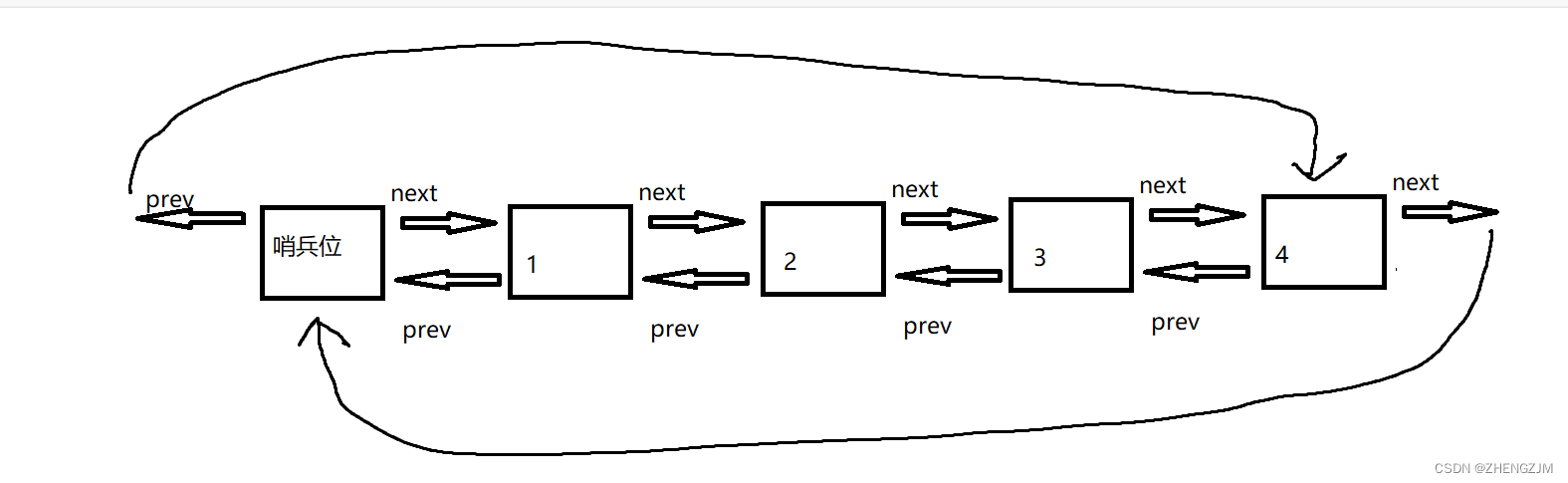
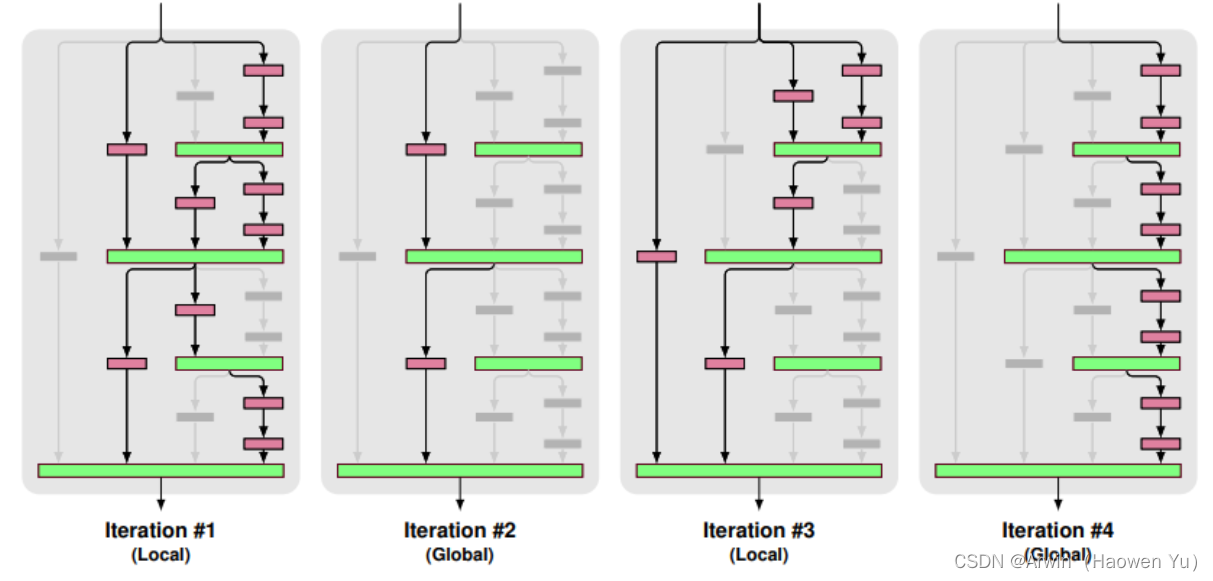
一、前言
本文基于谷歌的:《Introduction to Generative AI》 并且借助 ChatGPT 整理而成,帮助大家理解生成式 AI 这个概念。


