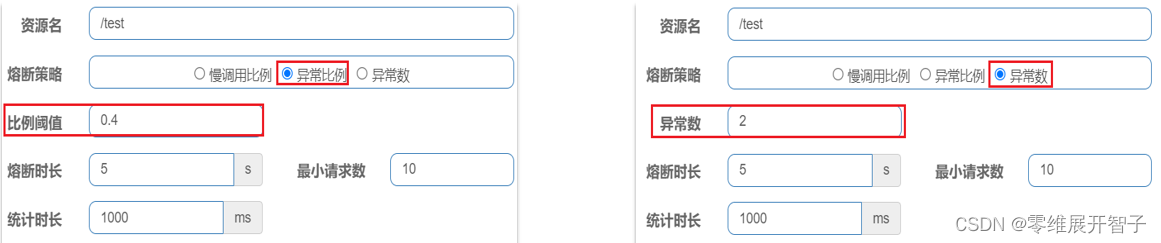
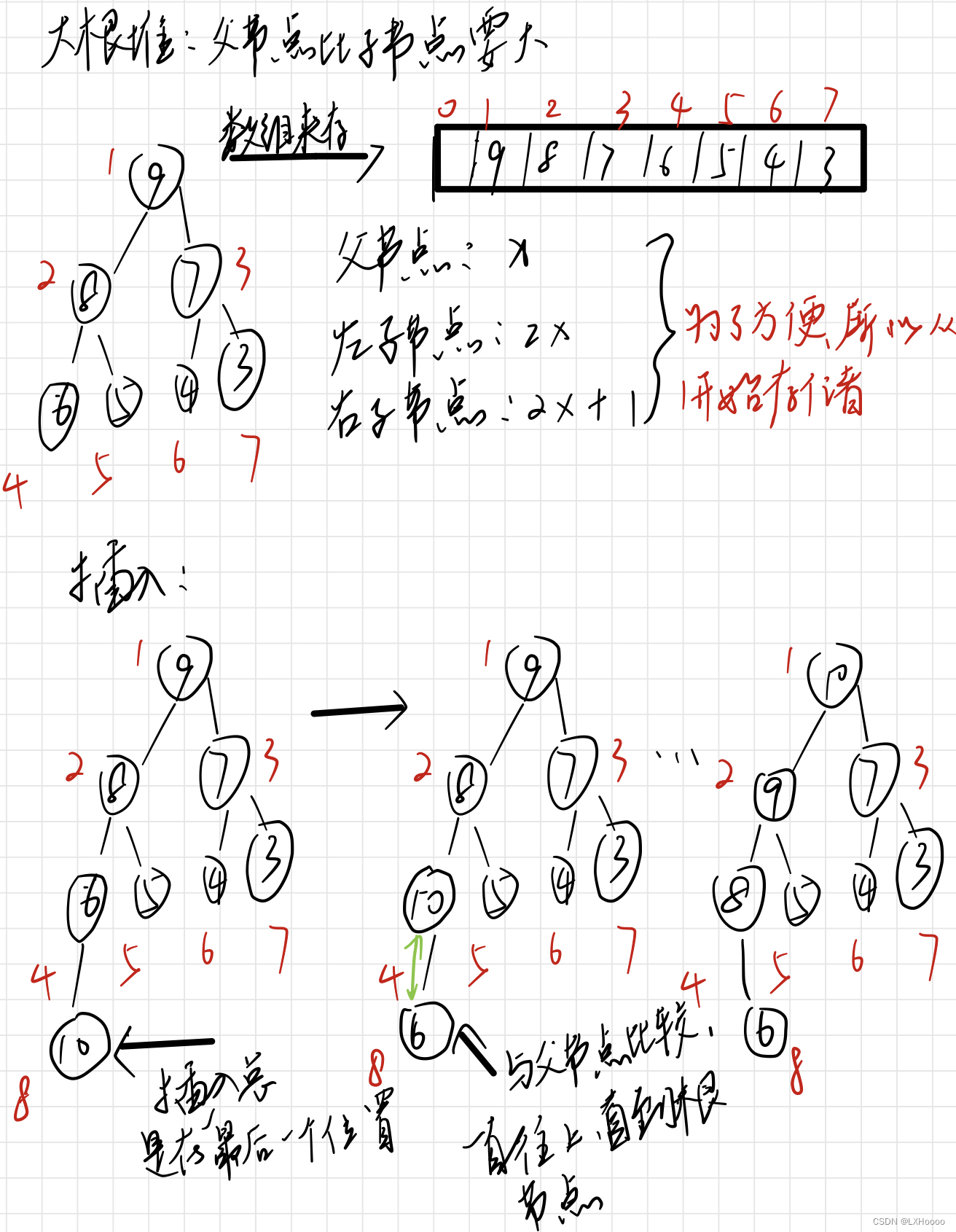
在Pandas中进行数据抽取主要有两种方法,一种是loc方法,一种是iloc方法; 在获取数据时可以获取的数据有三种形式,一种是Series类型,一种是DataFrame类型,还有一种是直接获取数据值; 在进行切片获取数据时,要注意通过索引号来切片是左闭右开,通过索引名来切片就是左闭右闭; import pandas as pd
data = [[109, 107, 100],
[105, 114, 135],
[98, 88, 120],
[145, 150, 130]]
name = ['刘备', '关羽', '张飞', '诸葛亮']
columns = ['语文', '数学', '英语']
df = pd.DataFrame(
data=data,
index=name,
columns=columns)
获取df中行索引为刘备的所有数据 获取df中行索引为刘备,列索引为数学的数据
df.loc[‘刘备’,‘数学’] # 这种方法获取的是Series数据类型 df.loc[[‘刘备’],[‘数学’]] # 这种方法获取的是DateFrame数据类型 获取df中指定行的数据:
df.loc[‘刘备’:‘诸葛亮’] # 这种方法会包含行索引为诸葛亮的一行,且返回数据是DataFrame类型 获取df中指定列的数据:
df[[‘语文’, ‘数学’]] # 这种方法直接用列索引名 df.loc[:, [‘语文’, ‘数学’]] # 这种方法是通过loc方法实现的 获取指定行列的数据
法一:df.loc[[‘关羽’,‘刘备’], [‘数学’, ‘英语’]] 法二: 获取df中行索引为0的数据,也会有两种返回数据,关键看参数书写时是一维列表还是二维列表 获取df中行索引为0,列索引也为0的数据:df.iloc[0,0] # 返回值是一个数据 获取df中第0行和第1行的所有数据:df.iloc[0:2] 获取df中第1行到第2行的所有数据:df.iloc[1:3, 0:] 获取df中第一行到最后一行和指定列的数据:df.iloc[1:,[0,1,2]] 语文大于105且数学大于88:df.loc[(df[‘语文’] > 105) & (df[‘数学’] > 88)] # 这种加条件筛选的只能用loc这种方法