目录
1. 认识URL
2. urlencode和urldecode
urlencode例子:
urldecode例子:
3. HTTP协议格式
3.1 HTTP请求:
3.2 HTTP响应:
3.3 HTTP的方法:
3.4 GET方法和POST方法的区别
3.5 HTTP的状态码:
3.6 HTTP常见Header:
3.7 短链接和长链接
3.9 https:
3.10 加密方式:
3.11 如何防止文本中的内容被篡改,以及识别到是否被篡改:
3.12 加密算法的选择:
3.13 中间人:
3.14 CA证书:
4. 最简单的HTTP服务器
本篇博客详解HTTP✨

应用层协议:客户端和服务器端定了一个约定。只要保证,一端发送时构造的数据,在另一
端能够正确的进行解析,这种协议就是应用层协议;
虽然我们说,应用层协议是我们程序员自己定的;但实际上,已经有大佬们定义了一些现成
的,又非常好用的应用层协议,供我们直接参考使用,HTTP(超文本传输协议)就是其中之
一。
1. 认识URL
当我们使用浏览器时,其实是一个客户端向服务端发送请求并获得响应的过程,并且我们知道服务器后台是用Linux做的(可以常年不关机一直服务,Windows的几天不关机就卡爆了)。
我们想要获取的图片、文本、视频、音频 ... ,这些都可以统称之为 “资源”。在之前的学习中,我们知道 IP+Port 可以确定唯一的一个进程,但现在却无法确定唯一的一个资源!
我们知道公网IP可以确定唯一的一台主机,我们所要请求的网络资源,都一定是存在于网络中的一台Linux服务器上,Linux或者传统的OS,都是以文件的方式保存资源的。在一个Linux机器上,我们可以通过路径找到唯一的一个资源;
所以:IP+Linux路径,就可以唯一的确认一个网络资源
(IP确定是哪台Linux服务器,Linux路径确定唯一的一个资源);
先来看一下URL的简单构成:

从在网络中找到唯一的资源来对URL进行一个分析;
协议方案名:请求该资源时,使用的协议的方法;
登录信息:一般不使用;
服务器地址:Linux服务器的IP地址(以域名的方式呈现);
服务器端口号:一个成熟的协议,一般对应一个固定的服务器端口号;
服务器端口号后面内容:Linux路径(确定唯一的一个网络资源);
2. urlencode和urldecode
用一个例子来进行更好的说明:
在这里我们会使用到一个工具:
编码/解码工具
urlencode例子:

我们在搜索c++时,URL中出现了c%2B%2B;
我们使用编码/解码工具,对c++进行编码发现c++变成了c%2B%2B,这便是urlencode的一个过程;
urldecode例子:
urldecode就是urlencode的逆过程:
我们使用编码/解码工具,对c%2B%2B进行解码发现c%2B%2B变成了c++,这便是urldecode的一个过程;
