一、循环神经网络和自然语言处理介绍
目标
- 知token和tokenization
- 知道N-gram的概念和作用
- 知道文本向量化表示的方法
1.1 文本的tokenization
1.1.1 概念和工具的介绍
tokenization 就是通常所说的分词,分出的每一个词话我们把它称为token。
常见的分词工具很多,比如:
- jieba分词: https://github.com/fxsjy/jieba 。
- 清华大学的分词工具THULAC:
https://github.com/thun1p/THULAC-Python
1.1.2 中英文分词的方法

1.2 N-garm表示方法
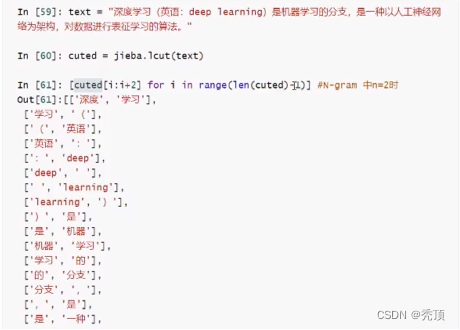
前面我们说,句子可以用但个字,词来表示,但是有的时候,我们可以用2个、3个或者多个词来表
N-gram一组一组的词语,其中的N表示能够被一起使用的词的数量
例如:

1.3 向量化

1.3.1 one-hot编码

1.3.2 word embedding
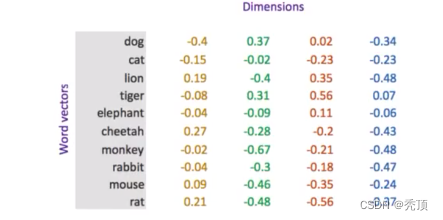
word embedding是深度学习中表示文本常用的一种方法。和one-hot偏码不同,word embedding使用了浮点型的稠密矩阵来表示token。根据词典的大小,我们的向量通常使用不同的维度,例如100,256,300等。其中向呈中的每一个值是一个超参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
如果我们文本中有20000个词语,如果使用one-hot编码,那么我们会有2000020000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000 维度,比如20000*300
形象的表示就是:

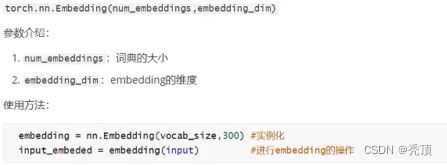
1.3.3 word embedding API

1.3.4 数据的形状变化
思考:每个batch中的每个句子有10个词语,经过形状为[20,4]的Word emebedding之后,原来的句子会变成什么形状?
每个词语用长度为4的向量表示,所以,最终句子会变为 [batch_size,10,4]的形状。增加了一个维度,这个维度是embedding的dim
二、文本情感分类
目标
- 知道文本处理的基本方法
- 能够使用数据实现情感分类的
2.1 案例介绍

2.2 思路分析
首先可以把上述问题定义为分类问题,情感评分分为1-10,10个类别(也可以理解为回归问题,这里当做分类问题考虑)。那么根据之前的经验,我们的大致流程如下:
- 准备数据集
- 构建模型
- 横型训练
- 模型评估
知道思路之后,那么我们一步步来完成上述步骤
2.3 准备数据集

