[Java面试知识点(全)
导航: https://nanxiang.blog.csdn.net/article/details/130640392
注:随时更新
ThreadPoolExecutor
如果不了解这个类,应该了解前面提到的ExecutorService,开一个自己的线程池非常方便:
ExecutorService e = Executors.newCachedThreadPool();
ExecutorService e = Executors.newSingleThreadExecutor();
ExecutorService e = Executors.newFixedThreadPool(3);
// 第一种是可变大小线程池,按照任务数来分配线程,
// 第二种是单线程池,相当于FixedThreadPool(1)
// 第三种是固定大小线程池。
// 然后运行
e.execute(new MyRunnableImpl());
该类内部是通过ThreadPoolExecutor实现的,掌握该类有助于理解线程池的管理,本质上,他们都是ThreadPoolExecutor类的各种实现版本。请参见javadoc:
ThreadPoolExecutor参数解释
corePoolSize:池内线程初始值与最小值,就算是空闲状态,也会保持该数量线程。
maximumPoolSize:线程最大值,线程的增长始终不会超过该值。
keepAliveTime:当池内线程数高于corePoolSize时,经过多少时间多余的空闲线程才会被回收。回收前处于wait状态
unit:
时间单位,可以使用TimeUnit的实例,如TimeUnit.MILLISECONDS
workQueue:待入任务(Runnable)的等待场所,该参数主要影响调度策略,如公平与否,是否产生饿死(starving)
threadFactory:线程工厂类,有默认实现,如果有自定义的需要则需要自己实现ThreadFactory接口并作为参数传入。
ThreadPoolExecutor工作原理
线程池的处理流程
向线程池提交一个任务后,它的主要处理流程如下图所示

一个线程从被提交(submit)到执行共经历以下流程:
线程池判断核心线程池里是的线程是否都在执行任务,如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下一个流程
线程池判断工作队列是否已满。如果工作队列没有满,则将新提交的任务储存在这个工作队列里。如果工作队列满了,则进入下一个流程。
线程池判断其内部线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已满了,则交给饱和策略来处理这个任务。
线程池在执行excute方法时,主要有以下四种情况

1 如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(需要获得全局锁)
2 如果运行的线程等于或多于corePoolSize ,则将任务加入BlockingQueue
3 如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(需要获得全局锁)
4 如果创建新线程将使当前运行的线程超出maxiumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
分布式环境下,怎么保证线程安全
-
避免并发
在分布式环境中,如果存在并发问题,那么很难通过技术去解决,或者解决的代价很大,所以我们首先要想想是不是可以通过某些策略和业务设计来避免并发。比如通过合理的时间调度,避开共享资源的存取冲突。另外,在并行任务设计上可以通过适当的策略,保证任务与任务之间不存在共享资源,比如在以前博文中提到的例子,我们需要用多线程或分布式集群来计算一堆客户的相关统计值,由于客户的统计值是共享数据,因此会有并发潜在可能。但从业务上我们可以分析出客户与客户之间 数据是不共享的,因此可以设计一个规则来保证一个客户的计算工作和数据访问只会被一个线程或一台工作机完成,而不是把一个客户的计算工作分配给多个线程去 完成。这种规则很容易设计,例如可以采用hash算法。 -
时间戳
分布式环境中并发是没法保证时序的,无论是通过远程接口的同步调用或异步消息,因此很容易造成某些对时序性有要求的业务在高并发时产生错误。比如系统A需要把某个值的变更同步到系统B,由于通知的时序问题会导致一个过期的值覆盖了有效值。对于这个问题,常用的办法就是采用时间戳的方式,每次系统A发送变更给系统B的时候需要带上一个能标示时序的时间戳,系统B接到通知后会拿时间戳与存在的时间戳比较,只有当通知的时间戳大于存在的时间戳,才做更新。这种方式比较简单,但关键在于调用方一般要保证时间戳的时序有效性。 -
串行化
有的时候可以通过串行化可能产生并发问题操作,牺牲性能和扩展性,来满足对数据一致性的要求。比如分布式消息系统就没法保证消息的有序性,但可以通过变分布式消息系统为单一系统就可以保证消息的有序性了。另外,当接收方没法处理调用有序性,可以通过一个队列先把调用信息缓存起来,然后再串行地处理这些调用。 -
数据库