3. HTTP协议格式
我们先来画一张图使大家对HTTP协议格式有一个大致的了解;
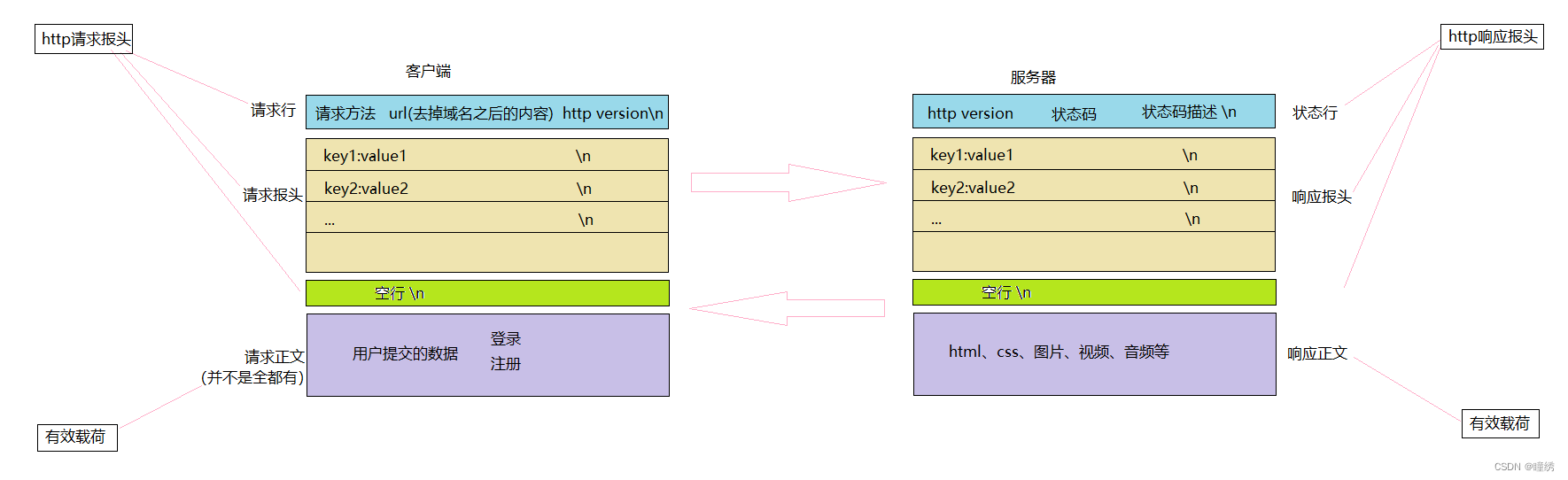
http协议不管是请求还是响应,基本上都是按照行(\n)为单位进行构建请求或者响应的!无论是请求还是响应,几乎都是由3或者4部分组成;
在网络传输时:不管是请求还是响应报文最后都会转化为一个字符串在网络中传输;
使用空行:将报头部分和正文部分进行分开;
3.1 HTTP请求:

- 首行: [方法] + [url] + [版本]
- Header:请求的属性,冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束;
-
Body:空行后面的内容都是Body; Body允许为空字符串,如果Body存在,,则在Header中会有一个 Content-Length属性来标识Body的长度;
3.2 HTTP响应:

- 首行:[版本号] + [状态码] + [状态码解释];
- Header:请求的属性,冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束;
- Body:空行后面的内容都是Body,Body允许为空字符串,如果Body存在,则在Header中会有一个 Content-Length属性来标识Body的长度;如果服务器返回了一个html页面,那么html页面内容就是在 body中;
总结:
不管是HTTP请求还是响应报文,在读取时:读到空行表示报头读取结束,header属性中有Content-Length 表示正文的长度,由此保证了读取HTTP的完整性(不会多读,也不会少读);
3.3 HTTP的方法:
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报头首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
上述方法中最常用的就是GET方法和POST方法;
3.4 GET方法和POST方法的区别
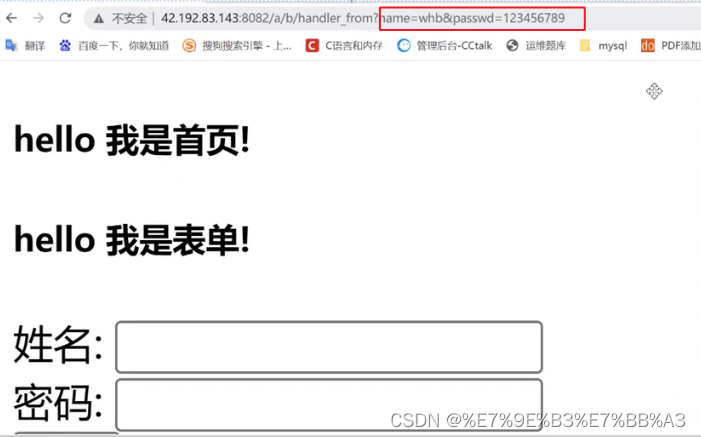
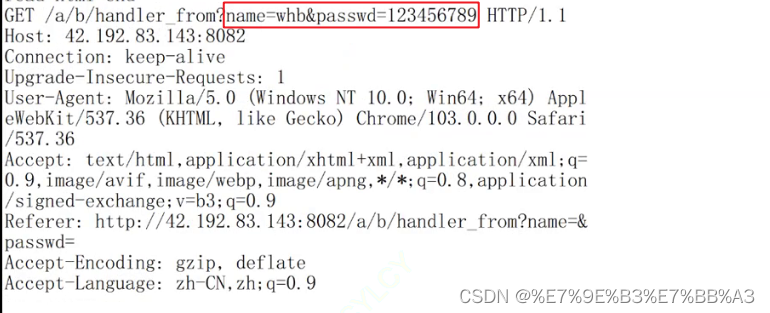
- GET方法:是最常用的获取资源的方法,GET也可以用来提交参数,通过URL来进行参数拼接,从而提交给server端;
- POST方法:是最常用的提交参数的方法,一般是通过正文部分提交参数的;
- POST方法提交参数是比较私密的,不会回显到浏览器的 url 输入框;
- GET方法提交参数是不私密的,会将重要信息回显到 url 的输入框中,增加了被盗取的风险;
在这里要注意的一点是:
- 私密并不意味着安全,我们也可以使用抓包工具获取HTP请求,从而获取提交参数;
- GET方法是通过 url 传参的,而 url 是由大小限制的,和具体的浏览器有关;
- POST方法是由正文部分传参的,一般没有大小限制;
总结:
- 如果我们要提交参数选择POST;如果获取资源选择GET;
GET方法提交参数:
POST方法提交参数:
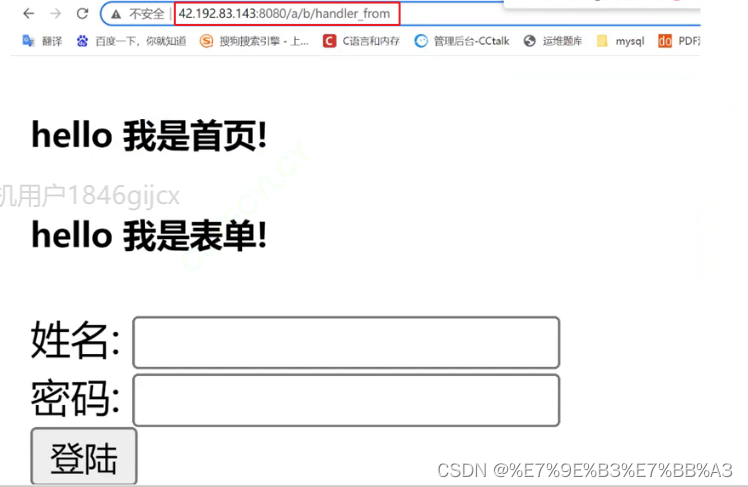
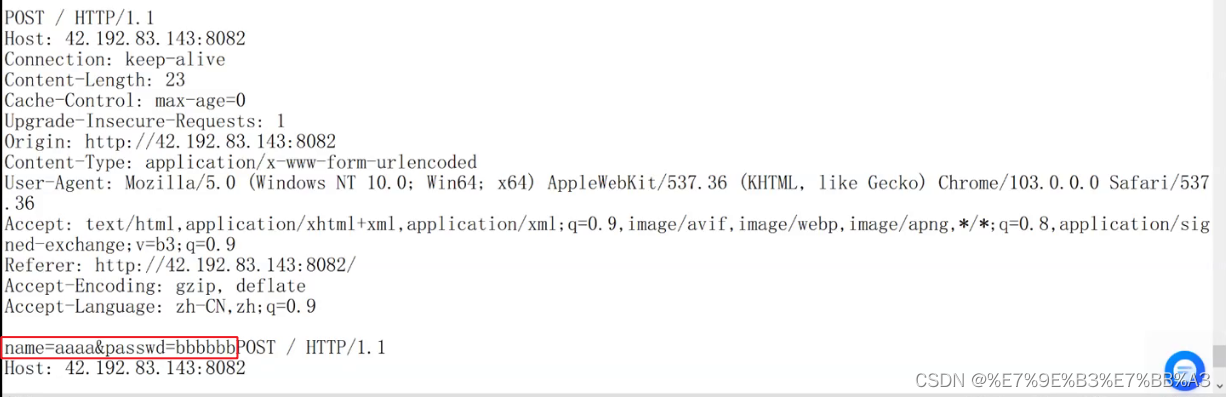
web根目录:
http请求的 / 并不是Linux根目录,而是web根目录 (一个项目的根目录);
如果请求的是 / ,意味着我们要请求该网站的首页(一般所有的网站都要有默认首页的),也就是 /index.html or /index.htm
3.5 HTTP的状态码:
| 类别 | 原因短语 | |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接受的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
应用层是人要参与的,人水平参差不齐,对http的状态码的使用掌握不够,游览器的种类又特别多(有些浏览器对状态码检查严格,有些对状态码检查不严格),导致大家可能对状态码的支持并不是特别好,类似于404的状态码(手动构建请求),对浏览器没有任何指导意义,浏览器还是正常显示网页;
如果404状态码出现,表示该资源找不见,是客户端输入有问题导致的;
在这里重点说明一下3XX的状态码:
3XX的状态码是有特殊含义的,表示重定向:
重定向是需要浏览器给我们提供支持的,浏览器必须识别301、302、307状态码;
server要告诉浏览器,我们要重定向去哪里,Location:表新的地址处;
301 永久重定向
永久重定向一般用于网站搬迁、域名更换;
现有新旧两个网站,一些用户知道新网站,可以直接访问新网站,但还有些老的用户不知道新网站,只知道旧网站,不能直接关闭旧网站(直接关闭会造成老用户找不到网站的情况),这时便可以使用301 ,当老用户访问老网站时,server会告诉浏览器去访问新网站,一般使用标签完成,此过程老用户是不知道的;
302 临时重定向
当我们访问某个网站的时候,会让我们跳转到另一个网址;
具体点说:当我们访问某种资源的时候,提示登录,跳转到了登录页面,输入账号及密码后,会自动跳转回来(美团下单);
3.6 HTTP常见Header:
- Content-Type:数据类型(text/html等);
- Content-Length:Body的长度;
- Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上;
- User-Agent:声明用户的操作系统和浏览器版本信息;
