Springboot+Vue架构设计(二)
项目中的文件来自B站视频(程序员青戈) https://www.bilibili.com/video/BV1U44y1W77D
数据库设计
1、article

在关系型数据库中,text类型和varchar类型都是用来存储字符串的数据类型。它们之间的主要区别在于存储大小的限制和性能表现。
text类型:
- 存储大小:
text类型是一种可变长度的字符串类型,可以存储非常大的文本内容,其存储大小取决于文本内容的长度。 - 性能表现:由于
text类型是可变长度的,因此在进行查询时需要进行动态内存分配,会相对于varchar类型的查询更加耗时,但是对于存储非常大的文本内容时,text类型的性能会更好。
varchar类型:
- 存储大小:
varchar类型也是一种可变长度的字符串类型,但是它有一个存储大小的限制,需要在创建表时指定最大存储长度。如果字符串的实际长度超过了最大存储长度,会导致截断或错误。 - 性能表现:由于
varchar类型有一个固定的存储大小,因此在进行查询时不需要进行动态内存分配,会相对于text类型的查询更加快速。
因此,在选择使用text类型还是varchar类型时,需要根据具体的应用场景和需要存储的字符串内容来做出决策。如果需要存储非常大的文本内容,可以选择使用text类型;如果字符串的长度不会太长,可以选择使用varchar类型。
2、building
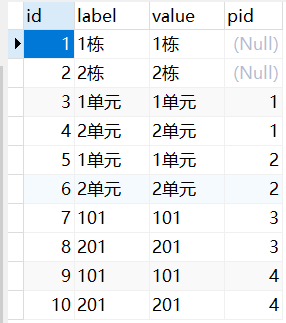
这就涉及到了无限极分类设计了
无限极分类是一种常见的数据分类结构,常用于对具有层级关系的数据进行管理和展示,例如商品分类、组织架构、地区划分等。其设计思路是将每个分类项存储为一条记录,并在记录中添加一个字段来表示其父级分类的ID。这样,可以通过在记录中查找其父级分类ID来构建分类的层级结构。
在无限极分类的设计中,最常见的是使用递归查询来构建分类层级。递归查询的实现通常使用数据库中的存储过程或者使用编程语言中的递归函数。具体来说,在递归查询过程中,先查询出顶级分类(即父级分类ID为空的分类),然后针对每一个顶级分类进行递归查询,找到其下属的子分类,并将这些子分类加入到当前分类的下级分类列表中。这个过程将会一直递归下去,直到查询到最后一级分类为止。递归查询可以有效地构建出任意层数的分类结构,使得分类的管理和展示变得更加方便和灵活。
3、course

在MySQL中,设置int类型字段的长度为0,表示该字段的最大长度为11位,即默认的int(11)。在实际应用中,这个长度通常已经足够使用。
而对于varchar类型字段,必须指定其最大长度,以便数据库知道该字段能够容纳多少个字符。如果不指定长度,则会默认为1,这往往是不够用的。
除了varchar类型之外,还有其他一些数据类型可以不指定长度,如text、blob等,这些类型会根据实际存储的数据自动进行调整。
- tinyint
tinyint是MySQL中的一种数据类型,用于存储整数值,占用1字节的存储空间。一般情况下,tinyint用于存储布尔值(true/false),或者一些取值范围较小的整数值。
在数据库设计中,我们通常会使用tinyint来设计一些状态字段,如用户状态(启用/停用)、订单状态(已支付/待支付/已发货/已完成等)、审核状态(通过/不通过/待审核)等等。这些状态字段只有有限的几种取值,因此使用tinyint来存储比较合适。
4、student_course