分布式环境中的共享资源不能通过Java里同步方法或加锁来保证线程安全,但数据库是分布式各服务器的共享点,可以通过数据库的高可靠一致性机制来满足需求。比如,可以通过唯一性索引来解决并发过程中重复数据的生产或重复任务的执行;另外有些更新计算操作也尽量通过sql来完成,因为在程序段计算好后再去更新就有可能发生脏复写问题,但通过一条sql来完成计算和更新就可以通过数据库的锁机制来保证update操作的一致性。
行锁
有的事务比较复杂,无法通过一条sql解决问题,并且有存在并发问题,这时就需要通过行锁来解决,一般行锁可以通过以下方式来实现:
对于Oracle数据库,可以采用select … for update方式。这种方式会有潜在的危险,就是如果没有commit就会造成这行数据被锁住,其他有涉及到这行数据的任务都会被挂起,应该谨慎使用
在表里添加一个标示锁的字段,每次操作前,先通过update这个锁字段来完成类似竞争锁的操作,操作完成后在update锁字段复位,标示已归还锁。这种方式比较安全,不好的地方在于这些update锁字段的操作就是额外的性能消耗
统一触发途径
当一个数据可能会被多个触发点或多个业务涉及到,就有并发问题产生的隐患,因此可以通过前期架构和业务设计,尽量统一触发途径,触发途径少了一是减少并发的可能,也有利于对于并发问题的分析和判断。
乐观锁悲观锁
在数据库的锁机制中介绍过,数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。
乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
无论是悲观锁还是乐观锁,都是人们定义出来的概念,可以认为是一种思想。其实不仅仅是关系型数据库系统中有乐观锁和悲观锁的概念,像memcache、hibernate、tair等都有类似的概念。
针对于不同的业务场景,应该选用不同的并发控制方式。所以,不要把乐观并发控制和悲观并发控制狭义的理解为DBMS中的概念,更不要把他们和数据中提供的锁机制(行锁、表锁、排他锁、共享锁)混为一谈。其实,在DBMS中,悲观锁正是利用数据库本身提供的锁机制来实现的。
下面来分别学习一下悲观锁和乐观锁。
- 悲观锁
在关系数据库管理系统里,悲观并发控制(又名“悲观锁”,Pessimistic Concurrency Control,缩写“PCC”)是一种并发控制的方法。它可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作都某行数据应用了锁,那只有当这个事务把锁释放,其他事务才能够执行与该锁冲突的操作。
悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度(悲观),因此,在整个数据处理过程中,将数据处于锁定状态。 悲观锁的实现,往往依靠数据库提供的锁机制 (也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)
在数据库中,悲观锁的流程如下:
在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
其间如果有其他对该记录做修改或加排他锁的操作,都会等待我们解锁或直接抛出异常。
MySQL InnoDB中使用悲观锁
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。set autocommit=0;
//0.开始事务
begin;/begin work;/start transaction; (三者选一就可以)
//1.查询出商品信息
select status from t_goods where id=1 for update;
//2.根据商品信息生成订单
insert into t_orders (id,goods_id) values (null,1);
//3.修改商品status为2
update t_goods set status=2;
//4.提交事务
commit;/commit work;
上面的查询语句中,我们使用了select…for update的方式,这样就通过开启排他锁的方式实现了悲观锁。此时在t_goods表中,id为1的 那条数据就被我们锁定了,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。
上面我们提到,使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认行级锁。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
优点与不足
悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;另外,在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还有会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数
- 乐观锁
