🌟hello,各位读者大大们你们好呀🌟
🍭🍭系列专栏:【Linux初阶】
✒️✒️本篇内容:计算机空间初识(子进程变量修改实验),感性理解进程虚拟地址空间,进程地址空间基础(概念、区域划分与调整、程序对内存数据的修改、按需分配虚拟地址空间),解答为什么存在虚拟地址空间(防止非法越界、方便解耦、保证进程独立性、统一编译方便使用),其中重点讲解统一编译中CPU与可执行程序的交互原理
🚢🚢作者简介:本科在读,计算机海洋的新进船长一枚,请多多指教( •̀֊•́ ) ̖́-
目录
一、你真的了解计算机数据空间分布吗?
二、感性理解进程虚拟地址空间
三、进程地址空间基础
1.相关的基础概念
2.区域划分与调整
3.程序是如何更改内存中的数据的?
4.操作系统会根据进程的需求分配虚拟地址空间
四、为什么存在地址空间
1.防止非法越界访问
2.方便进程解耦,保证进程独立性
3.统一编译,方便使用
(1)可执行文件中有地址吗?
(2)编译器的编码方式
(3)物理地址的来源
(4)CPU与可执行程序交互的原理
(5)逻辑地址知识补充
结语
一、你真的了解计算机数据空间分布吗?
在以前的学习中,大家可能很早已经见过类似下面这样的空间分布图了
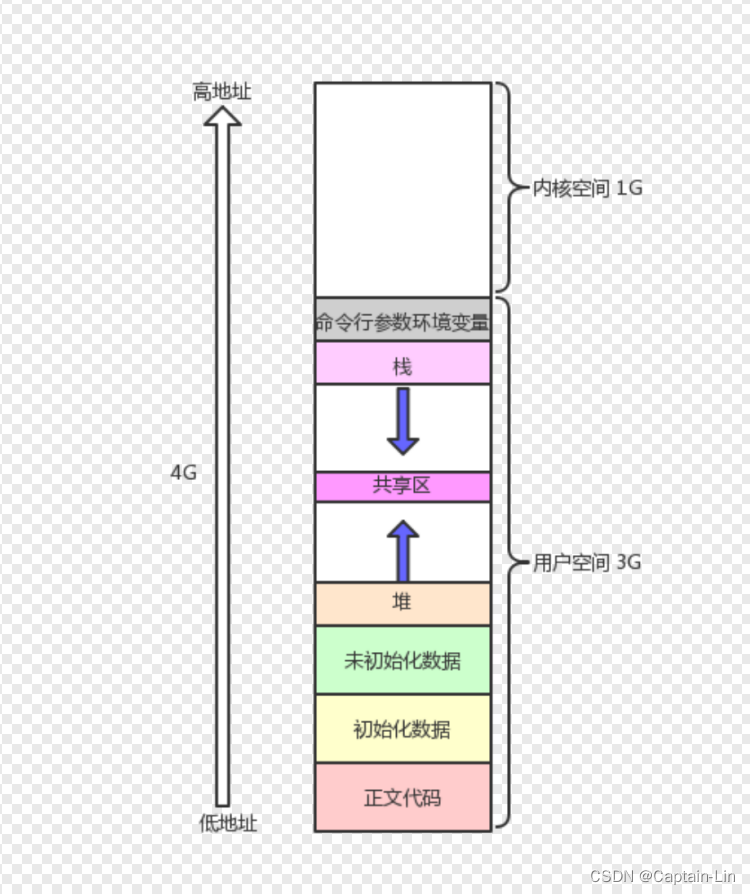
可是我们很多同学对它并没有深入理解,很多同学认为这个空间实际上就是我们的内存,但是真的是这样吗?
我们直接通过一段代码来验证一下
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { //child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { //parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}输出
//与环境相关,观察现象即可
parent[2995]: 0 : 0x80497d8
child[2996] : 0 : 0x80497d8我们发现,输出出来的变量值和地址是一模一样的,很好理解呀,因为子进程按照父进程为模版,父子并没有对变量进行进行任何修改。可是将代码稍加改动:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { //child,子进程肯定先跑完,也就是子进程先修改,完成之后,父进程再读取
g_val = 100;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { //parent
sleep(3);
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}输出结果:
//与环境相关,观察现象即可
child[3046]: 100 : 0x80497e8
parent[3045] : 0 : 0x80497e8我们发现,父子进程,输出地址是一致的,但是变量内容不一样!能得出如下结论:
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量。
- 但地址值是一样的,说明,该地址绝对不是物理地址!