主要包括 4 个部分:
- 生成式 AI 的定义
- 生成式 AI 的工作原理
- 生成式 AI 模型的分类
- 生成式 AI 的应用
二、生成式 AI 介绍
2.1 生成式 AI 的定义
人工智能不等于机器学习
人工智能是关于赋予机器以模拟人类智能的能力的广泛领域。它涉及使计算机系统能够执行类似于人类智能的任务,如语音识别、图像识别、自然语言处理和决策制定等。

人工智能旨在使机器具备像人类一样的推理、学习、问题解决和决策能力。

机器学习是人工智能的一个分支,它是通过数据和统计模型来让机器自动学习和改进的一种方法。机器学习的目标是设计和开发算法,使计算机系统能够从数据中学习,而无需明确地编程。通过训练模型,机器学习使机器能够识别模式、做出预测和进行决策。

简而言之,人工智能是一个更广泛的概念,涵盖了使机器拥有人类智能的目标和技术。机器学习是实现人工智能的一种方法,通过让机器从数据中学习和自动调整模型来实现任务。因此,机器学习是人工智能的一个子集,但人工智能不仅限于机器学习,还包括其他方法和技术。
机器学习中的监督学习和无监督学习

监督学习和无监督学习是机器学习中两种不同的学习方法。

监督学习是一种通过使用带有标签的训练数据来训练模型的学习方法。在监督学习中,训练数据包含输入特征和对应的标签或输出结果。模型通过学习输入特征与标签之间的关系,从而能够对新的未标记数据进行预测。常见的监督学习算法包括线性回归、逻辑回归、决策树和支持向量机等。监督学习适用于需要进行分类、回归和预测等任务。

无监督学习是一种在没有标签的情况下从未标记的数据中自动发现模式和结构的学习方法。在无监督学习中,训练数据不包含标签信息,模型需要通过对数据进行聚类、降维或关联规则挖掘等技术来发现隐藏的结构和模式。无监督学习可以帮助我们理解数据的分布、发现异常点、进行数据可视化和特征提取等。常见的无监督学习算法包括聚类算法(如K均值聚类)、主成分分析(PCA)和关联规则挖掘等。

简而言之,监督学习使用有标签的训练数据来训练模型,并根据已知的输入和输出之间的关系进行预测。无监督学习则是在没有标签的情况下对未标记数据进行学习,通过发现数据中的模式和结构来获得洞察和理解。这两种学习方法在解决不同类型的问题和应用场景中发挥着重要的作用。
深度学习
深度学习是机器学习的分支。

机器学习是一种通过算法和模型让计算机系统从数据中学习的方法。它的目标是使机器能够自动从数据中发现模式、进行预测和做出决策,而无需明确地编程。机器学习算法可以根据给定的输入数据进行学习,并通过调整模型的参数来优化性能。常见的机器学习算法包括线性回归、决策树、支持向量机和随机森林等。

深度学习是机器学习的一个特定领域,它利用人工神经网络模型进行学习和训练。深度学习模型由多个层次(称为神经网络的层)组成,每一层都会对输入数据进行变换和表示。这些网络层通过一系列的非线性转换将输入数据映射到输出结果。深度学习模型的核心是深度神经网络(Deep Neural Network,DNN),它可以通过大量的标记数据进行训练,从而实现高度准确的预测和分类任务。