在关系数据库管理系统里,乐观并发控制(又名“乐观锁”,Optimistic Concurrency Control,缩写“OCC”)是一种并发控制的方法。它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。乐观事务控制最早是由孔祥重(H.T.Kung)教授提出。
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
数据版本,为数据增加的一个版本标识。当读取数据时,将版本标识的值一同读出,数据每更新一次,同时对版本标识进行更新。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对,如果数据库表当前版本号与第一次取出来的版本标识值相等,则予以更新,否则认为是过期数据。
实现数据版本有两种方式,第一种是使用版本号,第二种是使用时间戳。
使用版本号实现乐观锁
使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。
1.查询出商品信息
select (status,status,version) from t_goods where id=#{id}
2.根据商品信息生成订单
3.修改商品status为2
update t_goods
set status=2,version=version+1
where id=#{id} and version=#{version};
优点与不足
乐观并发控制相信事务之间的数据竞争(data race)的概率是比较小的,因此尽可能直接做下去,直到提交的时候才去锁定,所以不会产生任何锁和死锁。但如果直接简单这么做,还是有可能会遇到不可预期的结果,例如两个事务都读取了数据库的某一行,经过修改以后写回数据库,这时就遇到了问题
CAS
CAS无锁实现原理
为什么要用CAS
在多线程高并发编程的时候,最关键的问题就是保证临界区的对象的安全访问。通常是用加锁来处理,其实加锁本质上是将并发转变为串行来实现的,势必会影响吞吐量。而且线程的数量是有限的,依赖于操作系统,而且线程的创建和销毁带来的性能损耗是不可以忽略掉的。虽然现在基本都是用线程池来尽可能的降低不断创建线程带来的性能损耗。
对于并发控制而言,锁是一种悲观策略,会阻塞线程执行。而无锁是一种乐观策略,它会假设对资源的访问时没有冲突的,既然没有冲突就不需要等待,线程不需要阻塞。那多个线程共同访问临界区的资源怎么办呢,无锁的策略采用一种比较交换技术CAS(compare and swap)来鉴别线程冲突,一旦检测到冲突,就充实当前操作指导没有冲突为止。
与锁相比,CAS会使得程序设计比较负责,但是由于其优越的性能优势,以及天生免疫死锁(根本就没有锁,当然就不会有线程一直阻塞了),更为重要的是,使用无锁的方式没有所竞争带来的开销,也没有线程间频繁调度带来的开销,他比基于锁的方式有更优越的性能,所以在目前被广泛应用,我们在程序设计时也可以适当的使用.
不过由于CAS编码确实稍微复杂,而且jdk作者本身也不希望你直接使用unsafe(后面会讲到)来进行代码的编写,所以如果不能深刻理解CAS以及unsafe还是要慎用,使用一些别人已经实现好的无锁类或者框架就好了。
java.util.concurrent包中借助CAS实现了区别于synchronouse同步锁的一种乐观锁
CAS原理分析
CAS算法
一个CAS方法包含三个参数CAS(V,E,N)。V表示要更新的变量,E表示预期的值,N表示新值。只有当V的值等于E时,才会将V的值修改为N。如果V的值不等于E,说明已经被其他线程修改了,当前线程可以放弃此操作,也可以再次尝试次操作直至修改成功。基于这样的算法,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰(临界区值的修改),并进行恰当的处理。
额外引申技术点:volatile
上面说到当前线程可以发现其他线程对临界区数据的修改,这点可以使用volatile进行保证。
volatile实现了JMM中的可见性。使得对临界区资源的修改可以马上被其他线程看到,它是通过添加内存屏障实现的。具体实现原理请自行搜索volatile
AtomicInteger
初次接触CAS的人一般都是通过AtomicInteger这个类来了解的,这里讲其原理也借助这个类。
查看一下AtomicInteger的源码:
private volatile int value;
//此处省略一万字代码
/**
* Atomically sets to the given value and returns the old value.
*
* @param newValue the new value
* @return the previous value
*/
public final int getAndSet(int newValue) {
for (;;) {
int current = get();
if (compareAndSet(current, newValue))
return current;
}
}
/**
* Atomically sets the value to the given updated value
* if the current value {@code ==} the expected value.