- 曾经我们学习语言的基本地址(指针),并不是对应的物理地址。
- 在Linux地址下,这种地址叫做 虚拟地址。
- 我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理。
注意:OS必须负责将 虚拟地址 转化成 物理地址 。
二、感性理解进程虚拟地址空间
进程会认为自己是独占系统资源的(实际上不是)
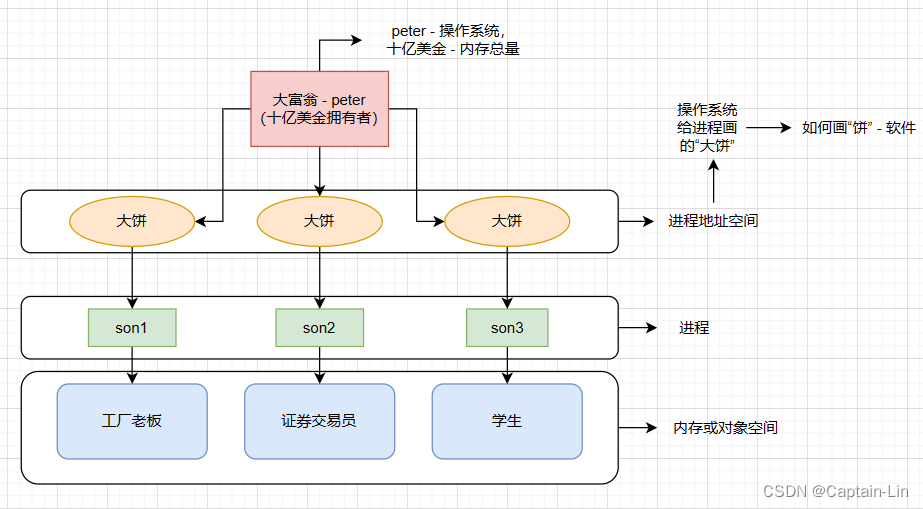
这里我举一个通俗易懂的例子:
peter是美国一个拥有十亿美元的大富翁,他拥有三个私生子,且这三个私生子互不知道其他私生子的存在,三个儿子分别是工厂老板、证券交易员、学生。每个儿子都认为自己是peter十亿美金的继承者。
在他们工作的过程中,需要向peter索取金钱(工厂老板为维持家族企业正常运转,发放工人工资,结清货款;证券交易员维持正常投资,管理部分家族现金资产;学生为缴纳学费等),他们向peter索要的金钱有多有少,但是都不会提出过分的要求(比如直接索要十亿美金),如果他们提出过分要求,会被peter拒绝。
peter在三个儿子工作的时候,会给儿子们“画饼”,比如他会对第一个儿子说:你好好干,只要你管理好我们的家族企业,提高我们的工厂效益,以后我的十亿美金就都是你的了。
其中大富翁peter就相当于我们的操作系统,十亿美金就相当于操作系统管理的内存资源。其中儿子就相当于我们平时 malloc、new等向系统索要资源的进程。儿子们获取的金钱就相当于内存或者在语言上称为对象空间(内存)。peter给三个儿子画的“大饼”就相当于进程地址空间。计算机通过软件,给进程“画饼”。
———— 我是一条知识分割线 ————
那实际上如何“画饼”呢?在此之前,我们要知道“饼”是什么,画饼的本质:在你大脑中的蓝图 - 数据结构对象(地址空间)。
每个儿子(进程)都可以根据peter(操作系统)为自己画的“饼”(数据结构对象/地址空间)向peter要钱(内存资源)

———— 我是一条知识分割线 ————
