失的原因:因为网络传输的不稳定性,当生产者在向MQ发送消息的过程中,MQ没有成功接收到消息,但是生产者却以为MQ成功接收到了消息,不会再次重复发送该消息,从而导致消息的丢失。
解决办法 :有两个解决办法:事务机制和confirm机制,最常用的是confirm机制。
事务机制和cnofirm机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是confirm机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息rabbitmq接收了之后会异步回调你一个接口通知你这个消息接收到了。
我们就谈谈confirm return(扩展)
rabbitmq 整个消息投递的路径为:
producer—>rabbitmq broker—>exchange—>queue—>consumer
消息从 producer 到 exchange 则会返回一个 confirmCallback 。
消息从 exchange–>queue 投递失败则会返回一个 returnCallback 。
confirm:使用 rabbitTemplate.setConfirmCallback 设置回调函数。当消息发送到 exchange 后回调 confirm 方法。在方法中判断 ack,如果为true,则发送成功,如果为false,则发送失败,需要处理。
return:使用 rabbitTemplate.setReturnCallback 设置退回函数,当消息从exchange 路由到 queue 失败后,如果设置了 rabbitTemplate.setMandatory(true) 参数,则会将消息退回给 producer并执行回调函数returnedMessage
2.RabbitMQ接收到消息之后丢失了消息
丢失的原因:RabbitMQ接收到生产者发送过来的消息,是存在内存中的,如果没有被消费完,此时RabbitMQ宕机了,那么再次启动的时候,原来内存中的那些消息都丢失了。
解决方案:开启RabbitMQ的持久化。当生产者把消息成功写入RabbitMQ之后,RabbitMQ就把消息持久化到磁盘。(持久化要起作用必须同时设置这两个持久化才行)
- 持久化可以跟生产者那边的confirm机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者ack了,所以哪怕是在持久化到磁盘之前,rabbitmq挂了,数据丢了,生产者收不到ack,你也是可以自己重发的。
- 若生产者那边的confirm机制未开启的情况下,哪怕是你给rabbitmq开启了持久化机制,也有一种可能,就是这个消息写到了rabbitmq中,但是还没来得及持久化到磁盘上,结果不巧,此时rabbitmq挂了,就会导致内存里的一点点数据会丢失。
3.消费者弄丢了消息
丢失的原因:如果RabbitMQ成功的把消息发送给了消费者,那么RabbitMQ的ack机制会自动的返回成功,表明发送消息成功,下次就不会发送这个消息。但如果就在此时,消费者还没处理完该消息,然后宕机了,那么这个消息就丢失了。
解决的办法:简单来说,就是必须关闭 RabbitMQ 的自动 ack
none:自动确认,manual:手动确认
如果在消费端没有出现异常,则调用channel.basicAck(deliveryTag,true);方法确认签收消息
如果出现异常,则在catch中调用 basicNack,拒绝消息,让MQ重新发送消息。
4.如果消费者这边消费到一半宕机了怎么办?
消费者弄丢了消息
丢失的原因:如果RabbitMQ成功的把消息发送给了消费者,那么RabbitMQ的ack机制会自动的返回成功,表明发送消息成功,下次就不会发送这个消息。但如果就在此时,消费者还没处理完该消息,然后宕机了,那么这个消息就丢失了。
解决的办法:简单来说,就是必须关闭 RabbitMQ 的自动 ack
none:自动确认,manual:手动确认
如果在消费端没有出现异常,则调用channel.basicAck(deliveryTag,true);方法确认签收消息
如果出现异常,则在catch中调用 basicNack,拒绝消息,让MQ重新发送消息。
5.RabbitMQ 如何保证消息没有被重复消费?
首先,比如rabbitmq、rocketmq、kafka,都有可能会出现消息重复消费的问题。因为这个问题通常不是由mq来保证的,而是消费方自己来保证的。
那就要想到幂等性
幂等性指一次和多次请求某一个资源,对于资源本身应该具有同样的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
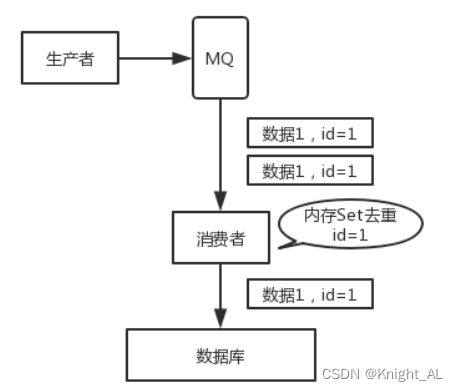
(1)可在内存中维护一个set,只要从消息队列里面获取到一个消息,先查询这个消息在不在set里面,如果在表示已消费过,直接丢弃;如果不在,则在消费后将其加入set当中。
(2)如何要写数据库,可以拿唯一键先去数据库查询一下,如果不存在在写,如果存在直接更新或者丢弃消息。
(3)如果是写redis那没有问题,每次都是set,天然的幂等性。
(4)让生产者发送消息时,每条消息加一个全局的唯一id,然后消费时,将该id保存到redis里面。消费时先去redis里面查一下有么有,没有再消费。
(5)数据库操作可以设置唯一键,防止重复数据的插入,这样插入只会报错而不会插入重复数据。
6.JVM 运行时区域有哪几块?

