文章目录
- 一、Keras与tf.keras?
- 二、keras中Model的使用
- 三、使用Keras来实现DCGan
- 1、导入必要的包
- 2.指定模型输入维度:图像尺寸和噪声向量 的长度
- 3、构建生成器
- 4、构造鉴别器
- 5、构建并编译DCGan
- 6、对模型进行训练
- 7、显示生成图像
- 8、运行模型
- 总结
一、Keras与tf.keras?
这个博客简单明了
前两篇文章可以看看,会通透很多。
Keras是一个高级API,不过如果我们想要自定义损失函数或者其他,只能使用Tensorflow来定义
tf,keras包含了所有Keras API,所以,我们最好还是使用tf.keras
二、keras中Model的使用
见此篇博客
三、使用Keras来实现DCGan
在这里使用的是Minst 手写数据集
我是在colab实现的,具体的版本如下:
1、导入必要的包
代码如下(示例):
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import mnist
from keras.layers import Activation, BatchNormalization, Dense, Dropout, Flatten, Reshape
from keras.layers import LeakyReLU
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.models import Sequential
from keras.optimizers import Adam
2.指定模型输入维度:图像尺寸和噪声向量 的长度
代码如下(示例):
img_rows = 28
img_cols = 28
channels = 1
# 输入图像的维度
img_shape = (img_rows, img_cols, channels)
# 噪声向量Z的长度
z_dim = 100
3、构建生成器
解释:生成器其实是一个卷积的逆过程,卷积网络一般被用于图像分类中,在卷积的过程中,我们不断的减少宽高提升通道数,但是在生成器中,我们输入的是一个随机向量,我们需要让它最终输出一个图像,这里输出的是28**28*1的灰度图。
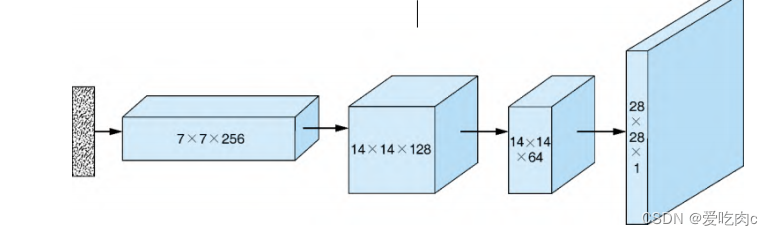
综合所有步骤如下。
(1)取一个随机噪声向量 ,通过全连接层将其重塑为7×7×256
张量。
(2)使用转置卷积,将7×7×256张量转换为14×14×128张量。
(3)应用批归一化和LeakyReLU激活函数。
(4)使用转置卷积,将14×14×128张量转换为14×14×64张
量。注意:宽度和高度尺寸保持不变。可以通过将
Conv2DTranspose中的stride参数设置为1来实现。
(5)应用批归一化和LeakyReLU激活函数。
(6)使用转置卷积,将14×14×64张量转换为输出图像大小
28×28×1。
(7)应用tanh激活函数。
def build_generator(z_dim):
#序列化model
model = Sequential()
# 通过全连接层将输入重新调整大小7*7*256的张量
model.add(Dense(256 * 7 * 7, input_dim=z_dim))
model.add(Reshape((7, 7, 256)))
# 通过转置卷积层将7*7*256的张量转换为14*14*128的张量
model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过转置卷积层将14*14*128的张量转换为14*14*64的张量
model.add(Conv2DTranspose(64, kernel_size=3, strides=1, padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过转置卷积层将14*14*64的张量转换为28*28*1的张量
model.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding='same'))
# 带有tanh激活函数的的输出层
model.add(Activation('tanh'))
return model
4、构造鉴别器
鉴别器与普通的卷积神经网络用来进行图像分类没什么区别,输入图像,输出一个值用来判断图像真伪。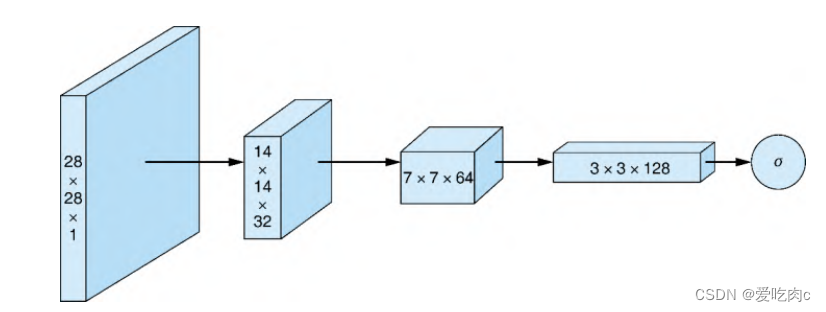
综合所有步骤如下。
(1)使用卷积层将28×28×1的输入图像转换为14×14×32的张
量。
(2)应用LeakyReLU激活函数。
(3)使用卷积层将14×14×32的张量转换为7×7×64的张量。
(4)应用批归一化和LeakyReLU激活函数。
(5)使用卷积层将7×7×64的张量转换为3×3×128的张量。
(6)应用批归一化和LeakyReLU激活函数。
(7)将3×3×128张量展成大小为3×3×128=1152的向量。
(8)使用全连接层,输入sigmoid激活函数计算输入图像是否真
实的概率。
def build_discriminator(img_shape):
model = Sequential()
# 通过卷积层将大小为28*28*1的张量转变为14*14*32的张量
model.add(Conv2D(32, kernel_size=3,strides=2, input_shape=img_shape,padding='same'))
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过卷积层将大小为14*14*32的张量转变为7*7*64的张量
model.add(
Conv2D(64,
kernel_size=3,
strides=2,
input_shape=img_shape,
padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过卷积层将7*7*64的张量转变为3*3*128的张量
model.add(
Conv2D(128,
kernel_size=3,
strides=2,
input_shape=img_shape,
padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 带有sigmoid激活函数的输出层