*
* @param expect the expected value
* @param update the new value
* @return true if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
通过这段代码可知:
- AtomicInteger中真正存储数据的是value变量,而改变量是被volatile修饰的,保证了线程直接的可见性。还记得Integer中的value吗?Integer中的value是被final修饰的,是不可变对象。
- getAndSet方法通过一个死循环不断尝试赋值操作。而真正的赋值操作交给了unsafe类来实现。
unsafe
上面可知,Unsafe类是CAS实现的核心。
从名字可知,这个类标记为不安全的,JDK作者不希望用户使用这个类,我们看一下他的构造方法:
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if(var0.getClassLoader() != null) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
如果ClassLoader不是null,直接抛出异常了,我们没办法在应用程序中使用这个类
public static void main(String[] args){
Unsafe unsafe = Unsafe.getUnsafe();
}
main方法运行结果:
Exception in thread “main” java.lang.SecurityException: Unsafe
at sun.misc.Unsafe.getUnsafe(Unsafe.java:90)
at com.le.luffi.Tewast.main(Tewast.java:13)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
```
我们来看一下compareAndSwapInt的方法声明
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
第一个参数是给定的对象,offset是对象内的偏移量(其实就是一个字段到对象头部的偏移量,通过这个偏移量可以快速定位字段),第三个参数是期望值,最后一个是要设置的值。
其实这里Unsafe封装了一些类似于C++中指针的东西,该类中的方法都是native的,而且是原子的操作。原子性是通过CAS原子指令实现的,由处理器保证。
讲到这里相信读者肯定明白CAS是个什么鬼了。
在java领域的广泛应用
jdk中的CAS实现
java.util.concurrent.atomic包
该包下的类都是采用CAS来实现的无锁,读者可以亲自去尝试使用。

跳跃表java.util.concurrent.ConcurrentSkipListMap
ConcurrentSkipListMap采用典型的空间换取时间策略,它是一个有序的,支持高并发的Map.
实现原理参见 Java多线程(四)之ConcurrentSkipListMap深入分析
他对节点的操作都是CAS机制实现的
无锁队列java.util.concurrent.ConcurrentLinkedQueue
实现原理参见 聊聊并发(六)ConcurrentLinkedQueue的实现原理分析
并发编程网是个不错的网站
JVM中的CAS
堆中对象的分配
我们都知道java调用new object()会创建一个对象,这个对象会被分配到JVM的堆中。那么这个对象到底是怎么在堆中保存的呢?
首先,new object()执行的时候,这个对象需要多大的空间,其实是已经确定的,因为java中的各种数据类型,占用多大的空间都是固定的(对其原理不清楚的请自行Google)。那么接下来的工作就是在堆中找出那么一块空间用于存放这个对象。
在单线程的情况下,一般有两种分配策略:
指针碰撞
这种一般适用于内存是绝对规整的(内存是否规整取决于内存回收策略),分配空间的工作只是将指针像空闲内存一侧移动对象大小的距离即可。
空闲列表
这种适用于内存非规整的情况,这种情况下JVM会维护一个内存列表,记录那些内存区域是空闲的,大小是多少哦啊。给对象分配空间的时候去空闲列表里查询到合适的区域然后进行分配即可
但是JVM不可能一直在单线程状态下运行,那样效率太差了。由于再给一个对象分配内存的时候不是原子性的操作,至少需要以下几步:查找空闲列表、分配内存、修改空闲列表等等,这是不安全的。解决并发时的安全问题也有两种策略:
CAS
实际上虚拟机采用CAS配合上失败重试的方式保证更新操作的原子性,原理和上面讲的一样。
TLAB