2.3.1 基础Dataset的准备
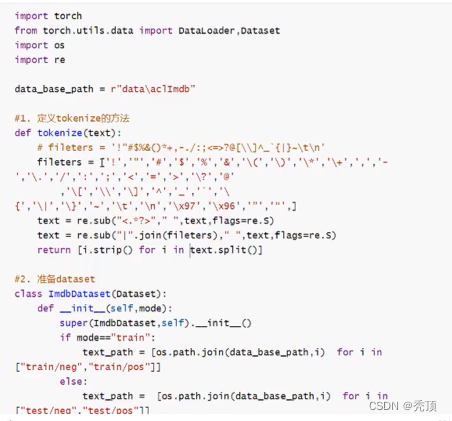


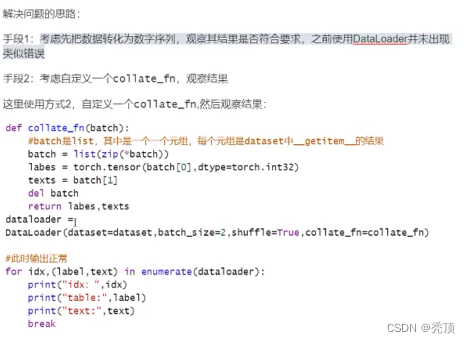
2.3.2 文本序列化
再介绍word embedding的时候,我们说过,不会直接把文本转化为向量,而是先转化为数字,再把数字转化为向量,那么这个过程该如何实现呢?
这里我们可以考虑把文本中的每个词语和其对应的数字,使用字典保存,同时实现方法把句子通过字典映射为包含数字的列表。
实现文本序列化之前,考虑以下几点:
- 如何使用字典把词语和数字进行对应
- 不同的语出现的次数不尽相同,是否需要对高频或者低频词语进行过滤,以及总的词语数量是否需要进行限制
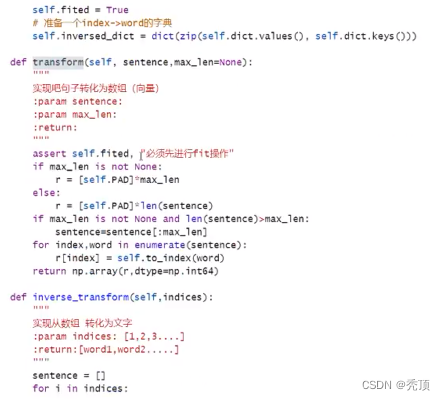
- 得到词典之后,如何把句子转化为数字序列,如何把数字序列转化为句子
- 不同子长度不相同,每个batch的句子如何构造成相同的长度(可以对短句子进行填充,填充特殊字符)
- 对于新出现的词语在词典中没有出现怎么办(可以使用特殊字符代理)
思路分析: - 对所有句了进行分词
- 词语存入字典,根据次数对词语进行过滤,并统计次数
- 实现文本转数字序列的方法
- 实现数字序列转文本方法