- referer:当前页面是从哪个页面跳转过来的;
- location:搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie:用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
- Connection:属性字段为keep-alive表示长链接;
3.7 短链接和长链接
短链接: http/1.0 采用的网络请求的方案是短链接;经过如下三个阶段:
request -> response -> close;
当客户端向服务器发起一个建立链接请求,服务端对客户端进行响应,然后断开链接,在此过程中,客户端获得一个资源;
一般而言,一个大网页是由多个元素组成的!当问一个大网页的时候 http/1.0 就需要多次进行 http 请求,http 协议是基于 tcp 协议的,tcp 要通信每一次的 http request 都需要执行以下过程:建立连接 —> 传送数据 —> 断开连接,这种频繁的建立 tcp 链接是非常的耗时的!
长链接: http/1.1 支持长链接;
在 headler 属性中,Connection:keep-alive 表示长链接;
如下举了一个长短链接的例子:
当我们点开一个大型网页时,其实是浏览器向server发送请求,server将网页资源发送给客户,大型网页的资源不止一个。当我们使用短链接时,每传输一个资源便要建立一个链接,因此有多少资源便要建立多少次链接;但当我们使用长链接时,我们只需要建立一次链接,所有的资源都是通过这个链接传送的;
3.8 cookie和session
上网的经验告诉我们:在访问一个网站时,我们只需要在最开始的时候进行账号和密码的登录,在之后的页面跳转时(本质就是进行各种 http 请求),我们不必输入账号和密码,网站依旧认识我们。
我们知道 http 协议本身是一种无状态的协议,只帮助解决网络资源获取的问题,并不记录这个资源是从哪里来等状态,这样造成了 http 协议的简单特性;
上述功能也并不是 http 协议本身要解决的问题,http 协议提供了一些技术支持,来保证网站具有 “会话保持” 功能;
cookie和session 在其中起的便是会话管理作用,本质是为了提高用户访问网站或者平台的体验!
cookie:
1. 浏览器:cookie 其实是浏览器中的一个文件,该文件保存的都是我们用户的一些私密信息;

2. http协议:一旦该网站对应有cookie,在向服务器发起任何请求的时候,都会自动在request中携带该cookie信息;
下面是一个http协议中,对cookie的一个基本理解图:
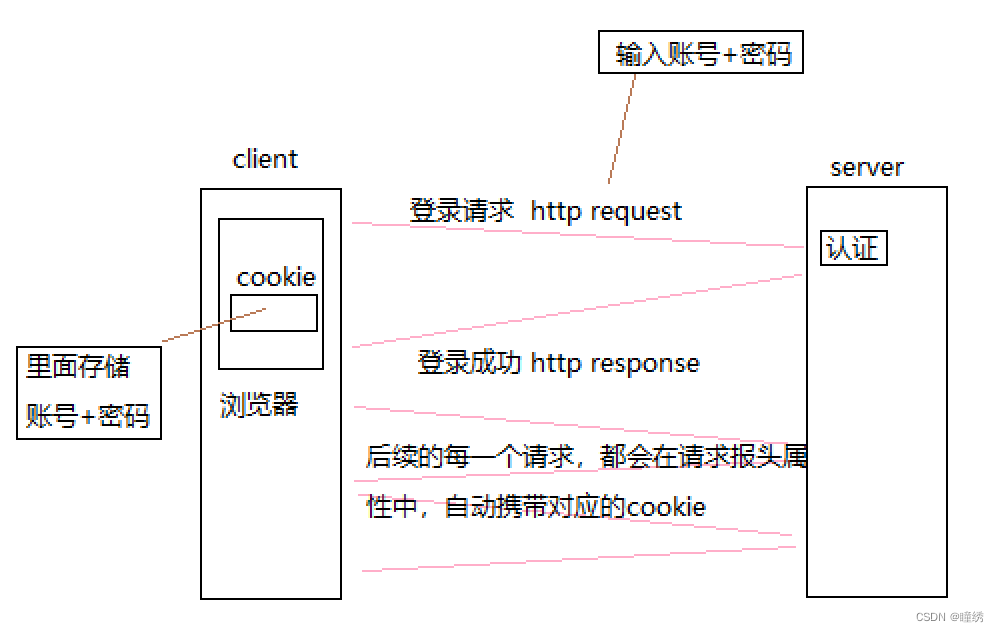