我们已经知道“饼”是什么,那么问题又来了,我们都知道儿子(进程)需要被管理,那么peter(操作系统)为儿子(进程)提供的“饼”(数据结构对象/地址空间)需要被管理吗?答案是:要的!因为不能将给大儿子的承诺许错给二儿子或三儿子,所以“饼”也要被管理。
如果进程中有500个进程,操作系统需要给每个进程创建地址空间,进程会被PCB管理,地址空间需要怎么管理呢?答案是:先描述,在组织。地址空间的本质:是内核的一种数据结构(mm_struct)。简单来说,我们的虚拟地址空间会被一个名为 struct mm_struct的数据结构管理起来。
三、进程地址空间基础
1.相关的基础概念
注意:本次讲解以32位计算机平台为基础
在正式深入学习进程地址空间之前,我们需要先了解一些相关的基础概念:
- 进程/内存空间描述的基本空间大小为字节;
- 32位下计算机最多可以形成 2^32个地址;
- 每个地址标识一个字节,所以我们能表示的地址空间范围最大为 4G;
- 每个进程都要有唯一的地址,假设我们需要表示 2^32个地址,我们需要保持每个地址的唯一性;
- 我们可以通过 32位的数据(32个比特位的数据)来表示一个地址。
进程地址空间图例如下
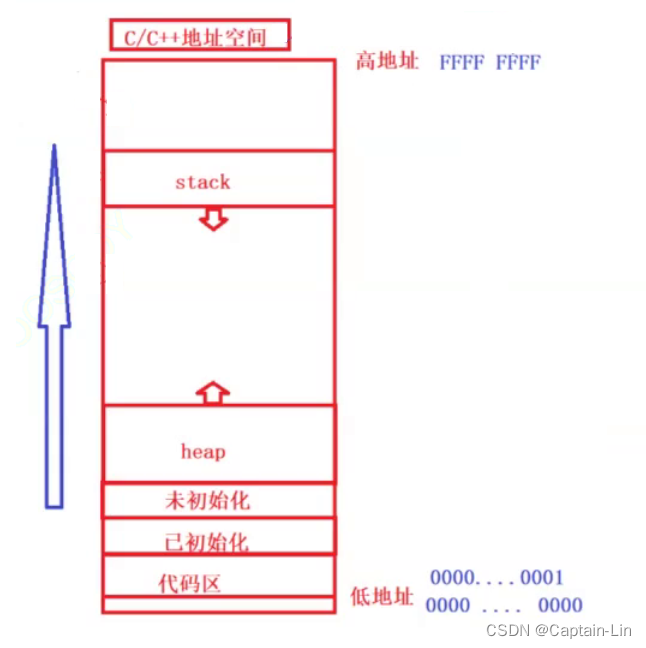
2.区域划分与调整
这里我们举一个例子来理解区域划分和区域调整。
假设初中有一对男女同桌,由于男生太贪玩,经常打扰到旁边的女生学习,所以女生给桌子画了一条线,将桌子分成了两个区域,假设桌子有100cm,她将区域划分为[1-50, 51-100],这就是区域划分。
而后小男孩还是不在意,经常越线,因此小女孩调整了桌子上线的位置,桌子有100厘米,但是女孩只给了小男孩30厘米的活动范围,[1-30, 31-100],这种在划分后调整各自区域的行为称为区域调整。
通过观察下图我们可以发现,只要我们调整不同对象的 start、end,就可以实现区域调整(扩大 or 缩小)。

我们可以通过搜索不同的地址位置,找到数据所在。还是上面的例子来解释,可能1-10cm中放有小男孩的笔袋,12-16cm放有小男孩的笔记本。
———— 我是一条知识分割线 ————