如果使用CAS其实对性能还是会有影响的,所以JVM又提出了一种更高级的优化策略:每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲区(TLAB),线程内部需要分配内存时直接在TLAB上分配就行,避免了线程冲突。只有当缓冲区的内存用光需要重新分配内存的时候才会进行CAS操作分配更大的内存空间。
虚拟机是否使用TLAB,可以通过-XX:+/-UseTLAB参数来进行配置(jdk5及以后的版本默认是启用TLAB的)。
CAS缺点
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作
-
ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。 -
循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
-
只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
重载和重写
- 重载(Overloading)
方法重载是让类以统一的方式处理不同类型数据的一种手段。多个同名函数同时存在,具有不同的参数个数/类型。
重载Overloading是一个类中多态性的一种表现。
Java的方法重载,就是在类中可以创建多个方法,它们具有相同的名字,但具有不同的参数和不同的定义。
调用方法时通过传递给它们的不同参数个数和参数类型来决定具体使用哪个方法, 这就是多态性。
重载的时候,方法名要一样,但是参数类型和个数不一样,返回值类型可以相同也可以不相同。无法以返回型别作为重载函数的区分标准。
父类方法被默认修饰时,只能在同一包中,被其子类被重写,如果不在同一包则不能重写。
父类的方法被protoeted时,不仅在同一包中,被其子类被重写,还可以不同包的子类重写。
重写方法的规则:
1)、参数列表必须完全与被重写的方法相同,否则不能称其为重写而是重载。
2)、返回的类型必须一直与被重写的方法的返回类型相同,否则不能称其为重写而是重载。
3)、访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)
4)、重写方法一定不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常。例如:
而重载的规则:
1)、必须具有不同的参数列表;
2)、可以有不同的返回类型,只要参数列表不同就可以了;
3)、可以有不同的访问修饰符;
4)、可以抛出不同的异常
- override(重写)
1、方法名、参数、返回值相同。
2、子类方法不能缩小父类方法的访问权限。
3、子类方法不能抛出比父类方法更多的异常(但子类方法可以不抛出异常)。
4、存在于父类和子类之间。
5、方法被定义为final不能被重写。
overload(重载)
1、参数类型、个数、顺序至少有一个不相同。
2、不能重载只有返回值不同的方法名。
3、存在于父类和子类、同类中。
http请求过程
想象用浏览器打开imooc.com网站,HTTP走过的环节:
1.首先,是对imooc.com域名解析,
(1.1)浏览器搜索浏览器自身的DNS缓存。(DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串)
(1.2)如果浏览器没有找到自身的DNS缓存或之前的缓存已失效,那么浏览器会搜索操作系统自身的DNS缓存。
(1.3)如果操作系统的DNS缓存也没有找到,那么系统会尝试在本地的HOST文件去找。(Hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,一旦找到,系统会立即打开对应网页,如果没有找到,则系统再会将网址提交DNS域名解析服务器进行IP地址的解析)
(1.4)如果在HOST里依然没有找到,浏览器会发起一个DNS的系统调用,即一般向本地的宽带运营商发起域名解析请求。这后面又可以试情况分很多步骤,第一,宽带运营商服务器会首先查看自身的缓存,看是否有结果,如果没有,那么运营商服务器会发起一个迭代DNS解析请求(根域,顶级域,域名注册商),最终会返回对DNS解析的结果。运营商服务器然后把结果返回给操作系统内核(同时也缓存在自己的缓存区),然后操作系统把结果返回给浏览器。
(1.5)以上的最终结果,是让浏览器拿到imooc.com的IP地址,DNS解析完成。
2.然后,在浏览器获得域名的IP地址后,发起“三次握手”,建立TCP/IP连接。
3.在TCP/IP连接建立起来后,浏览器就可以向服务器发送HTTP请求了。比如,用HTTP的GET方法请求一个根域里的某个域名,协议可以采用HTTP 1.0 。
4.服务器端接受这个请求,根据路径参数,经过后端的一些处理之后,把处理后的一个结果以数据的形式返回给浏览器,如果是imooc.com网站的页面,服务器就会把完整的HTML页面代码返回给浏览器。
5.浏览器拿到了imooc.com这个网站的完整HTML页面代码,在解析和渲染这个页面的时候,里面的Javascript、CSS、图片等静态资源,它们同样也是一个个HTTP请求,都需要经过上面的步骤来获取。