我们在登录一个网站时,首先输入自己的账号及密码,向server发送 http resquest,在server端进行一个认证后,给浏览器返回一个登陆成功的 http response,并在浏览器中形成了一个cookie文件(里面存储的是自己的账号及密码),在后续浏览器向server端发送的每一个请求,都会在自己的请求报头属性中自动携带对应的cookie信息;
我们可以也使用 Set-Cookie: Key=value 在 headler 属性中设置 Cookie 字段;
cookie的核心思路是:将用户的私密信息保存在客户端中,其实这种做法是很危险的;
cookie被盗:
1. 如果cookie文件中只保存我们浏览的一些痕迹的话,那么别人便可以以我的身份进行认证访问我们的之前的浏览痕迹;
2. 如果cookie文件中保存的是我们的用户名+密码的话,这种情况就非常的糟糕了(你的账号+密码失窃)!
因此单纯的使用cookie是具有一定的安全隐患的;
session:
session的核心思路是:将用户的私密信息保存在服务器端;

当用户在浏览器中输入自己的账号+密码后,浏览器向服务端发起 http request 登录请求,服务器对账号+密码进行一个认证,认证成功后形成一个session文件,里面保存的是用户的账号+密码信息,将这个session文件保存在磁盘中,并使用唯一的 session id 对其进行命名,完成后,服务器端构建 http 响应,发送一个http response响应(使用Set_Cookie设置cookie信息=session_id)给浏览器,浏览器这边便会形成一个cookie文件,里面保存的是session_id,在此后的http请求中,headler属性中都会有cookie字段,server依旧可以识别client,这也是一种会话保持的功能!
在服务器端保存用户的私密信息,是较为安全的,但也存在着cookie文件被盗的风险;
cookie文件被盗,虽然里面只有session_id,但是如果也去访问我们之前访问过的网址,server端也是可以识别client端的(有session_id便可以在磁盘中找到用户的私密信息);
由此http协议是不安全的,我们在此基础上实现了较为安全的https协议;
3.9 https:
https = http + TLS/SSL(http数据的加密解密层)
我们平常访问的网址都是使用https协议的;
3.10 加密方式:
加密方式分为两种:对称加密、非对称加密;
1. 对称加密:只有一个密钥(用该密钥加密,也用该密钥解密);
比如:密钥为X,发送端:将数据使用X进行加密后发送,接收端:收到数据后使用X进行解密得到发送端原本要发送的数据;
2. 非对称加密:有一对密钥(公钥和私钥);
可以用公钥进行加密,只能用私钥进行解密;
或者用私钥进行加密,只能用公钥进行解密;