之前文章中提到,我们可以通过 32位的数据(32个比特位的数据)来表示地址,我们的虚拟地址空间会被一个名为 struct mm_struct的数据结构管理起来。在32位计算机下,通常我们采用 int类型的数据来记录一个地址,因为 int在刚好在32位计算机下占32个比特位。在 struct mm_struct的数据结构中包含着不同区域地址信息,其中就包含有堆的区域起始地址、区域结束地址等。
这些在不同的区域范围内、可以供我们使用的地址称为虚拟地址。也就是说在地址空间中的 2^32个地址都是虚拟地址。
所以,进程地址空间也叫做进程虚拟地址空间,它的本质实际上是一个存储虚拟地址及其相关数据的集合。

———— 我是一条知识分割线 ————
在地址空间中,代码区(已初始化、未初始化)的大小是固定的,也就是说代码区的起始和结束地址不可被调整;但是堆区和栈区不同,堆区可以通过 malloc等手段调整它的大小,栈区也可以定义相应的局部变量,也就是说,堆区和栈区是可以被调整的!
heap & stack的调整,本质上就是调整两个区域的 start和end。在我们的编程过程中,定义局部变量,malloc、new对象实际上就是扩大堆区或者栈区。当我们 free的时候,实际上就是在缩小堆区或者栈区。
3.程序是如何更改内存中的数据的?
在第一节中我们验证过,父子进程,输出地址是一致的,但是变量内容不一样,这到底是怎么做到的呢?在解答这个问题之前,我们先要知道,程序是如何更改内存中的数据的。接下来这一部分的知识主要就是向大家讲解,程序是如何更改内存中的数据的。
文章第二节讲到,操作系统会为进程画“大饼”,这里的大饼就是地址空间(mm_struct),因此相应的,tack_struct(PCB,进程控制块)会有相应的指针指向进程地址空间。
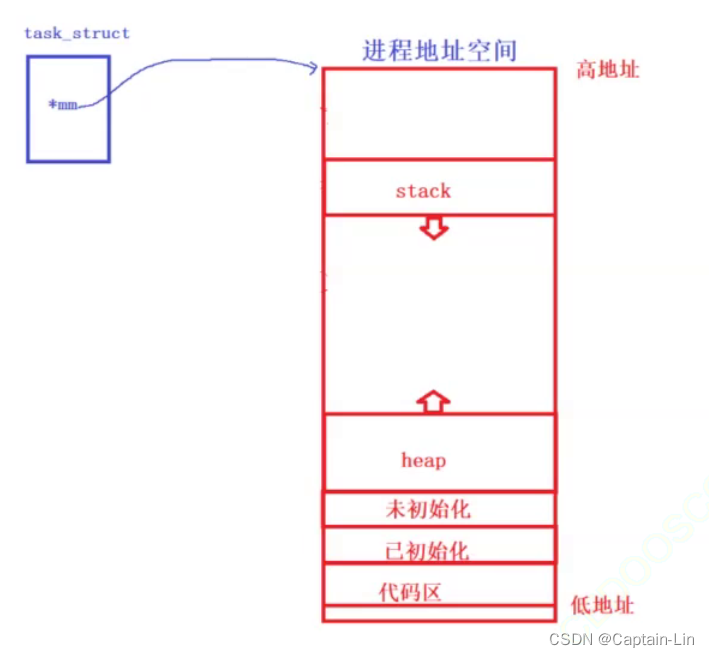
———— 我是一条知识分割线 ————
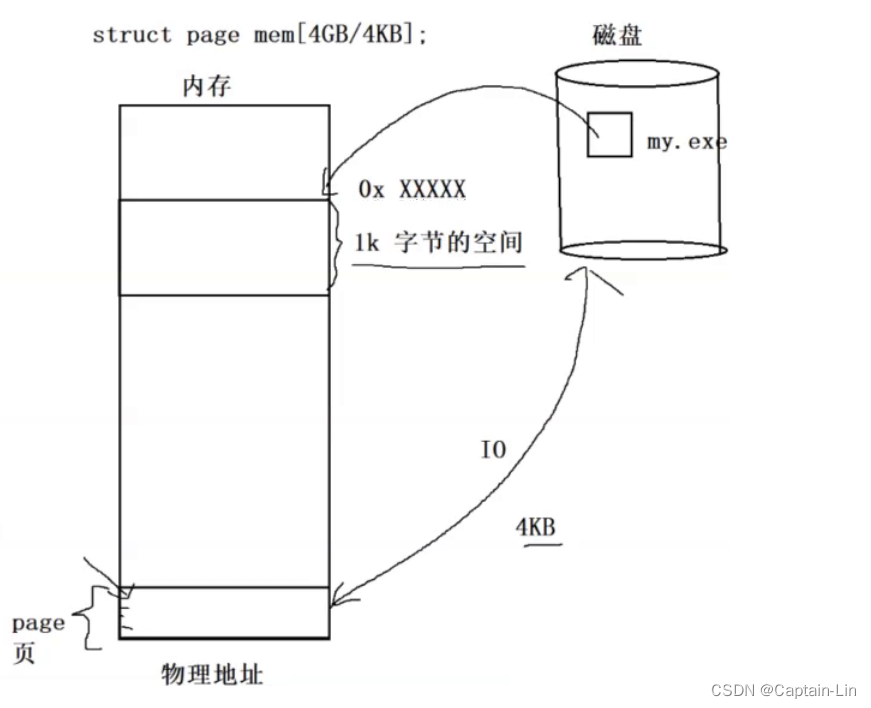
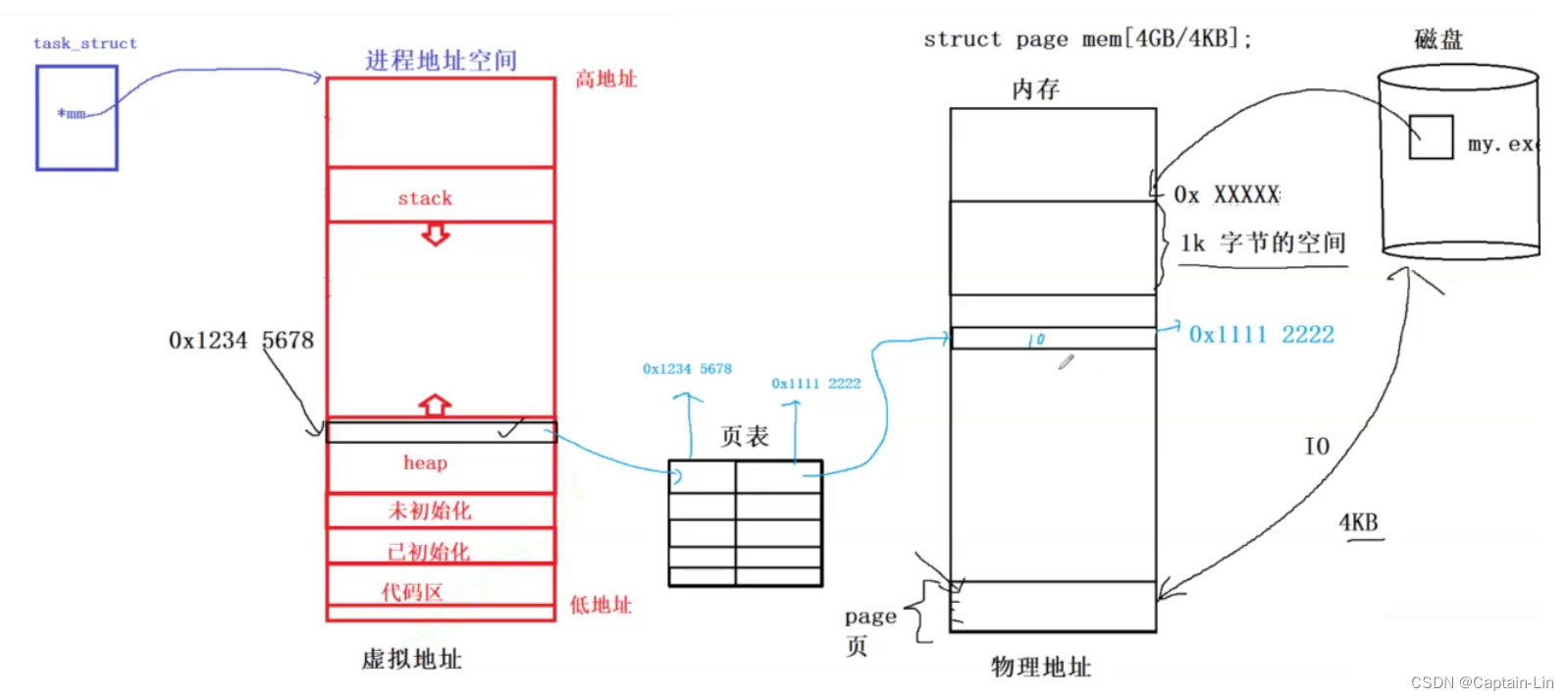
在硬件方面(内存和磁盘),假设有文件 my.exe存在于磁盘之中,当文件加载到内存中,占用内存 1k字节的空间,每个字节我们都可将它视作一个地址。