总的来说,机器学习是一种更通用的学习方法,可以使用各种算法和技术,而深度学习是机器学习的一个特定分支,使用深度神经网络来实现学习和预测。深度学习的主要优势在于它可以自动从原始数据中学习更高级别的特征表示,从而提供更准确和复杂的模型。然而,深度学习通常需要更大规模的数据和更高的计算资源来进行训练,相对于传统机器学习算法而言更为复杂。
生成式 AI 和深度学习的关系

生成式 AI 是深度学习的分支。
判别模型和生成模型
生成式模型主要包括判别模型(Discriminative Model)和生成模型(Generative Model)。
 判别模型(Discriminative Model)和生成模型(Generative Model)是机器学习中两种不同类型的模型,它们的主要区别在于其对数据的建模方式和应用领域。
判别模型(Discriminative Model)和生成模型(Generative Model)是机器学习中两种不同类型的模型,它们的主要区别在于其对数据的建模方式和应用领域。

判别模型是一种直接对条件概率进行建模的模型。它主要关注的是给定输入数据,预测输出类别或标签的概率分布。判别模型通过学习输入和输出之间的关系来建立决策边界,从而对新的输入数据进行分类。常见的判别模型包括逻辑回归、支持向量机和深度神经网络等。判别模型通常用于分类、回归和标注等任务。

生成模型是一种对联合概率分布进行建模的模型。它不仅学习输入和输出之间的关系,还学习了生成输入数据的过程。生成模型可以通过学习数据的分布和特征之间的关系来生成新的样本数据。常见的生成模型包括高斯混合模型(Gaussian Mixture Model,GMM)和生成对抗网络(Generative Adversarial Network,GAN)等。生成模型通常用于生成新的图像、语言模型和数据增强等任务。

判别模型和生成模型的选择取决于具体的问题和任务需求。判别模型更关注分类和预测的准确性,可以直接对输入和输出之间的关系进行建模。而生成模型更关注数据的生成过程,可以模拟数据的分布和生成新的样本。生成模型可以用于生成新的数据,但在分类和预测任务上可能不如判别模型准确。

总的来说,判别模型关注输入和输出之间的关系,用于分类和预测等任务。生成模型关注数据的生成过程,可以生成新的样本数据。选择判别模型还是生成模型应根据具体问题的需求和任务目标来决定。
生成式 AI 的监督、半监督和无监督学习

传统的监督、无监督学习,将训练数据和标注数据喂给模型,可以作出预测、分类和聚类。

生成式 AI 的监督、半监督、无监督学习,将训练数据、打标数据和未打标数据给基础模型,然后生成新的内容,最终实现文本、代码和图片的生成。
生成式 AI 和传统的编程和神经网络的区别

传统的编程方式,需要硬编码来描述猫的一些特征。

神经网络算法可以通过学习是不是猫的样本,然后你给出一张图片它可以判断是否为一个猫。

LaMDA 、PaLM、GPT 等生成式模型在喂了大量内容后,可以直接问猫是什么?它讲给出它所知道的答案。
生成式 AI 的定义

生成式 AI 是什么?
- 生成式 AI 是人工智能的一个分支,可以根据已经学习的内容生成新的内容。
- 从现有的内容中学习的过程叫做训练,训练的结果是创建一个统计模型。
- 当用户给出提示词,生成式 AI 将会使用统计模型去预测答案,生成新的文本来回答问题。
生成式模型的分类

【生成式语言模型】是基于自然语言处理的技术,通过学习语言的规律和模式来生成新的文本。它可以根据之前的上下文和语义理解生成连贯的句子或段落。生成式语言模型的训练基于大规模的文本数据,例如新闻文章、小说或网页内容。通过学习文本中的单词、短语和句子之间的关系,生成式语言模型可以自动生成新的、具有逻辑和语法正确性的文本,如文章、对话和诗歌等。
【生成式图片模型】是基于计算机视觉的技术,通过学习图像的特征和结构来生成新的图像。它可以从之前的训练数据中学习到图像的特征表示和统计规律,然后使用这些知识生成新的图像。生成式图片模型的训练通常基于大规模的图像数据集,例如自然图像或艺术作品。通过学习图像的纹理、颜色、形状和物体之间的关系,生成式图片模型可以生成具有视觉真实感或艺术风格的新图像,如自然风景、人像或抽象艺术作品等。