6.浏览器根据拿到的资源对页面进行渲染,最终把一个完整的页面呈现出来。
可以简单地把http拆分成请求和响应,然后他们都有http头和正文信息,http头发送的是一些附加的信息:内容类型,服务器发送响应的日期,http状态码。正文就是用户提交的表单数据。
域名解析->域名 ->缓存->根域dns->顶级域dns->本域dns->服务器IP
1.搜索浏览器自身DNS缓存,如果不存在或者过期(>60s)放弃
2.搜索操作系统自身的dns缓存
3.读取本地的HOST文件
4.浏览器发起一个DNS的系统调用 域名解析
5.客户端通过随机端口使用tcp协议服务器ip的80端口发起连接请求 三次握手
6.tcp/ip连接请求建立后浏览器可以向服务器发起http请求
7.http客户端发起请求,创建端口,解析用户操作,拼接请求头信息
8.http客户端并向服务器的该端口发送request头信息
9.服务器监听端口 如80
10.http监听到发到80端口的请求头信息
11.http服务器解析头信息
12.http服务器 按照请求头信息,返回相应响应头信息response
13.响应头信息发送给http客户端,客户端解析响应头信息,并完成其他操作
14.完成一次http请求
waiting(TTFB):表示请求发出到收到响应中第一个字节所耗费的时间。
-
请求方法
get:请求资源
post:提交资源
put:更新
delete:删除
head:类似get
trace
options -
服务器请求状态码:
1XX:指示信息,表示信息已接收,正在处理
2XX:已成功接收并处理。
3XX:重定向
4XX:客户端错误
5XX:服务器端错误
1XX请求已接收,正在处理XX
2XX,,请求接受成功,处理完成,成功返回,200=0k
3XX,,重定向
4XX,,客户端错误,400 有语法错误不能理解,401请求未授权,403拒绝提供服务,404 未找到改地址,对象不存在
5XX,,服务器端错误,500服务器发生未知错误,503服务器端当前不能处理
通过自己的理解这些问题
1.回调,即后续处理的函数作为参数出现在前驱函数中,对前驱函数中的一些操作进行处理
2.同步与异步
同步是指后一项任务必须在前一项任务执行完毕后执行,程序的执行顺序和任务的排列顺序是一致的
//同步 打电话 等待 查询 返回结果 挂电话
//异步 打电话 留号码 说明查询 挂电话 出结果 回电话 完成
//同步 下载 等待 完成 看片儿
//异步 下载a 下载b 下载c 下载完播放提示音看片儿 顺序不定
3.单线程/多线程
今天周日,人多,但是你还是一个人给自己挂号,你就是单线程的
本周日,漩涡鸣人用多重影分身给自己挂号,鸣人就是多线程的
4.i/o
磁盘的写入 挂号的时候护士把你的信息录入,这就是写入
磁盘的读出 你挂完号去看病,轮到你了,医生把你的信息调出来,82岁 未婚, 哦,大龄单身狗啊,这就是读出
5.阻塞/非阻塞
医生告诉你你得好好检查检查,然后对你一阵敲敲打打,你啥也干不了,只能被动享受,你就被阻塞了
医生拍个片子就让你滚回家,说看看,过两天电话通知你结果,你想干啥就干啥,你就是非阻塞的
6.事件/事件驱动
事件并不是立即执行,而是等待驱动(比如click)时才会被执行
为了某个事件注册了回调函数,但是这个回调函数不是马上执行,只有当事件发生的时候,才会调用回调函数,这种函数执行的方式叫做事件驱动~这种注册回调就是基于事件驱动的回调,如果这些回调和异步的I/O操作有关,可以看作是基于回调的异步I/O,只不过这种回调在nodejs中是有事件来驱动的
7.事件循环 回调函数队列
倘若有大量的异步操作以及io的耗时操作,甚至是定时器控制的延时操作,都要去调用相应的回调函数,从而完成密集任务,而又不会阻塞整个程序的流程,就需要一个机制来管理,这个机制就是event loop
classLoader加载过程
ClassLoader概念
ClassLoader是用来动态的加载class文件到虚拟机中,并转换成java.lang.class类的一个实例,每个这样的实例用来表示一个java类,我们可以根据Class的实例得到该类的信息,并通过实例的newInstance()方法创建出该类的一个对象,除此之外,ClassLoader还负责加载Java应用所需的资源,如图像文件和配置文件等。
ClassLoader类是一个抽象类。如果给定类的二进制名称,那么类加载器会试图查找或生成构成类定义的数据。一般策略是将名称转换为某个文件名,然后从文件系统读取该名称的“类文件”。ClassLoader类使用委托模型来搜索类和资源。每个 ClassLoader实例都有一个相关的父类加载器。需要查找类或资源时,ClassLoader实例会在试图亲自查找类或资源之前,将搜索类或资源的任务委托给其父类加载器。
注意:程序在启动的时候,并不会一次性加载程序所要用的所有class文件,而是根据程序的需要,通过Java的类加载机制来动态加载某个class文件到内存中。
