文章目录
- 摘要
- 文献阅读
- 1.题目
- 2.现存问题和解决方法
- 3.RUM
- 4.本文贡献
- 5.模型框架
- 5.1 Memory enhanced user embedding
- 5.2 Prediction function
- 5.3 Item-level RUM
- 5.4 feature-level RUM
- 6.实验
- 6.1 数据集
- 6.2 测量准则
- 6.3 基线
- 6.4 实验结果
- 7.结论与展望
- 灰色预测
- 有限元法
- 1. 第一类边界条件
- 2. 第二类边界条件
- 3. 第三类边界条件
- 总结
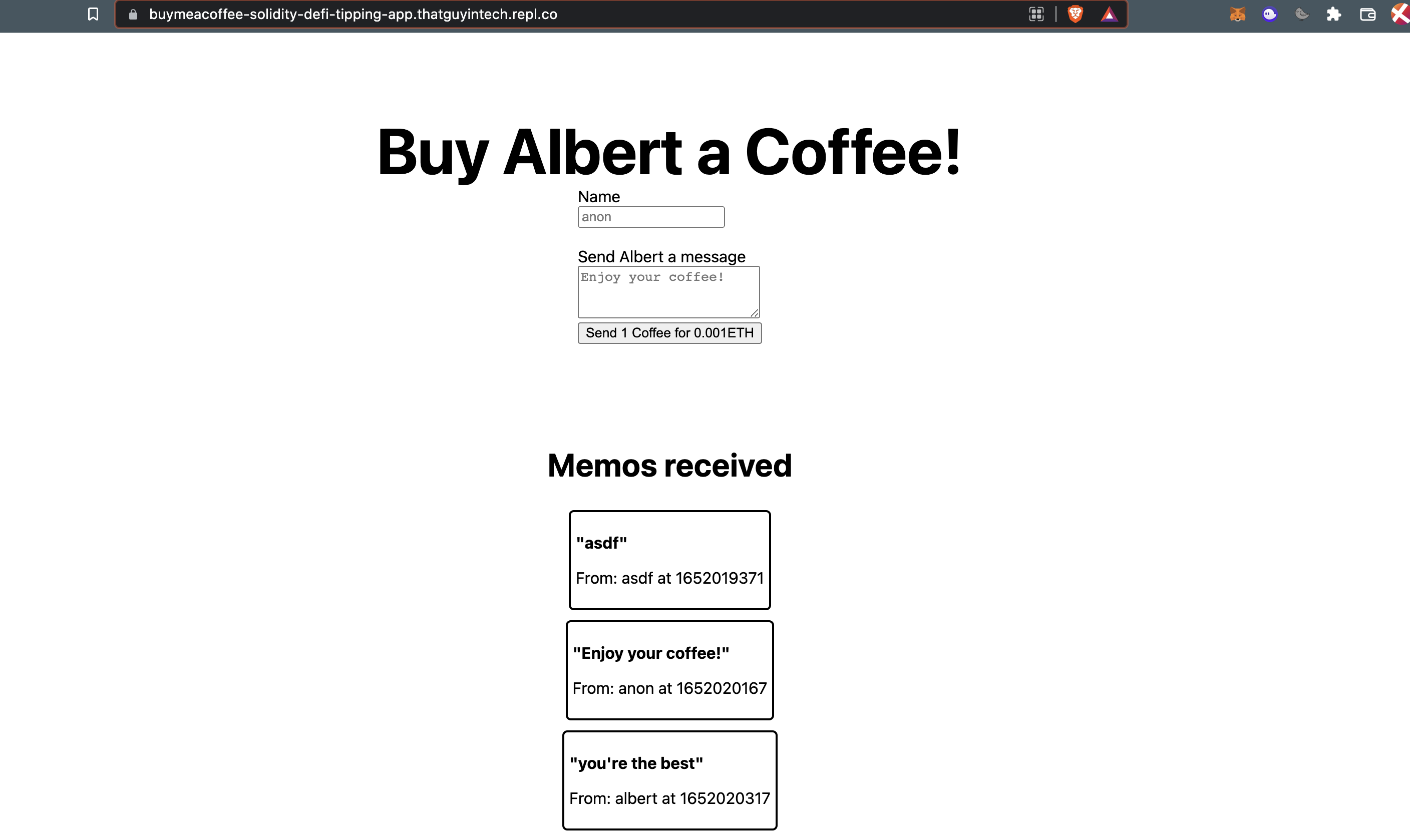
摘要
This week, I read a computer science about recommendation system. Because existing recommendation systems embed user history all into one potential vector, this may lose the correlation between user history and future interest. In this paper, a memory enhancement neural network integrated with collaborative filtering is proposed to recommend users. This network can effectively integrate users’ historical behavior records into the recommendation system. Finally, through experimental analysis on several actual data sets, the proposed method achieves remarkable performance and can extract the intuitive pattern of users’ influence on future behavior. In addition, I learn the following: 1) Grey prediction, because there is a potential law in the data set, grey prediction is to use this law to build a grey model to predict the grey system. 2) Three kinds of boundary conditions for heat transfer, which are actually related to temperature. The first kind gives the temperature at the boundary; The second type tells us what the temperature gradient is at the boundary; The third class gives a relation between temperature gradient and temperature at the boundary.
本周,我阅读了一篇与推荐系统相关的文章。由于现有的推荐系统将用户历史行为记录全部嵌入到一个潜在的向量中,这可能会失去了用户历史记录和未来兴趣之间的相关性。对此,文章提出了一种集成了协同过滤的记忆增强神经网络来对用户进行推荐,该网络可以有效地将用户的历史行为记录整合到推荐系统中。最后,通过在多个实际数据集上的实验分析表明,该方法取得了显著的性能表现,并且能够提取用户对未来行为影响的直觉模式。此外,我学习了以下内容:1)灰色预测,由于在数据集合中存在潜在的规律,而灰色预测就是利用这种规律建立灰色模型对灰色系统进行预测。2)传热三类边界条件,这三类边界条件其实都和温度有关。第一类给出了边界处的温度值;第二类给出了边界处的温度梯度是多少;第三类给出了边界处的温度梯度和温度满足一个关系式。
文献阅读
1.题目
文献链接:Sequential Recommendation with User Memory Networks
2.现存问题和解决方法
现存问题:
1)在实际生活中,并非所有的历史行为都对用户未来喜好有影响;
2)现有的方法(马尔可夫链和RNN)会将用户以前的历史序列用一个embedding进行表示,忽略了各个item之间的关系和各自的特征。
解决方法:为了以更明确、动态和有效的方式表达、存储和操作用户的历史记录,将memory network引入到推荐系统中,利用注意力机制和记忆单元获得用户动态Embedding,以用于推荐新的item,这会增加模型的表达能力。
3.RUM