在表中设置主键的作用是保证数据的唯一性和查询效率,以及方便进行关联查询,设置使用student_id和course_id作为联合主键可以确保每个学生只能选修同一门课程一次。
当使用联合主键时,数据库会在student_id和course_id这两个字段上创建一个组合索引(Composite Index)。这意味着,当查询student_course表时,数据库会使用这个组合索引来快速地找到需要的记录,而不需要额外地创建一个独立的索引来优化查询。因此,使用联合主键可以避免使用复合索引的情况,从而提高查询效率。
举个例子:
假设有一个存储订单信息的表orders,包含以下字段:order_id、customer_id、order_date、total_price。
如果只将order_id作为主键,那么查询某个顾客的所有订单需要使用索引来查找,例如:
SELECT order_id, order_date, total_price
FROM orders
WHERE customer_id = 12345;
由于customer_id没有建立索引,查询效率可能较低。为了提高查询效率,可以将customer_id也作为主键之一,例如:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
total_price DECIMAL(10,2),
PRIMARY KEY (order_id, customer_id)
);
这样,查询某个顾客的所有订单就可以直接通过主键查询,而不需要使用索引,例如:
SELECT order_id, order_date, total_price
FROM orders
WHERE customer_id = 12345;
这样可以减少索引的使用,从而提高查询效率。
5、sys_dict
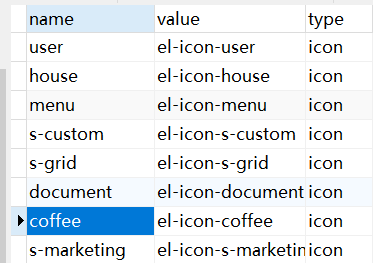
设计icon图标
ElementUI图标地址: https://element.eleme.cn/#/zh-CN/component/icon
6、sys_menu
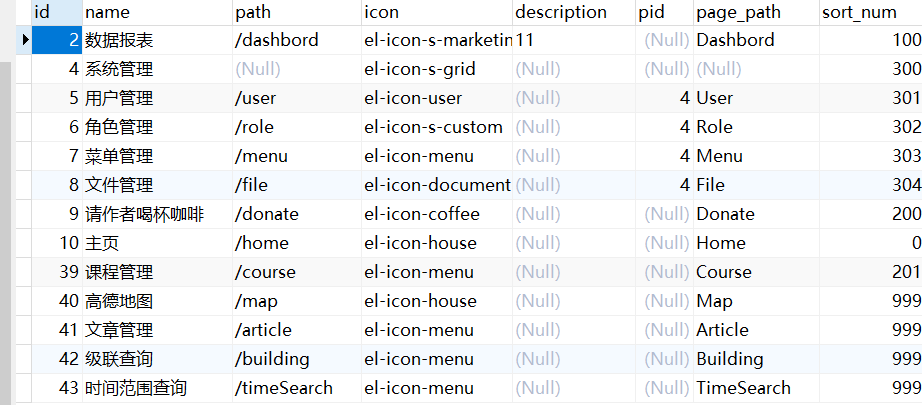
- path和page_path字段
在这个表中,path和page_path字段都是用来表示菜单的访问路径。path表示菜单的实际路径,而page_path则表示菜单对应的页面路径。具体如下
假设我们有一个菜单项名为“用户管理”,对应的页面为“User”,路径为“/user”。在前端代码中,我们可以使用路由器来监听路径变化,并根据路径加载对应的组件。
在Vue.js中,我们可以使用Vue Router来实现路由功能。假设我们的路由配置如下:
javascript
import Vue from 'vue'
import Router from 'vue-router'
import User from '@/components/User'
Vue.use(Router)
export default new Router({
routes: [
{
path: '/',
name: 'Home',
component: Home
},
{
path: '/user',
name: 'User',
component: User
}
]
})
在这个路由配置中,我们定义了两个路径,分别是“/”和“/user”。当用户访问这两个路径时,会加载对应的组件。
在这里,path字段就对应着路由的路径,即“/user”,而page_path则对应着组件的名称,即“User”。当用户点击“用户管理”菜单时,前端应用就会自动跳转到“/user”路径,并加载User组件。
- sort_num
在这个表中,sort_num是用来表示菜单的排序顺序的。这个字段的值越小,表示该菜单在菜单列表中的位置越靠前。
例如,在上面的sys_menu表中,Home菜单的sort_num字段为0,因此它会出现在菜单列表的最前面;而系统管理菜单的sort_num字段为300,因此它会出现在菜单列表的第三个位置。
7、sys_role

- flag
设计唯一标识(flag)可以帮助程序在代码中进行权限控制时,不需要硬编码角色名称或ID,而是使用唯一标识来表示该角色,这样可以提高代码的灵活性和可维护性。例如,在代码中使用 ROLE_ADMIN 来表示管理员角色,而不是使用 1 或 管理员 这样的硬编码方式。这样,如果角色名称或ID发生变化,只需要修改数据库中的标识字段,而不需要修改代码中的硬编码。
假设一个学生信息管理系统需要记录学生的性别,设计一个简单的数据库表,包括以下字段:
- id:学生ID,自增长整数类型
- name:学生姓名,字符串类型
- gender:学生性别,整数类型,0表示男性,1表示女性
现在,开发人员在代码中进行了权限控制,只有管理员可以修改学生的性别,代码如下:
public void updateStudentGender(int studentId, int gender, int roleId) {
if (roleId == 1) { // roleId=1表示管理员
// 进行更新性别的操作
} else {
throw new RuntimeException("没有权限进行此操作");
}
}
在代码中,硬编码的方式是使用数字1表示管理员角色,这样会导致以下问题:
- 如果管理员角色的ID变更为2,需要修改所有使用1表示管理员角色的代码
- 如果管理员角色的名称变更为其他名称,例如“超级管理员”,需要修改所有使用1表示管理员角色的代码
- 如果后续新增其他角色,需要修改代码并增加对应的硬编码值
这样的设计不仅维护成本高,而且容易出错,因此使用唯一标识来代替硬编码是更好的设计方式。
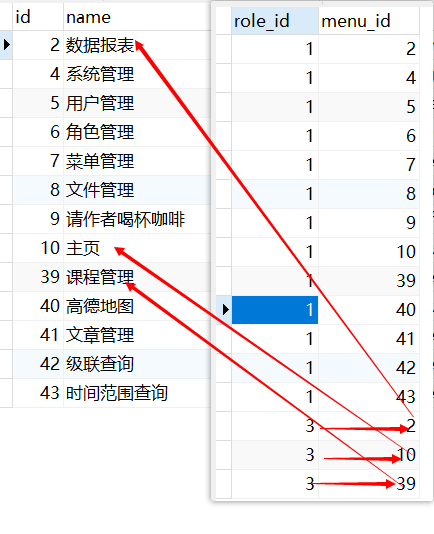
8、sys_role_menu