- 双亲委派模型
双亲委派模型Parents Delegation Model
双亲委派模型是通过Composition模式实

双亲委派模型的基本思路是,一个类加载器收到了类加载请求,自己不会加载,而是调用父类加载器去完成
JVM平台提供三层classLoader
Bootstrap classLoader:采用native code实现,是JVM的一部分,主要加载JVM自身工作需要的类,如java.lang.*、java.uti.*等; 这些类位于$JAVA_HOME/jre/lib/rt.jar。Bootstrap ClassLoader不继承自ClassLoader,因为它不是一个普通的Java类,底层由C++编写,已嵌入到了JVM内核当中,当JVM启动后,Bootstrap ClassLoader也随着启动,负责加载完核心类库后,并构造Extension ClassLoader和App ClassLoader类加载器。
ExtClassLoader:扩展的class loader,加载位于$JAVA_HOME/jre/lib/ext目录下的扩展jar。
AppClassLoader:系统class loader,父类是ExtClassLoader,加载$CLASSPATH下的目录和jar;它负责加载应用程序主函数类。
其体系结构图如下:

如果要实现自己的类加载器,不管是实现抽象列ClassLoader,还是继承URLClassLoader类,它的父加载器都是AppClassLoader,因为不管调用哪个父类加载器,创建的对象都必须最终调用getSystemClassLoader()作为父加载器,getSystemClassLoader()方法获取到的正是AppClassLoader。
注意:Bootstrap classLoader并不属于JVM的等级层次,它不遵守ClassLoader的加载规则,Bootstrap classLoader并没有子类。
JVM加载class文件到内存有两种方式
隐式加载:不通过在代码里调用ClassLoader来加载需要的类,而是通过JVM来自动加载需要的类到内存,例如:当类中继承或者引用某个类时,JVM在解析当前这个类不在内存中时,就会自动将这些类加载到内存中。
显示加载:在代码中通过ClassLoader类来加载一个类,例如调用this.getClass.getClassLoader().loadClass()或者Class.forName()。
ClassLoader加载类的过程
找到.class文件并把这个文件加载到内存中
字节码验证,Class类数据结构分析,内存分配和符号表的链接
类中静态属性和初始化赋值以及静态代码块的执行
实现类的热部署
1、什么是类的热部署?
所谓热部署,就是在应用正在运行的时候升级软件,不需要重新启用应用。
对于Java应用程序来说,热部署就是运行时更新Java类文件。在基于Java的应用服务器实现热部署的过程中,类装入器扮演着重要的角色。大多数基于Java的应用服务器,包括EJB服务器和Servlet容器,都支持热部署。
类装入器不能重新装入一个已经装入的类,但只要使用一个新的类装入器实例,就可以将类再次装入一个正在运行的应用程序。
2、如何实现Java类的热部署
前面的分析,我们已经知道,JVM在加载类之前会检查请求的类是否已经被加载过来,也就是要调用findLoadedClass方法查看是否能够返回类实例。如果类已经加载过来,再调用loadClass会导致类冲突。
但是,JVM判断一个类是否是同一个类有两个条件:一是看这个类的完整类名是否一样(包括包名),二是看加载这个类的ClassLoader加载器是否是同一个(既是是同一个ClassLoader类的两个实例,加载同一个类也会不一样)。
所以,要实现类的热部署可以创建不同的ClassLoader的实例对象,然后通过这个不同的实例对象来加载同名的类。
NIO
理解与使用
Netty的使用或许我们看着官网user guide还是很容易入门的。因为java nio使用非常的繁琐,netty对java nio进行了大量的封装。对于Netty的理解,我们首先需要了解NIO的原理和使用。所以,我也特别渴望去了解NIO这种通信模式。
官方的定义是:nio 是non-blocking的简称,在jdk1.4 里提供的新api 。Sun 官方标榜的特性如下: 为所有的原始类型提供(Buffer)缓存支持。字符集编码解码解决方案。 Channel :一个新的原始I/O 抽象。 支持锁和内存映射文件的文件访问接口。 提供多路(non-bloking) 非阻塞式的高伸缩性网络I/O 。是不是很抽象?
在阅读《NIO入门》这篇技术文档之后,收获了很多。包括对Java NIO的理解和使用,所以也特别的感谢作者。
首先,还是来回顾以下从这篇文档中学到的要点。
为什么要使用 NIO?