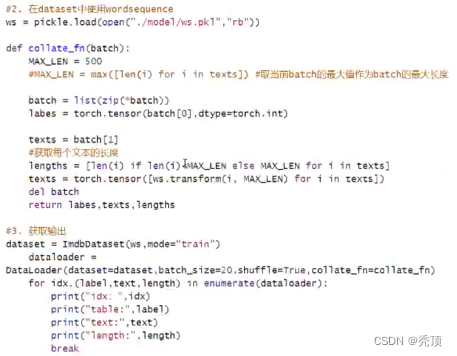

2.4 构建模型

2.5 模型的训练和评估


三、循环神经网络
目标
- 能够说出结环神经网络的概念和作用
- 能够说出循环神经网络的类型和应用场景
- 能够说出LSTM的作用和原理
- 能够说出GRU的作用和原理
3.1 循环神经网络的介绍
为什么有了神经网络还需要有循环神经网络?
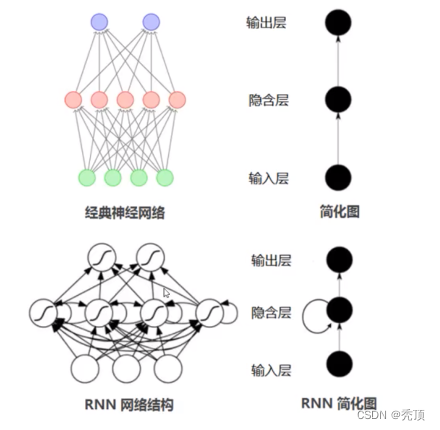
在普通的神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。特别是在很多现实任务中,网络的输出不仅和当前时刻的输入相关,也和具过去一段时间的输出相关。此外,普通网络难以处理时序数据,比如视频、语音、文本等,时序数据的长度一般显不固定的,而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变,因此,当处理这一类和时序相关的问题时,就需要一种能力更强的悦型。
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其它神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。换句话说:神经元的输出可以在下一个时间步直接作用到自身(作为输入)
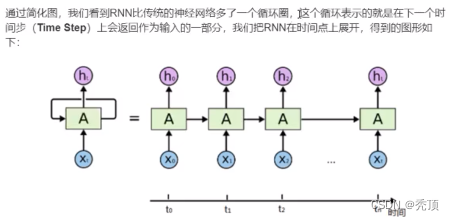
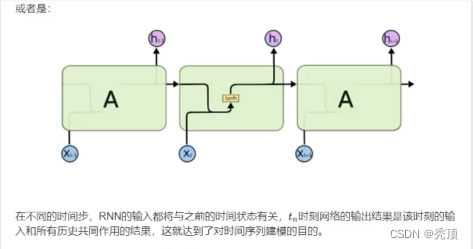
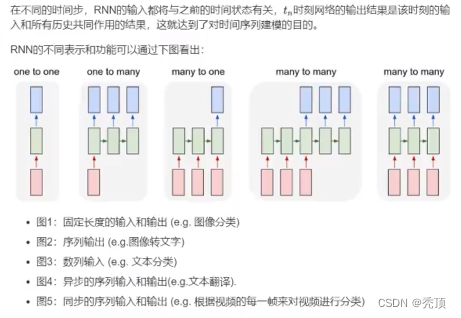
3.2 LSTM和GRU
3.2.1 LSTM的基础介绍
假如现在有这样一个需求,根掘现有文本预测下一个词语,比如天上的云朵漂浮在_,通过问隔不远的位置就可以预测出来词语是天上,但是对于其他一些句子,可能需要被预测的词语在前100个词语之前,那么此时由于间隔非常大,随着间隔的增加可能会导致真实的预测值对结果的影响变的非常小,而无法非常好的进行预测(RNN中的长期依赖问题 (long-TermDependencies))
那么为了解决这个问题需要LSTM (Long Short-Term Memory网络)
LSTM是一种RNN特殊的类型,可以学习长期依赖信息。在很多问题上,LSTM都取得相当巨大的成功,并得到了广泛的应用。
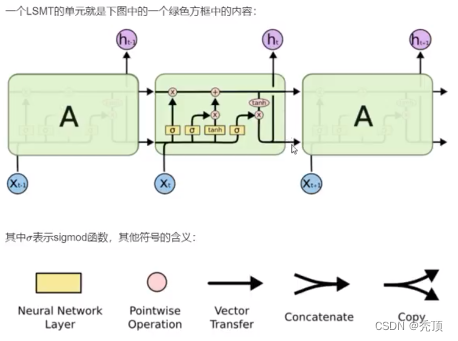
3.2.2 LSTM的核心
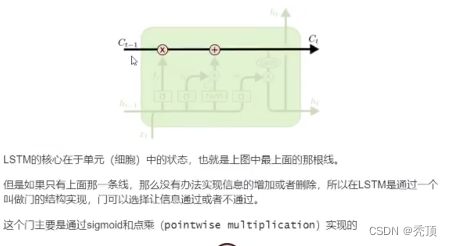
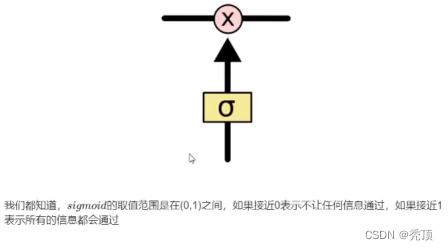
3.2.3 逐步理解LSTM
3.2.3.1 遗忘门
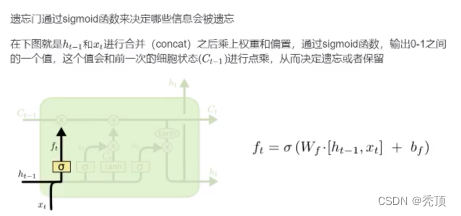
3.2.3.2 输入门
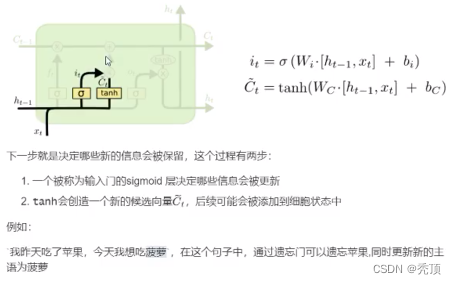
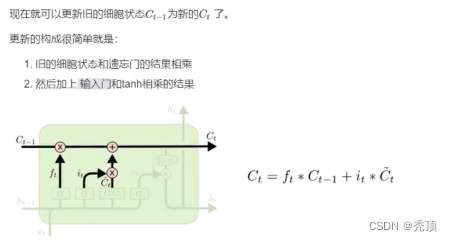
3.2.3.3 输出门

3.2.4 GRU,LSTM的变形
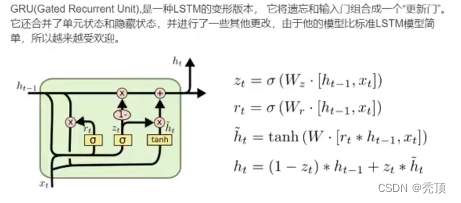
LSTM内容参考地址: https://colah.github.ioposts/2015-08-Understanding:LSTMs/
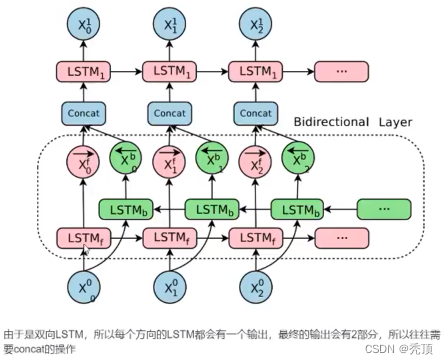
3.3 双向LSTM
单向的 RNN,是根据前面的信息推出后面的,但有时候只看前面的词是不够的,可能需要预测的词语和后面的内容也相关,那么此时需要一种机制,能够让模型不仅能够从前往后的具有记忆,还需要从后往前需要记忆。此时双向LSTM就可以帮助我们解决这个问题
四、循环神经网络实现情感分类
目标
- 知道LSTM和GRU的使用方法及输入输出的格式
- 能够应用LSTM和GRU实现文本情感分类
4.1 Pytorch中LSTM和GRU模块使用
4.1.1 LSTM介绍