内存在使用时,它会和我们对应的磁盘进行输入输出数据,这个工作我们称为 IO,其中传输数据的基本单位为 4KB(1KB = 1024字节)。在此基础上,内存可以被我们划分为一个个 4KB大小空间块,这个空间块我们称之为 page(页),如果我们将内存想象为一个大数组,则内存大小或者说对应的页有:struct page men[4GB/4KB]。只要我们知道某一页的起始地址,再加上对应的偏移量,我们就可以找到内存的任意一个地址。
———— 我是一条知识分割线 ————
页表简介:可以用于建立虚拟地址和物理地址之间的映射关系,实现虚拟地址和物理地址的转换。页表内部不是简单的对应空间结构,因为如果这样设计需要占用 4G*8 = 32G。左式中8的含义 - 假设空间为1-1对应结构,左边和右边各一个数据,一个数据需要4个字节表示(int),加起来则需要8个字节。因此,页表内部使用的是多级页表的结构,就是页目录为根,对应多个二级、三级索引这样的结构,这里就不展开细说了。
下图中以浅蓝色标记为例,虚拟地址0x123445678可以通过页表映射找到对应的物理地址 0x11112222,物理空间中储存着 val变量的值为10.
———— 我是一条知识分割线 ————
以下述代码为例讲述程序是如何更改内存中的数据的?
char val = 100;首先我们要明确,val的地址是虚拟地址(在第一节中验证过),当代码运行起来时,操作系统拿着 val的虚拟地址,去查找页表,找到对应的物理地址,将物理地址对应内存空间中的数值修改/存储为100。至此我们已经可以充分认识到程序是如何更改内存中的数据的原理了。
注意:这个过程都是由操作系统完成的!
4.操作系统会根据进程的需求分配虚拟地址空间
进程无法直接访问物理内存,进程只能通过虚拟地址空间来访问对应的数据,其中我们可以认为操作系统给进程画了一个“大饼”(红色正方形框框),每个进程都以为自己能占有 2^32个地址空间(内存大小)。
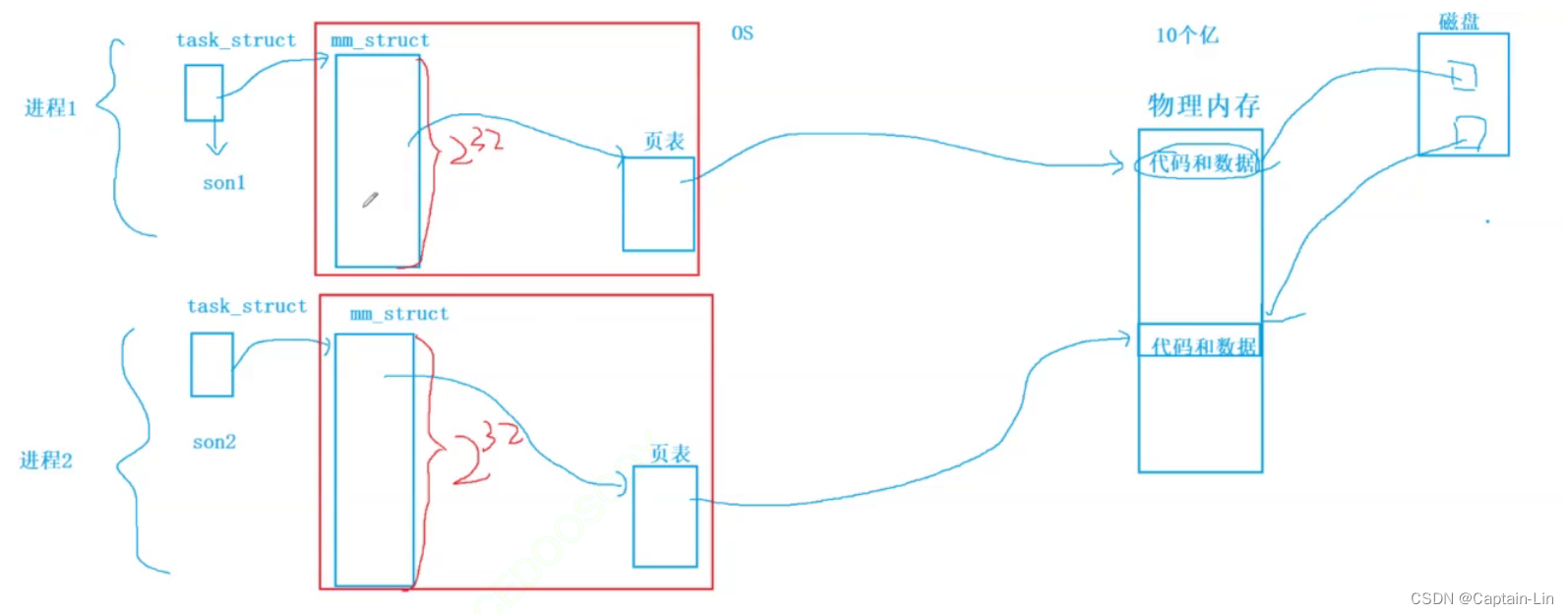