基于传统的RNN推荐,会强制将所有先前的item(包含不相关的用户行为记录)用一个向量表示,用于预测用户的行为。不区分不同历史记录的后果:
1)削弱顺序推荐中高度相关项目的信号;
2)忽略这种信号会使得难以理解和解释顺序建议。
为了解决这些问题,引入外部用户记忆矩阵来维护其历史信息。在预测时,动态注意力读出记忆作为用户Embeding表示,其中注意力机制衡量历史行为对当前物品推荐的重要性。
4.本文贡献
1)建议将协同过滤与记忆增强神经网络集成到顺序推荐中,以更有效的方式利用用户历史记录;
2)研究了两种在项目和特征级别上具有不同表示和操作设计的潜在记忆网络,进一步研究并比较了它们在顺序推荐任务和top-N推荐任务中的性能;
3)将模型与最先进的方法进行比较,并通过对现实世界数据集的定量分析验证了模型的优越性,能够更有效地利用用户历史记录;
4)进一步提供实证分析解释模型是如何推荐一个项目的,这表明在记忆网络的注意力机制下,模型如何根据用户的历史记录去影响当前和未来的直观解释。
5.模型框架
5.1 Memory enhanced user embedding
用户个性化历史行为记忆矩阵 Mu,当前item Embedding:qi,用户记忆Embedding:pu^m, 综合Embedding:pu 。

其中:MERGE的策略为elemet multiply、concat等,但效果在实验数据上不如weight vector add,权重参数可用于平衡记忆比重。
5.2 Prediction function
交叉熵损失函数 + Sigmoid(其他激活函数也可行),其中Iu+为正样本item集合,user即action list item rank in action timestamp。

Memory更新:根据采取action的item更新记忆

5.3 Item-level RUM

1)Reading operation
记忆矩阵Mu(D X k),Item Embedding qviu(1 X D),用户u正样本集合:{v1u,v2u,···,vu|Iu+|},其中k为记忆槽数量:

2)Writing operation
记忆矩阵Mu只存储最近的k个item,记忆矩阵是一个先进先出的队列,只保存最近k个item Embedding:

M写入前:

M写入后:

5.4 feature-level RUM

1)特定用户memory feature为Mu,全局latent feature F分为k个;
2)M Reading operation:

3)M Writing operation:

6.实验
6.1 数据集
实验在亚马逊数据集上进行,其中包含1996年5月至2014年7月期间亚马逊的用户产品购买行为;从四个产品类别进行评估,包括即时视频、乐器、汽车和婴儿护理四部分;为了提供顺序推荐,作者选择了至少有10次购买记录的用户进行实验:

6.2 测量准则
1)Precision §, Recall ® and F1-score
为了更好地解释,作者采用了每个用户的平均值,而不是全局平均值:

2)Hit-ratio (HR)
Hit-ratio给出了可以收到至少一个正确推荐的用户百分比,这在以前的工作中已经被广泛使用:

3)NDCG
归一化的累积增益,通过采取正确的位置来评估排名性能考虑的项目:

6.3 基线
MostPopular、BPR、FPMC、DREAM
6.4 实验结果
1)模型与基线的性能比较:

2)项目级和特征级RUM模型在不同权重参数α选择下的性能:

3)item-to-item 转换的说明:

4)总结
记忆权重参数设置为0.2最佳,过大或过小都会导致效果变差;注意力解释历史行为影响模式:
模式一:用户行为被最近的上一次行为连续触发
模式二:一系列的行为被最近的某一次行为触发
7.结论与展望
结论:
1)提出利用集成了协同过滤的外部记忆网络进行顺序推荐;
2)设计了RUM顺序推荐框架,并提供了框架的项目级和功能级规范;
3)通过定量实验分析,验证了框架的有效性。
展望:
1)基于显式用户内存建模还有很大的改进空间,通过引入用户评论和产品图像等信息,可以将特征级RUM中的内存单元与不同的语义对齐,从而构建一个更可解释的推荐系统;
2)RUM模型是一个具有灵活泛化能力的框架,因此可以研究其他类型的内存网络设计,使得框架适应于不同的应用场景。
灰色预测
数学推导:
1)原来的数据是单调递增的,那么累加后的数据可以看作强烈单调递增。因此,强烈单调递增的数据可以近似为指数,可以用指数曲线来拟合,而指数曲线一定是某个一阶线性常系数微分方程。
2)通过解微分方程可以知道只有a, u是待确定的未知参数,因此只需求解出未知参数,即可求得累加序列与时间的表达式。

python代码实现:
import numpy as np
import matplotlib.pyplot as plt
import math
# 解决图标题中文乱码问题
import matplotlib as mpl
# 指定默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像是负号'-'显示为方块的问题
mpl.rcParams['axes.unicode_minus'] = False
# 原数据
data = np.array([[72.03, 241.2, 1592.74], [73.84, 241.2, 1855.36], [74.49, 244.8, 2129.60], [76.68, 250.9, 2486.86],
[78.00, 250.9, 2728.94], [79.68, 252.2, 3038.90]])
# 要预测数据的真实值
data_label = np.array([[81.21, 256.5, 3458.05], [82.84, 259.4, 3900.27], [84.5, 262.4, 4399.06], [86.19, 265.3, 4961.62],
[87.92, 268.3, 5596.1], [89.69, 271.4, 6311.79], [91.49, 274.5, 7118.96]])
# 累加数据
data1 = np.cumsum(data.T, 1)
# print(data1)
# 得到行数和列数 m=3, n=6
[m, n] = data1.shape
# 对这三列分别进行预测
# 已知年份数据
X = [i for i in range(1997, 2003)]
X = np.array(X)
# 预测年份数据
X_p = [i for i in range(2003, 2010)]
X_p = np.array(X_p)
# 最开始参考数据
X_sta = X[0] - 1
# 求解未知数
for j in range(3):
B = np.zeros((n - 1, 2))
for i in range(n - 1):
B[i, 0] = -1 / 2 * (data1[j, i] + data1[j, i + 1])
B[i, 1] = 1
Y = data.T[j, 1:7]
print("--------系数矩阵B--------")
print(B)
print("--------系数矩阵Y--------")
print(Y)
print("--------求得未知参数a,u--------")
a_u = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Y.T)
print(a_u)
# 进行数据预测
a = a_u[0]
u = a_u[1]
T = [i for i in range(1997, 2010)]
T = np.array(T)
# 累加数据
data_p = (data1[0, j] - u / a) * np.exp(-a * (T - X_sta - 1)) + u / a
print("--------预测数据--------")
print(data_p)
data_p1 = data_p
data_p1[1:len(data_p)] = data_p1[1:len(data_p)] - data_p1[0:len(data_p) - 1]
# print(data_p1)
title_str = ['第一产业GDP预测', '居民消费价格指数预测', '第三产业GDP预测']
plt.subplot(221 + j)
data_n = data_p1
plt.scatter(range(1997, 2003), data[:, j])
plt.plot(range(1997, 2003), data_n[X - X_sta])
plt.scatter(range(2003, 2010), data_label[:, j])
plt.plot(range(2003, 2010), data_n[X_p - X_sta - 1])
# plt.title(title_str[j])
plt.legend(['实际原数据', '拟合数据', '预测参考数据', '预测数据'])
y_n = data_n[X_p - X_sta - 1].T
y = data_label[:, j]
wucha = sum(abs(y_n - y) / y) / len(y)
titlestr1 = [title_str[j], '预测相对误差:', wucha]
plt.title(titlestr1)
plt.show()
打印输出:
--------系数矩阵B--------
[[-108.95 1. ]
[-183.115 1. ]
[-258.7 1. ]
[-336.04 1. ]
[-414.88 1. ]]
--------系数矩阵Y--------
[73.84 74.49 76.68 78. 79.68]
--------求得未知参数a,u--------
[-1.98742486e-02 7.13639977e+01]
--------预测数据--------
[ 72.03 145.5537343 220.55331466 297.05836583 375.0991072
454.70636477 535.91158331 618.74683878 703.244851 789.43899658
877.36332211 967.05255757 1058.54213012]
--------系数矩阵B--------
[[-3.61800e+02 1.00000e+00]
[-6.04800e+02 1.00000e+00]
[-8.52650e+02 1.00000e+00]
[-1.10355e+03 1.00000e+00]
[-1.35510e+03 1.00000e+00]]
--------系数矩阵Y--------
[241.2 244.8 250.9 250.9 252.2]
--------求得未知参数a,u--------
[-1.12813547e-02 2.38347899e+02]
--------预测数据--------
[ 145.87 387.22234074 631.31287909 878.17268052 1127.83316295
1380.32610076 1635.6836288 1893.9382465 2155.12282201 2419.27059637
2686.41518775 2956.59059572 3229.8312056 ]
--------系数矩阵B--------
[[-2.520420e+03 1.000000e+00]
[-4.512900e+03 1.000000e+00]
[-6.821130e+03 1.000000e+00]
[-9.429030e+03 1.000000e+00]
[-1.231295e+04 1.000000e+00]]
--------系数矩阵Y--------
[1855.36 2129.6 2486.86 2728.94 3038.9 ]
--------求得未知参数a,u--------
[-1.20343072e-01 1.59117525e+03]
--------预测数据--------
[ 220.36 1939.41824265 3878.31606721 6065.16737963
8531.68139707 11313.62242966 14451.32846098 17990.29604642
21981.84001063 26483.83750952 31561.56724559 37288.65600541
43748.14624371]
预测数据与真实数据对比图:

有限元法
1. 第一类边界条件
边界是研究对象与外部环境的交界,边界条件是我们对物理状况的了解程度。边界条件也叫做定解条件,即控制方程/偏微分方程的解。只有给定初始值,我们才能求出微分方程解中的未知数。

如上图所示,传热边界条件有三类:
最简单的边界条件就是直接给出边界处的温度,即在S1处:

其中:这个边界条件就是第一类边界条件、狄利克雷边界条件,可以直接用温度计测得。
2. 第二类边界条件

如图所示,给出了三类边界条件及其公式描述。假设橙色是一个冰块的局部,竖直黑线是冰块的边界,左边假设是空气,那么这里就简化为水平一个维度温度的变化情况。
1)第一类边界条件如左上图所示,给定边界处的温度值;
2)第二类边界条件给定的是热流密度,而且一般都指边界法向热流密度qn,即在S2:

其中:qn指的是温度的梯度,对应左下角图,按几何理解就是温度曲线在边界处的斜率。二阶偏微分方程的定解条件也需要某点一阶导的值,因此第二类边界条件告诉你温度的梯度。
特别地,当这个热流密度为0时,即梯度为0时,如右上图所示,这个条件就是绝热边界条件。当温度梯度为0时,那么就不存在热量从温度高的流向低的,那么就没有了热量交换,所以叫绝热/隔热,也叫自然边界条件。
3. 第三类边界条件
第三类边界条件如右下图所示,在S3处:

其中:T0指边界处的温度,这个是未知的;Ta指环境温度,这个是已知的,h指表面热传导系数,这个是已知的。
这个边界条件也叫对流边界条件,公式左边是热流密度,那公式右边是什么呢?在右下角图中,边界外面实际上有流体沿着边界表面流过,这就是受迫对流,因此公式右边表述的是对流传热,对流传热的微分方程:

因此,边界处温度的梯度,即热流密度,我们可以通过对流传热来求解,这个关系式包含了在边界处的温度及其温度梯度。表面热传导系数h和对象表面、流体性质、对流性质有关,一般可以通过做实验得出。
总结
本周,我学习了灰色预测法,其基本思想是通过鉴别系统因素之间发展趋势的相异程度,对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。此外,我学习了传热三类边界条件。如果知道温度,就直接用第一类边界条件;如果什么都不知道,一般用第二类绝热边界条件;如果涉及对流传热,一般要用第三类边界条件。现在既学习控制方程,又学习了边界条件,因此下周将学习有限元求解方程。



![[LeetCode周赛复盘] 第 345 场周赛20230514](https://img-blog.csdnimg.cn/4a3b8a53b587493691358db0e6a12e71.png)