一般而言,公钥是向全世界公开的,私钥是必须自己进行私有保存的;
3.11 如何防止文本中的内容被篡改,以及识别到是否被篡改:
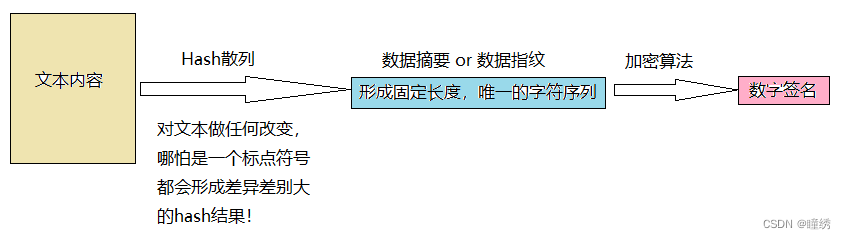
我们在发送数据时,首先将文本内容 通过Hash散列形成一个固定长度,唯一的字符序列,称为数据摘要,之后将数据摘要经过加密算法后得到数字签名;
我们之后发送的数据:文本内容+数字签名;
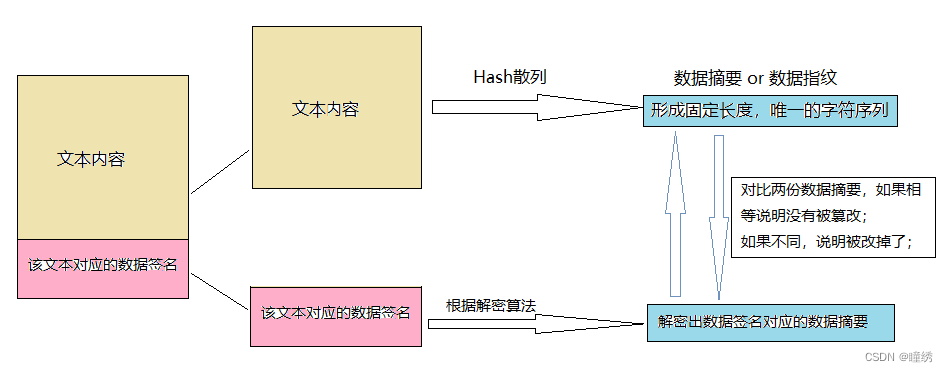
在接收端,我们将收到的数据(文本内容+数据签名)进行分开;
将文本内容重新进行Hash散列,形成数据摘要;
将数据签名根据解密算法进行解密,得到数据摘要;
然后对比两份数据摘要,如果相同则没被篡改,如果不同则被篡改了;
3.12 加密算法的选择:
1. 对称加密方法:
如果采用对称加密算法时,那便只有一个密钥;
这个密钥怎么被 client 和 server 知道呢?
采用预装吗?那么所有的客户端和服务器端都有这个密钥,都可以进行数据的加密和解密,相当于没有;
在通信前,采用密钥协商可以吗?client告诉server以后通信的密钥是X,如果是明文发送的话,很容易被旁听到密钥信息,是不可取的,那如果采用加密发送密钥,那么第一次的加密如何进行解密呢?进入死循环,这也是不可取的,因此采用对称加密方法是不行的;
2. 非对称加密方法:
先来看只有一对密钥的情况:
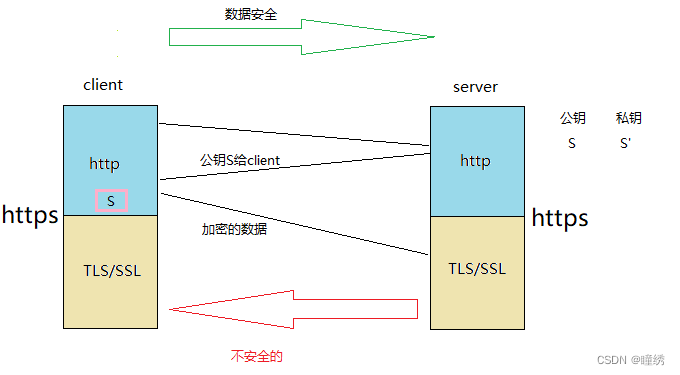
在server端:有公钥S和私钥S';
client和server通信前会有一个密钥协商阶段,在此阶段中,client向server发送一个消息,server端将自己的公钥S给了client端,client端以后发送数据时,都是将要发送的数据经过S加密后发送给server,只有server端有私钥S',因此只有server能对发来的数据进行解密,实现了client向server发送的数据的一个安全;
但是如果server向client发送数据时,server端使用自己的私钥S'对将要发送的数据进行加密,然后发送给client端,但是因为公钥S多个client都有,多个client都可以对发来的数据进行解密,因此server到client的数据发送是不安全的;
再来看有两对密钥的情况:
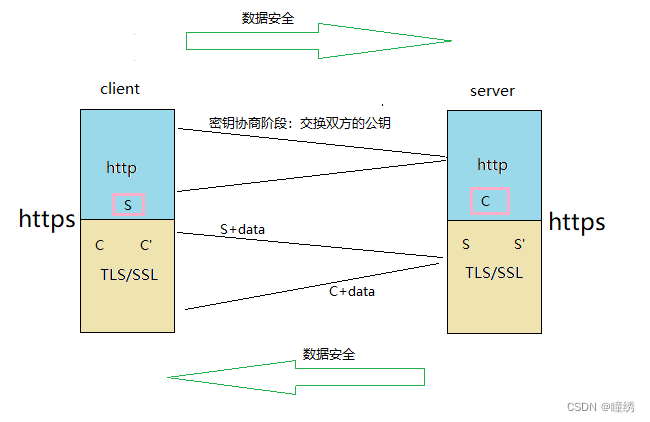
client 端和 server 端各自有一对公钥和私钥,在通信前,首先进行密钥协商,将双方的公钥进行交换, 在发送数据前,使用对方的公钥进行加密后发送,只有对方有私钥,因此双方的通信在现在看来都是安全的!其实依旧有被非法窃取的风险,下面再进行详谈;
非对称加密在现在看来虽然通信双方数据都是安全的,但是非对称加密算法特别费时间,对称加密是比较节省时间的!