而实际上,我们通过观察,发现堆和栈之间还有很大部分的空缺,不难推断出,操作系统会根据进程对应的需求给进程分配地址空间,而不会真的将所有空间都给一个进程。相反,如果进程的需求不合理,操作系统会拒绝进程的对应访问。
四、为什么存在地址空间
1.防止非法越界访问
如果进程直接访问物理内存,会存在越界非法操作的风险(比如将储存有别的数据的page覆盖)
地址空间的存在,使程序员在应用层只能通过页表映射来访问物理地址,期间操作系统可以帮我们甄别相应指令,接收正确指令,拒绝错误访问。
2.方便进程解耦,保证进程独立性
进程地址空间的存在,可以更方便的让进程与进程之间的数据进行解耦,保证进程独立性
进程具有独立性,一个进程对被共享的数据进行修改,不能影响其他进程。
操作系统为了保证进程独立性,当物理内存中的一个共享数据需要被修改时,操作系统会在物理内存中开辟一个新的空间,数据拷贝一份放到新的空间中,然后会将页表原来对应共享数据空间物理地址改为新空间的地址(更改映射)。这样,在进程改变某个值的时候,就只和这个进程本身有关,和其他进程无关,实现了进程之间的相互独立。
任何一方尝试写入,OS先进行数据拷贝,更改页表映射,然后再让进程进行修改,我们把这样的行为称为写时拷贝。在我们修改数据时,操作系统会帮我们自动完成写时拷贝。
写时拷贝,帮我们实现了数据间的分离。以下图为例,在数据不做修改时,父子进程可以共用同一块物理内存空间,当子进程对数据进行修改,操作系统会通过写时拷贝,实现数据分离,即父进程的 g_val变量和子进程 g_val变量存储于不同的物理地址空间中。
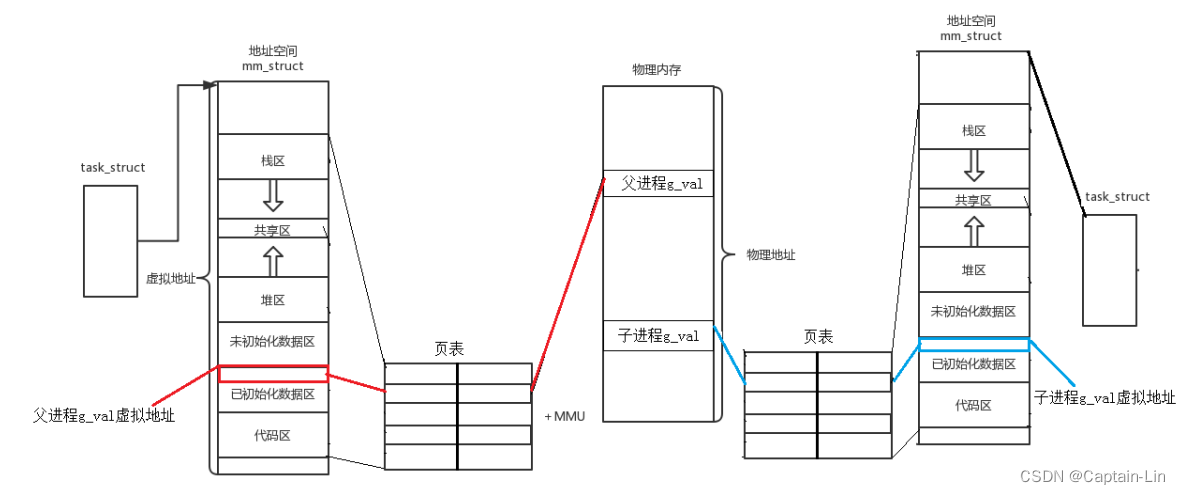
每个进程都有自己独立的内核数据结构,包括独立的PCB、独立的地址空间、独立的页表。
结论:进程 = 进程的内核数据结构 + 进程对应的代码和数据,当进程内核数据结构和对应数据都相互独立时,这个进程也就和其他进程相互独立了。也就是说,地址空间的存在,使进程可以拥有独立的内核数据结构,可以更方便的让进程与进程之间的数据进行解耦,保证进程独立性。
3.统一编译,方便使用
让进程可以以统一的视角,来看待代码和数据的各个区域,方便使用;方便编译器也以统一的视角来编译代码,编完可以直接用。
(1)可执行文件中有地址吗?