生成式 AI 输入图片,输出可以是文本(看图说话、可视化问答、图片搜索)、图片(超分辨率,图片修改)和视频(动画)。
super resolution 是超分辨率的英文表达,它是指通过硬件或软件的方法提高原有图像的分辨率,通过一系列低分辨率的图像来得到一幅高分辨率的图像的过程。

生成式 AI 输入是文本,输出可以是文本(翻译、总结、问答、语法纠正)、图片(图片、视频)、音频(文本到发音)、决策(玩游戏)。
2.2 生成式 AI 的工作原理

生成式语言模型学习训练数据中的语言模式,然后给出一些文本,它们将会预测后面的内容是什么。




将用户的输入进入 Transformer 模型的编码器和解码器进行处理,然后在生成式预训练模型中进行处理,最终将结果输出给用户。
预训练:
- 海量数据
- 数十亿参数
- 无监督学习

模型通过学习大量的文本数据,尝试预测下一个单词或短语。然而,有时候模型会生成一些不符合语法规则或意义不明的词语或短语,这被称为"幻觉(hallucinations)"。

幻觉可以视为模型在生成过程中的错误或缺陷,可能由于训练的数据量不够、模型的训练数据质量差、没有给模型足够的上下文、没有给模型足够的约束导致的。

提示词是作为大语言模型输入的一段文本,它可以以各种方式用来控制模型的输出。

提示词设计是创建提示的过程,从而从大型语言模型中生成期望的输出。正如我们之前提到的,生成 AI 在很大程度上取决于你输入的训练数据。它分析输入数据的模式和结构,生成内容。因此输入的质量决定了输出的质量。
2.3 生成式模型的类型

文本到文本生成模型旨在接收一个文本输入,并生成一个相关的文本输出。这种模型可用于机器翻译、文本摘要、对话生成、故事生成等任务。生成模型可以学习从输入到输出的映射关系,以生成具有语义和语法正确性的新文本。
常见应用场景:
- 机器翻译:将一种语言的文本翻译成另一种语言。
- 文本摘要:从长篇文本中生成简洁的摘要或概括。
- 对话生成:生成自然流畅的对话,可用于虚拟助手或聊天机器人。
- 故事生成:自动生成连贯、有趣的故事或叙述。

文本到图像生成模型接收一个文本描述作为输入,并生成对应的图像输出。这种模型可以将自然语言描述转化为视觉内容,用于图像生成、图像标注、图像编辑等任务。通过学习文本描述和图像之间的语义关联,模型可以生成与文本描述相匹配的图像。
常见应用场景:
- 图像生成:根据文本描述生成与之相匹配的图像。
- 图像标注:将图像描述转化为自然语言标注。
- 图像编辑:通过文本指令实现图像编辑,如添加、修改或删除特定内容。

文本到视频或三维生成模型接收一个文本输入,并生成相应的视频或三维模型输出。这些模型可以用于视频生成、场景合成、三维模型生成等任务。模型可以学习从文本描述到视频序列或三维模型的转换过程,生成与文本描述相符的动态视频或立体模型。
常见应用场景:
- 视频生成:根据文本描述生成与之相符的动态视频。
- 场景合成:根据文本描述生成三维场景或虚拟现实体验。
- 三维模型生成:根据文本描述生成具有特定属性或形状的三维模型。

文本到任务生成模型旨在根据文本输入执行特定任务。这些模型可以接收自然语言指令或问题,并生成相应的任务执行结果。例如,问答生成模型可以接收问题,并生成相应的答案;代码生成模型可以接收自然语言描述,并生成相应的代码实现。这种模型能够将文本指令转化为任务执行的具体操作。
常见应用场景:
- 问答生成:根据问题生成相应的答案或解决方案。
- 代码生成:将自然语言描述转化为代码实现。
- 指令执行:根据自然语言指令执行特定的任务,如图像处理、数据操作等。