7.JVM 垃圾回收算法了解吗?有哪几种?
标记-清除算法
复制算法
标记-压缩算法

https://donglin.blog.csdn.net/article/details/127831153
8.JVM 是怎么判断一个对象是否可以被回收呢?
引用计数器
对于一个对象A,只要有任何一个对象引用了A ,则A 的引用计数器就加1,当引用失效时,引用计数器就减1。只要对象A 的引用计数器的值为0,即表示对象A不可能再被使用,可进行回收。
可达性分析算法
简单来说,就是将对象及其引用关系看作一个图,选定活动的对象作为 GC Roots,然后跟踪引用链条,如果一个对象和GC Roots之间不可达,也就是不存在引用链条,那么即可认为是可回收对象。
9.为什么 HotSpot 虚拟机最终选择了可达性分析而没有选择引用计数法?
优点:实现简单,垃圾对象便于辨识;判定效率高,回收没有延迟性。
缺点:
缺点1:它需要单独的字段存储计数器,这样的做法增加了存储空间的开销。
缺点2:每次赋值都需要更新计数器,伴随着加法和减法操作,这增加了时间开销。
缺点3:引用计数器有一个严重的问题,即无法处理循环引用的情况。这是一条致命缺陷,导致在Java 的垃圾回收器中没有使用这类算法。
10.那你说说有哪些对象可以作为可达性分析中的 GC Root ?
GC Roots 对象包括以下几种:(巧记:两栈两方法)
- 虚拟机栈中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 JNI 引用的对象
https://donglin.blog.csdn.net/article/details/130672896
11.Linux用过吗?说说怎么查看一个进程的进程号?
ps -ef | grep <进程名>
下面是 ps -ef 命令的各个选项的含义:
-e 的全称是 --everyone,表示显示所有进程,包括其他用户的进程。
-f 的全称是 --full,表示显示进程的详细信息,包括进程的 UID、PID、PPID、C、STIME、TTY、TIME、CMD 等。
12.Linux怎么查看正在运行的Java程序的日志?
tail -f <日志文件路径>
13.Linux怎么修改文件的权限?
chmod <权限模式> <文件名>
例如
chmod 777 test.txt
14.命令chomod 777是什么意思?
文件所有者具有读、写和执行权限;
文件所属组具有读、写和执行权限;
其他用户具有读、写和执行权限。
- r(读权限)对应数字 4,表示可以读取文件的内容;
- w(写权限)对应数字 2,表示可以修改文件的内容;
- x(执行权限)对应数字 1,表示可以执行文件或进入目录。
15.一个7就可以代表读写执行权限,为什么有3个7?
777分别是chmod u+rwx,g+rw,o+r(u:user、g:group、o:others )
第一个 7 表示文件所有者的权限,第二个 7 表示文件所属组的权限,第三个 7 表示其他用户的权限。


![[架构之路-199] - 可靠性需求与可靠性分析:鱼骨图、故障树分析法FTA、失效模式与影响DFMEA,找到影响故障的主要因素](https://img-blog.csdnimg.cn/img_convert/1fa4c3912a26a0152e477ee4a015cf69.jpeg)