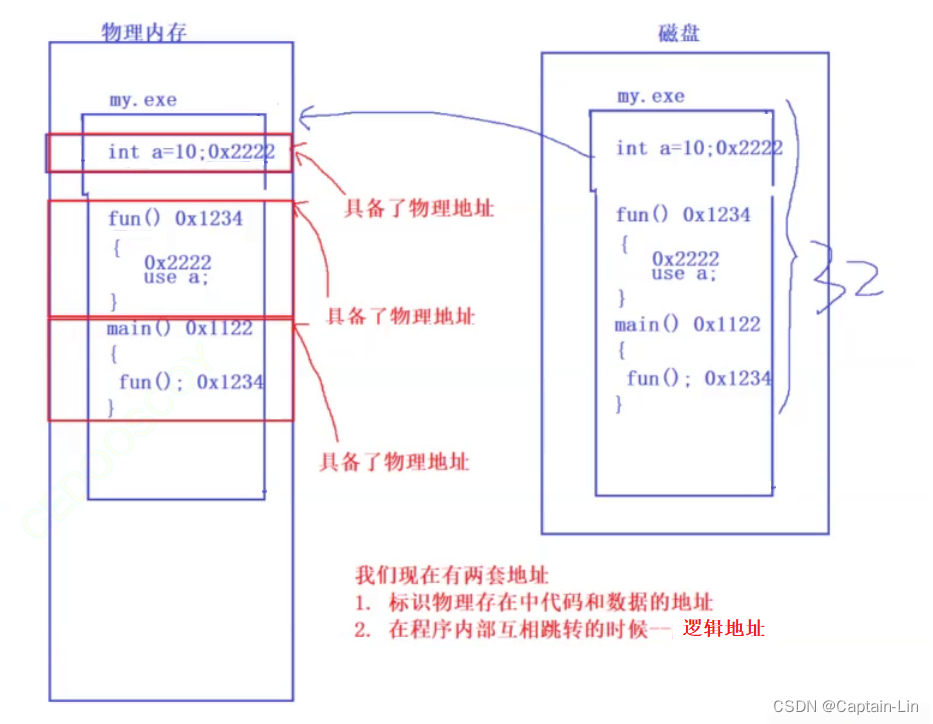
我们的可执行文件中,有没有地址呢?答案是有的,我们的可执行文件中早就有地址了!这种在程序内部使用的地址,我们称它们为 - 逻辑地址。程序可以通过逻辑地址实现内部之间的相互跳转,实现函数调用等功能。
(2)编译器的编码方式
编译器在编译我们的代码和数据时,会按照虚拟地址空间的方式给我们的代码和数据进行编址,也就是它也会按照32位的方式进行编址。
只有栈空间、堆空间对应的数据没有进行编址,因为它们是需要在内存中动态申请的。其他的代码都会完成编址。
(3)物理地址的来源
程序内部使用的地址(逻辑地址),在程序加载到内存时,会天然具有物理地址。因为逻辑地址和物理地址的表示方法相同,所以逻辑地址就是物理地址,不用改变。只不过我们为程序内部的地址起了一个名称 - 逻辑地址,加以辨识罢了。
注意:通常情况下,逻辑地址、物理地址、虚拟地址的表示方式是一样的,都采用32位的数据进行记录。这也就是为什么编译器可以以统一的视角来编译代码,编完可以直接用的原因所在。
———— 我是一条知识分割线 ————
(4)CPU与可执行程序交互的原理
代码编译好加载到内存后,会生成对应的虚拟地址,且在内存中的代码天然具有物理地址。操作系统会用 main函数入口和结束处的虚拟地址等数据,初始化进程虚拟地址空间(主要是代码区)和进程对应的页表,再将虚拟地址空间初始化好的地址加载到CPU的寄存器中。
CPU通过虚拟地址,经过页表映射,找到对应物理地址中数据并进行获取。CPU读进来的都是指令,指令中包含地址,这里的地址是虚拟地址。
CPU处理完数据之后,再将数据通过虚拟地址,经过页表映射,写入到对应物理地址的内存中。
具体图示如下,下图中的地址都是虚拟地址(物理内存中的虚拟地址来源于代码编译生成的虚拟地址)