模型花园:Google Vertex AI 中有很多语言和视觉方面的基础模型可以选择。

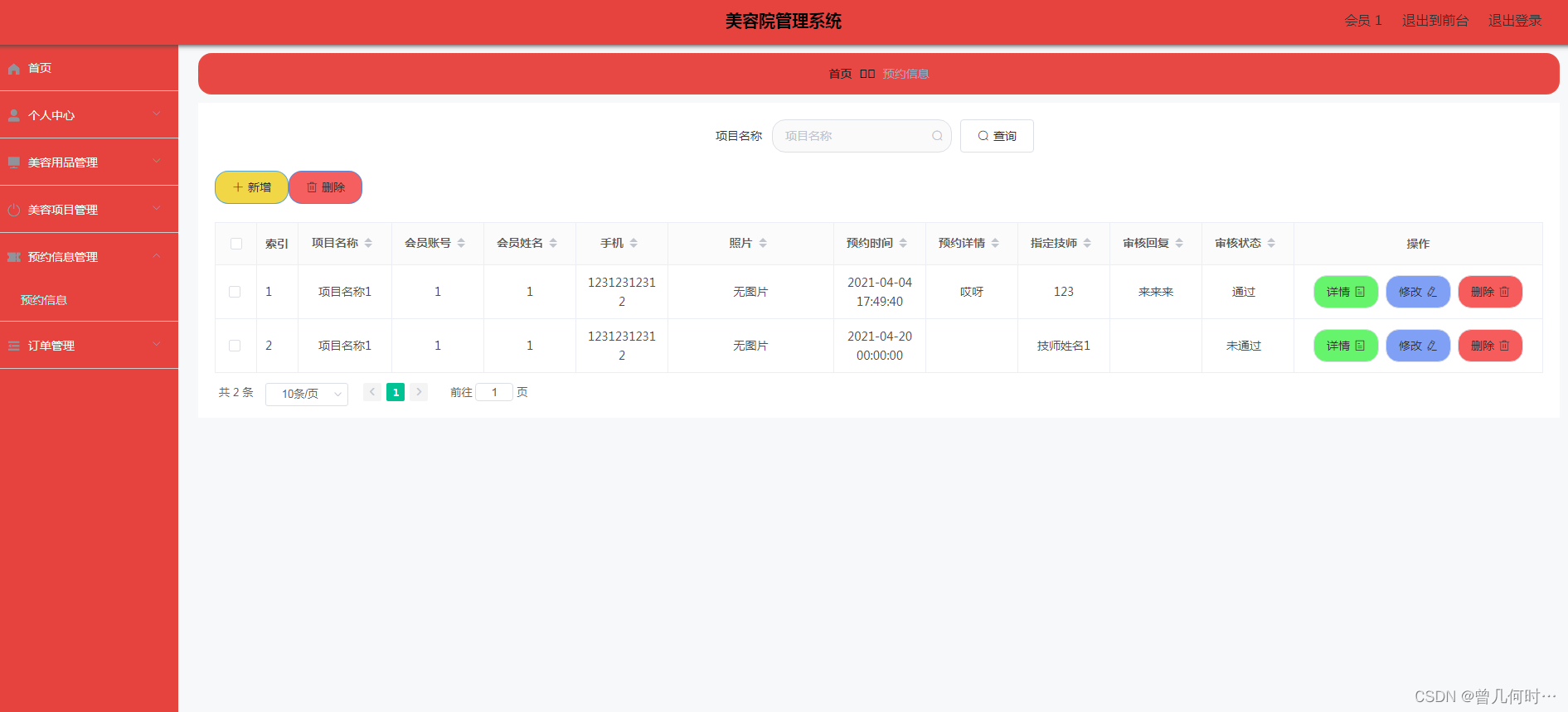
2.4 生成式 AI 应用

生成式 AI 在文本(生成写作、AI 笔记、销售文案、聊天机器人、邮件编写等)、代码(代码生成、代码文档、文本转SQL、Web 应用构建等)、图片、发音、视频、3D 等领域都有大量的市场。
Bard 代码生成演示:



Bard 代码生成能力:

GenAI Studio 介绍:

生成式 AI App 构建器不需要任何编码就可以可以帮助你构建 AI 应用。

PaLM API 和 MakerSuite 可以简化生成式开发更容易。


创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。

欢迎加入我的知识星球,知识星球ID:15165241 一起交流学习。
https://t.zsxq.com/Z3bAiea 申请时标注来自CSDN。