这是一个角色菜单关系表,用于记录角色和菜单之间的对应关系。其中,role_id 表示角色的ID,menu_id 表示菜单的ID,这两个字段组成了联合主键。
9、sys_user
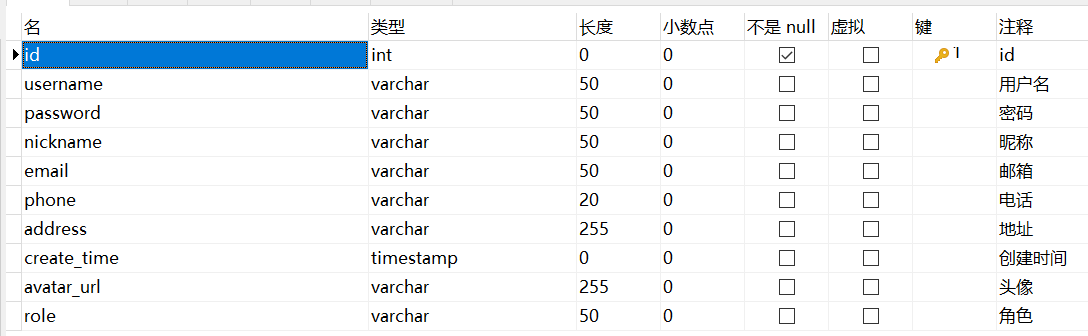
- timestamp
在关系型数据库中,date、datetime、timestamp 都是用来存储时间的数据类型,它们的主要区别在于精度和范围不同。
date 类型用于存储日期,包括年、月、日,不包含时间。其精度为天级别,范围从 ‘1000-01-01’ 到 ‘9999-12-31’。
datetime 类型用于存储日期和时间,包括年、月、日、时、分、秒。其精度为秒级别,范围从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’。
timestamp 类型也用于存储日期和时间,包括年、月、日、时、分、秒。其精度为秒级别,范围也是从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-19 03:14:07’ UTC。不同的是,timestamp 类型在插入数据时,会自动记录插入的时间戳,以及最后更新的时间戳。而 datetime 类型则需要手动插入时间。
总的来说,如果只需要存储日期,可以使用 date 类型;如果需要存储日期和时间,可以使用 datetime 或 timestamp 类型。如果需要记录数据的创建时间和最后更新时间,建议使用 timestamp 类型。
一般来说往往还需要记录修改时间
可以为每个表添加两个字段用于记录创建和更新的时间戳,常见的命名方式是created_at和updated_at。其中,created_at表示该记录创建的时间,一般在插入新纪录时自动生成,而updated_at表示该记录最后一次更新的时间,一般在更新记录时自动更新。
这两个字段可以使用datetime或者timestamp类型存储。如果使用datetime类型,可以在插入和更新时使用NOW()函数获取当前时间戳。而如果使用timestamp类型,可以使用CURRENT_TIMESTAMP或者ON UPDATE CURRENT_TIMESTAMP来自动设置时间戳。
下面是一个示例表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`email` varchar(50) NOT NULL,
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
在该示例中,created_at使用datetime类型,而updated_at使用timestamp类型,并在默认值中设置了ON UPDATE CURRENT_TIMESTAMP。这样,在插入新纪录时,created_at会自动获取当前时间戳,而updated_at会在记录更新时自动更新为当前时间戳。
10、t_comment
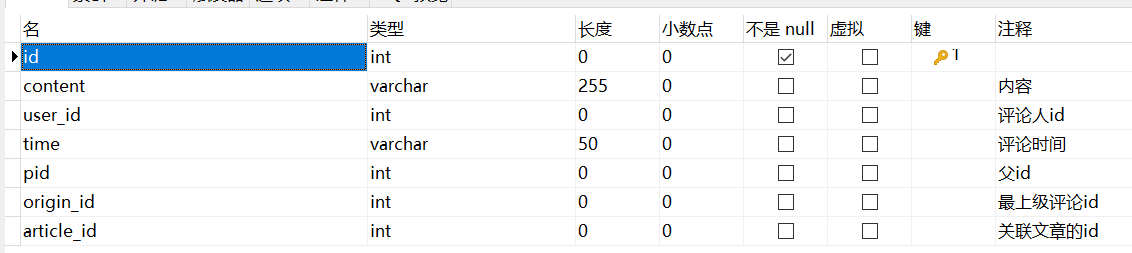
- pid
子评论的 pid 则指向其父评论的 id
- origin_id
最上级的id指的就是一个话题或者讨论的最开始的评论id。这个id通常会被记录下来,作为整个话题或讨论的唯一标识。之后的所有评论,包括回复和引用,都可以通过这个最上级的id来建立它们之间的关系。这个设计可以方便地对话题或讨论进行管理和展示,并且能够使每个评论的关系更加清晰明了。
- article_id
评论文章的id