实际方案:对称+非对称:
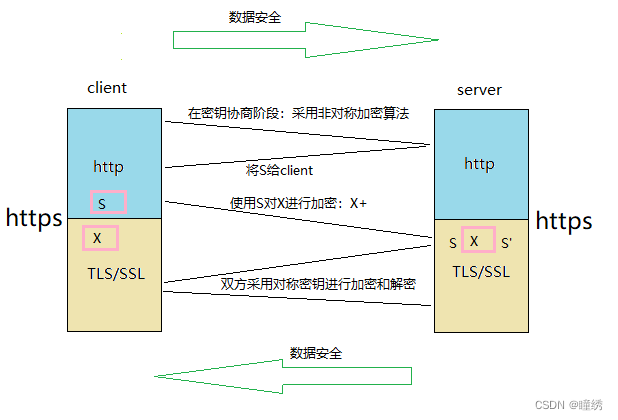
server端有一对公钥和私钥,client和server以后通信是使用对称密钥X;
在密钥协商阶段,采用非对称算法,client先向server发送一个信息,server将自己的公钥S给client,client端使用公钥S对以后双方进行通信的密钥X进行加密,然后将加密后的数据发送给server端,server端有唯一的私钥,对X+进行解密后,以安全的方式拿到了client发来的对称密钥X,此后client和server便可以使用对称密钥X进行双方数据安全通信!
3.13 中间人:
数据安全:所谓的数据安全并不是说,A向B发送数据,除了A和B外,没有C拿到数据,而是说就算C拿到了数据,也不知道如何破解加密算法从而拿到有效数据,又或者说解密对于该数据来说成本太大,没有人来对此解密,因此该数据便是安全的;
中间人:在网络环节中,随时都有可能存在中间人来偷窥、修改我们的数据;

server端有自己的公钥S和私钥S';中间人有自己的公钥M和私钥M';对称密钥为X;
client首先向server发送了一个消息,然后server便将自己的公钥S发送给client,可发送过程中,中间人接受了这个公钥S,并将这个公钥S掉包为自己的公钥M后,发送给client端;client使用公钥M对对称密钥X进行加密后,将该数据发送给server,中间人又截取了该数据,并使用自己的私钥M'对该数据进行解密,得到对称密钥X,中间人又将对称密钥X利用刚才截取的公钥S进行加密,并将加密后的数据发送给server,server对数据进行解密得到对称密钥X,此后client、中间人、server都有对称密钥X,中间人便可以窃听client和server的通信数据;
造成中间人窃取通信数据的本质是:client无法判定发来的密钥协商报文是不是从合法的服务方发来的!!!