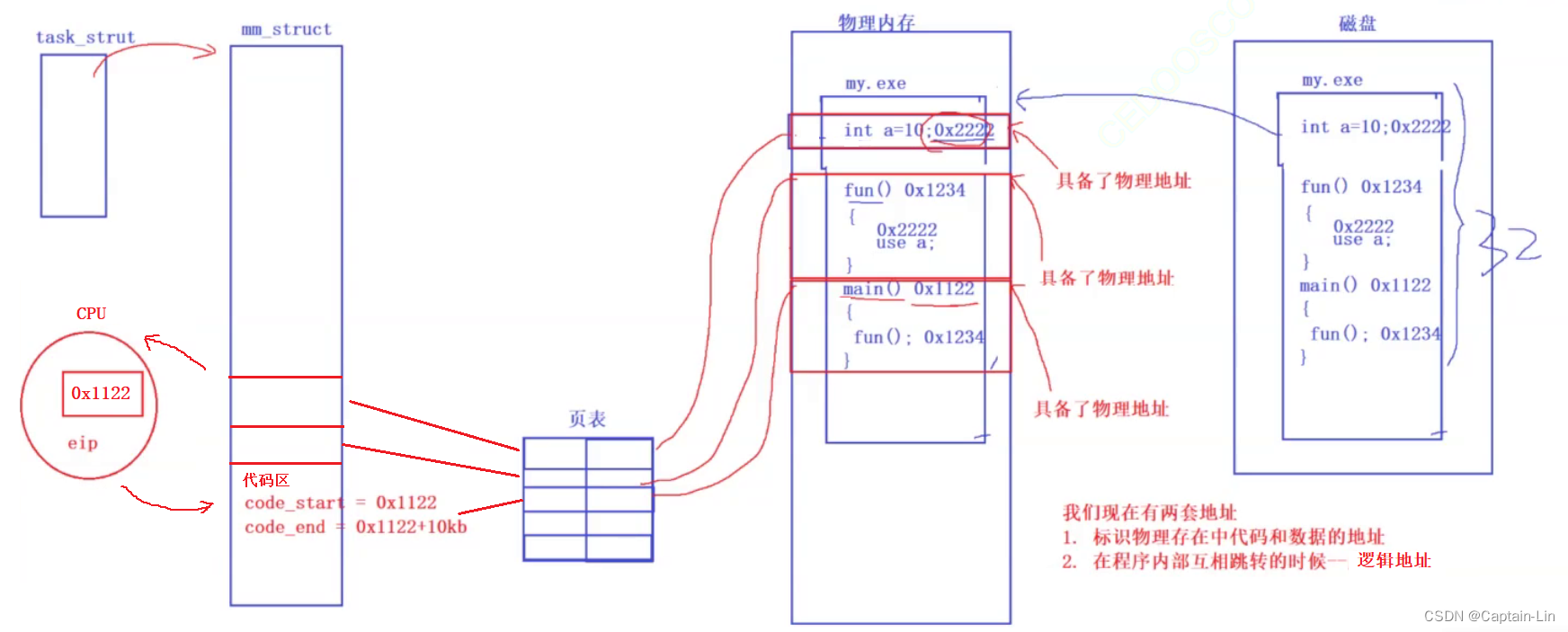
所以,在整个访问过程中,CPU输入输出的都是虚拟地址,CPU压根儿就没有见到物理地址,也即是说CPU不会对物理地址进行直接访问。
在我们对代码进行 debug(调试)时,程序已经运行起来了,此时我们通过监视窗口看到寄存器相关的地址都是虚拟地址。
总结:虚拟进程地址的使用,让进程可以以统一的视角,来看待代码和数据的各个区域,方便使用;
———— 我是一条知识分割线 ————
(5)逻辑地址知识补充
注意:Linux下我们编译可执行程序的格式的编码格式为 ELF
逻辑地址有两种常见的编址方式,一种是线性编址方式,另一种是区域编址方式。这两种生成的都是逻辑地址,但是因为线性编址编出来的地址和物理地址的表示方法相同,因此当程序内部使用线性编址时,在程序加载到内存之后,该程序就天然具有了物理地址。
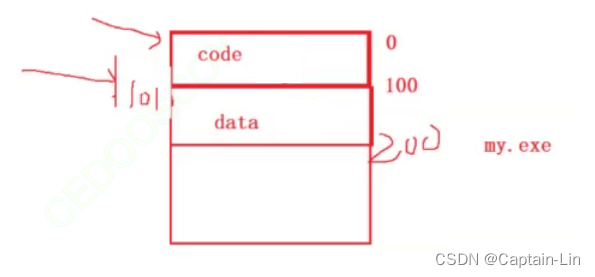
- 线性编址(常用)
地址从0开始,假设普通代码占了100个字节(每个字节一个地址),那么其他数据代码从101个地址开始,继续向下呈线性编址
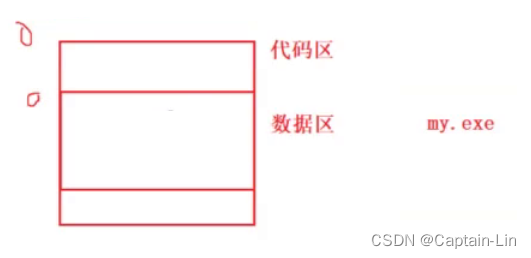
- 区域编址(不常用 - 了解)
区域编址,采用的是区域起始地址加偏移量的方式,当代码加载到内存时,每一个地址都要做修改才能转换成对应的物理地址。因为这种编制方式,使得地址时一块块区域区分开来的,我们可以使用物理地址的起始地址+对应的偏移量,找到对应逻辑地址。
地址从0开始,代码区的普通代码编址完成后,数据区的地址重新从0开始编址,呈现了区域性。
结语
🌹🌹Linux进程地址空间 的知识大概就讲到这里啦,博主后续会继续更新更多Linux操作系统的相关知识,干货满满,如果觉得博主写的还不错的话,希望各位小伙伴不要吝啬手中的三连哦!你们的支持是博主坚持创作的动力!💪💪