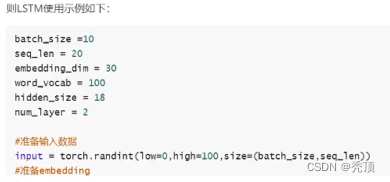
4.1.2 LSTM使用示例
假设数掘输入为 input,形状是[10,20],假设embedding的形状是[100,30]
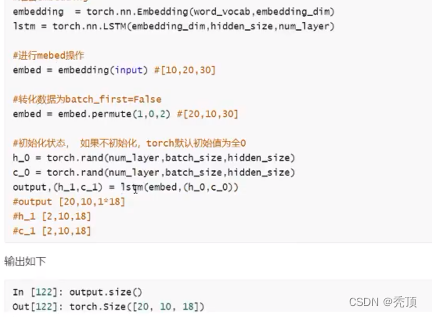

4.1.2 LSTM和GRU的使用注意点

4.2 使用LSTM完成文本情感分类
在前面,我们使用了word embedding去实现了toy级别的文本情感分类,那么现在我们在这个模型中添加上LSTM层,观察分类效果。
为了达到更好的效果,对之前的模型做如下修改
- MAX_LEN = 200
- 构建dataset的过程,把数据转化为2分类的问题,pos为1,neg为0,否则25000个样本完成10个类别的划分数据量是不够的
- 在实例化LSTM的时候,使用dropout=0.5,在model.eval0的过程中,dropout自动会为0
五、Pythorch中的序列化容器
目标
- 知道梯度消失和梯度爆炸的原理和解决方法
- 能够使用nn.sequentia1完成模型的搭建
- 知道nn.BatchNormld的使用方法
- 知道nn.Dropout 的使用方法
5.1 梯度消失和梯度爆炸
在使用pytorch中的序列化 容器之前,我们先来了解一下常见的梯度消失和梯度海炸的问题
5.1.1 梯度消失
假设我们有四层极简神经网络:每层只有一个神经元
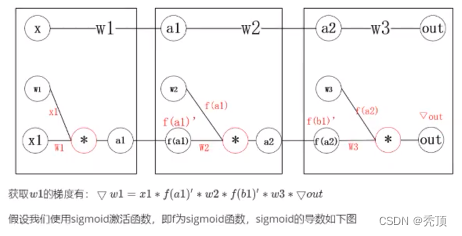
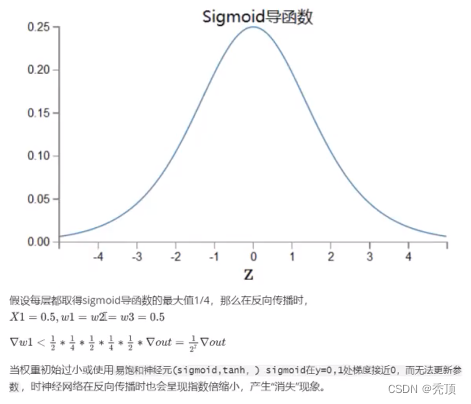
5.1.2 梯度爆炸

5.1.3 解决梯度消失或者梯度爆炸的经验

5.2 nn.Sequential
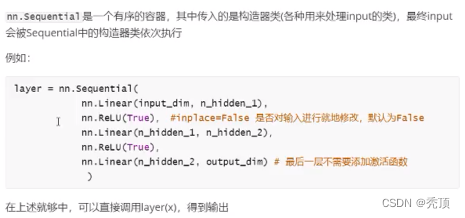

5.3 nn.BatchNormld
batch normalization 翻泽成中文就是批规范化,即在每个batch训练的过程中,对参数进行归一化的处理,从而达到加快训练速度的效果。
以sigmoid激活函数为例,他在反向传摇的过程中,在值为0,1的时候,梯度接近0,导致参数被更新的幅度很小,训练速度慢。但是如果对数掘进行归一化之后,就会尽可能的把数据拉倒[0-1]的范围,从而让参数更新的幅度变大,提高训练的速度。
batchNorm一般会放到激活函数之后,即对输入进行激活处理之后再进入batchNorm

5.4 nn.Dropout








![[TIST 2022]No Free Lunch Theorem for Security and Utility in Federated Learning](https://img-blog.csdnimg.cn/14d1e6b8669545c4b1bec1b6055cc7e4.png)