3.14 CA证书:
CA证书机构:
1. 只要一个服务商,经过权威机构认证,该机构就是合法的,不止一个,是颁发CA证书的机构;
2. 具有权威性;
3. 有自己的公钥A和私钥A';
CA证书:形成过程如下图
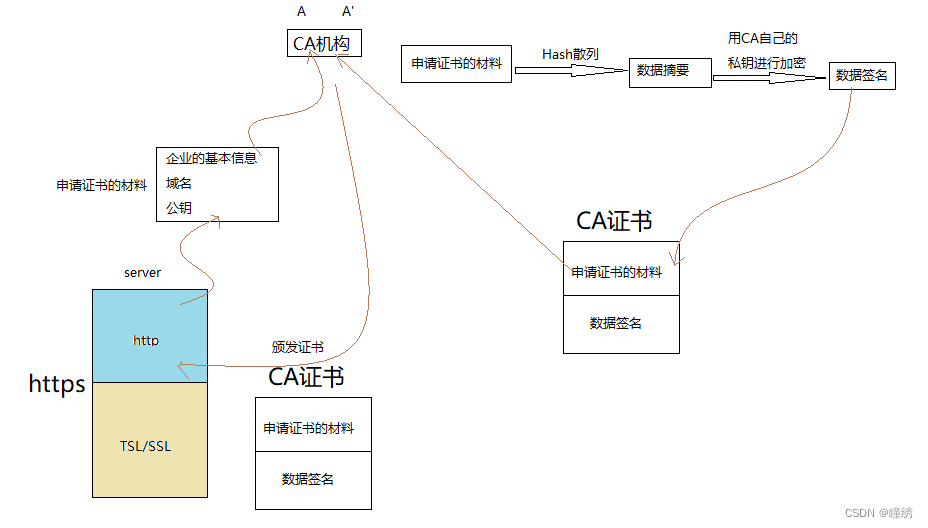
server首先向CA机构提交申请CA证书的材料(企业的基本信息、域名、公钥),CA机构将server提供的申请材料经过Hash散列,形成数据摘要,然后CA机构使用自己的私钥A'对数据摘要进行加密形成数据签名,然后将申请材料+数据签名组合在一起,形成CA证书后颁发给server;
在密钥协商阶段,client首先发起信息,server将CA证书传递给client;
就算有中间人窃听,中间人如果修改其中任意信息,client端对收到的证书进行检验,如果两份数据摘要比对不成功,client就会察觉到该信息被修改,不会生成对称密钥信息;
就算中间人是个合法的服务方,有自己的CA证书,client依旧可以查觉,因为CA证书中包含域名信息,该域名不是server的域名,也不会生成对称密钥信息;
使用CA证书来进行对称密钥的协商,是要求client必须知道CA机构的公钥信息的;
1. 这个公钥信息一般是内置的;
2. 访问网址的时候,浏览器也可能会提示用户进行安装公钥信息;
4. 最简单的HTTP服务器
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void Usage()
{
printf("usage: ./server [ip] [port]\n");
}
int main(int argc, char* argv[])
{
if (argc != 3)
{
Usage();
return 1;
}
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0)
{
perror("socket");
return 1;
}
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = inet_addr(argv[1]);
addr.sin_port = htons(atoi(argv[2]));
int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));
if (ret < 0)
{
perror("bind");
return 1;
}
ret = listen(fd, 10);
if (ret < 0)
{
perror("listen");
return 1;
}
for (;;)
{
struct sockaddr_in client_addr;
socklen_t len;
int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);
if (client_fd < 0)
{
perror("accept");
continue;
}
char input_buf[1024 * 10] = {0}; // 用一个足够大的缓冲区直接把数据读完.
ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);
if (read_size < 0)
{
return 1;
}
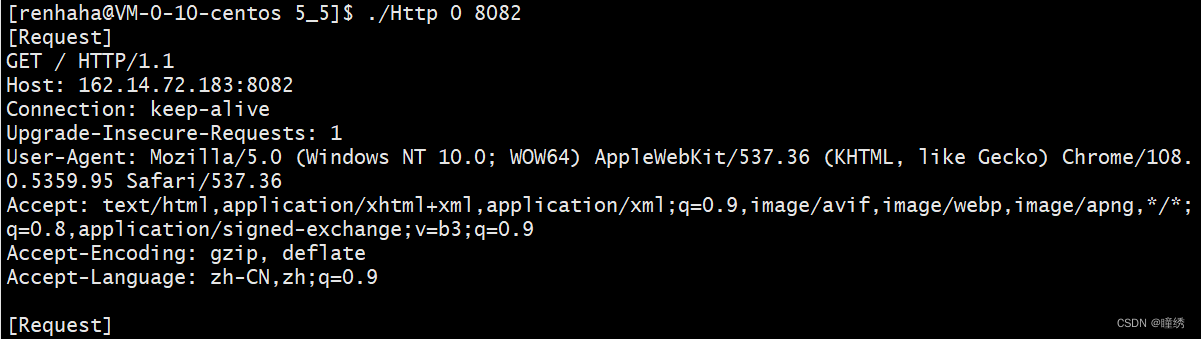
printf("[Request] %s", input_buf);
char buf[1024] = {0};
const char* hello = "<h1>hello world</h1>";
sprintf(buf, "HTTP/1.0 200 OK\nContent-Length:%lu\n\n%s", strlen(hello), hello);
write(client_fd, buf, strlen(buf));
}
return 0;
}
HTTP终于结束了🎈
如果本篇博客对您有所帮助的话,还请点赞、收藏并关注我✨
才疏学浅,如果有所疏漏的话,还请评论指出!