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
return model
5、构建并编译DCGan
def build_gan(generator, discriminator):
model = Sequential()
# 将生成器和鉴定器结合到一起
model.add(generator)
model.add(discriminator)
return model
# 构建并编译鉴定器(使用了二元交叉熵作为损失函数,Adam的优化算法)
discriminator = build_discriminator(img_shape)
discriminator.compile(loss='binary_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
# 构建生成器
generator = build_generator(z_dim)
# 在生成器训练的时候,将鉴定器的参数固定
discriminator.trainable = False
#构建并编译固定的鉴定器的GAN模型,并训练生成器
gan = build_gan(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam())
# 在生成器训练的时候,将鉴定器的参数固定
discriminator.trainable = False
#构建并编译固定的鉴定器的GAN模型,并训练生成器
gan = build_gan(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam())
6、对模型进行训练
losses = []
accuracies = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
# 导入mnist数据集
(X_train, _), (_, _) = mnist.load_data()
# 灰度像素值从[0,255]缩放到[-1, 1]
X_train = X_train / 127.5 - 1.0
X_train = np.expand_dims(X_train, axis=3)
# 真实图像的标签都为1
real = np.ones((batch_size, 1))
# 假图像的标签都为0
fake = np.zeros((batch_size, 1))
for iteration in range(iterations):
# -------------------------
# 训练鉴定器
# -------------------------
# 抽取真实图像的一个批次
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 生成一批次的假图像
z = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(z)
# 训练鉴定器
d_loss_real = discriminator.train_on_batch(imgs, real)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# 训练生成器
# ---------------------
# 生成一批次的假照片
z = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(z)
# 训练生成器
g_loss = gan.train_on_batch(z, real)
if (iteration + 1) % sample_interval == 0:
# 保存损失和准确率以便训练后绘图
losses.append((d_loss, g_loss))
accuracies.append(100.0 * accuracy)
iteration_checkpoints.append(iteration + 1)
# 输出训练过程
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" %
(iteration + 1, d_loss, 100.0 * accuracy, g_loss))
# 输出生成图像的采样
sample_images(generator)
7、显示生成图像
为完整起见,清单4.7包含了sample_images()函数,它在指定的
训练迭代中输出一个4×4的图像网格。
def sample_images(generator, image_grid_rows=4, image_grid_columns=4):
# 样本的随机噪声(4*4张的合成图)
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, z_dim))
# 从随机噪声中生成图像
gen_imgs = generator.predict(z)
# 将图像像素值重新缩放为[0,1]内
gen_imgs = 0.5 * gen_imgs + 0.5
# 建立图像网格
fig, axs = plt.subplots(image_grid_rows,
image_grid_columns,
figsize=(4, 4),
sharey=True,
sharex=True)
cnt = 0
for i in range(image_grid_rows):
for j in range(image_grid_columns):
# 输出一个图像网格
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 1
8、运行模型
# 设置超参数
iterations = 10000
batch_size = 128
sample_interval = 1000
# 训练模型直到指定的迭代次数
train(iterations, batch_size, sample_interval)
总结
遇到的问题:
1、keras的更新
2、TensorFlow中padding卷积的两种方式“SAME”和“VALID”与我之前学习过的深度学习不同。tensorflow见此
3、numpy中expand_dims()函数详解
4、np.random.randint()的用法