NIO 的创建目的是为了让 Java 程序员可以实现高速 I/O 而无需编写自定义的本机代码。NIO 将最耗时的 I/O 操作(即填充和提取缓冲区)转移回操作系统,因而可以极大地提高速度。
NIO最重要的组成部分
通道 Channels
缓冲区 Buffers
选择器 Selectors
Buffer 是一个对象, 它包含一些要写入或者刚读出的数据。
在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的。在写入数据时,它是写入到缓冲区中的。任何时候访问 NIO 中的数据,您都是将它放到缓冲区中。
缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不 仅仅 是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
Channel是一个对象,可以通过它读取和写入数据
例子:
看完下面这个例子,基本上就理解buffer和channel的作用了
package yyf.java.nio.ibm;
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
public class CopyFile {
static public void main(String args[]) throws Exception {
String infile = "c://test/nio_copy.txt";
String outfile = "c://test/result.txt";
FileInputStream fin = new FileInputStream(infile);
FileOutputStream fout = new FileOutputStream(outfile);
// 获取读的通道
FileChannel fcin = fin.getChannel();
// 获取写的通道
FileChannel fcout = fout.getChannel();
// 定义缓冲区,并指定大小
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (true) {
// 清空缓冲区
buffer.clear();
//从通道读取一个数据到缓冲区
int r = fcin.read(buffer);
//判断是否有从通道读到数据
if (r == -1) {
break;
}
//将buffer指针指向头部
buffer.flip();
//把缓冲区数据写入通道
fcout.write(buffer);
}
}
}
缓冲区主要是三个变量
position
limit
capacity
这三个变量一起可以跟踪缓冲区的状态和它所包含的数据。我们将在下面的小节中详细分析每一个变量,还要介绍它们如何适应典型的读/写(输入/输出)进程。在这个例子中,我们假定要将数据从一个输入通道拷贝到一个输出通道。
Position
您可以回想一下,缓冲区实际上就是美化了的数组。在从通道读取时,您将所读取的数据放到底层的数组中。 position 变量跟踪已经写了多少数据。更准确地说,它指定了下一个字节将放到数组的哪一个元素中。因此,如果您从通道中读三个字节到缓冲区中,那么缓冲区的 position 将会设置为3,指向数组中第四个元素。
同样,在写入通道时,您是从缓冲区中获取数据。 position 值跟踪从缓冲区中获取了多少数据。更准确地说,它指定下一个字节来自数组的哪一个元素。因此如果从缓冲区写了5个字节到通道中,那么缓冲区的 position 将被设置为5,指向数组的第六个元素。
Limit
limit 变量表明还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
position 总是小于或者等于 limit。
Capacity
缓冲区的 capacity 表明可以储存在缓冲区中的最大数据容量。实际上,它指定了底层数组的大小 ― 或者至少是指定了准许我们使用的底层数组的容量。
limit 决不能大于 capacity。
缓冲区作为一个数组,这三个变量就是其中数据的标记,也很好理解。
Selector(选择器)是Java NIO中能够检测一到多个NIO通道,并能够知晓通道是否为诸如读写事件做好准备的组件。这样,一个单独的线程可以管理多个channel,从而管理多个网络连接。
接下来来看看具体的使用把,我创建了一个直接收消息的服务器(一边接收一边写数据可能对于新手不好理解)
服务端:
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
public class NioReceiver {
@SuppressWarnings("null")
public static void main(String[] args) throws Exception {
ByteBuffer echoBuffer = ByteBuffer.allocate(8);
ServerSocketChannel ssc = ServerSocketChannel.open();
Selector selector = Selector.open();
ssc.configureBlocking(false);
ServerSocket ss = ssc.socket();
InetSocketAddress address = new InetSocketAddress(8080);
ss.bind(address);
SelectionKey key = ssc.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("开始监听……");
while (true) {
int num = selector.select();
Set selectedKeys = selector.selectedKeys();
Iterator it = selectedKeys.iterator();
while (it.hasNext()) {
SelectionKey sKey = (SelectionKey) it.next();
SocketChannel channel = null;
if (sKey.isAcceptable()) {
ServerSocketChannel sc = (ServerSocketChannel) key.channel();
channel = sc.accept();// 接受连接请求
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_READ);
it.remove();
} else if (sKey.isReadable()) {
channel = (SocketChannel) sKey.channel();
while (true) {
echoBuffer.clear();
int r = channel.read(echoBuffer);
if (r <= 0) {
channel.close();
System.out.println("接收完毕,断开连接");
break;
}
System.out.println("##" + r + " " + new String(echoBuffer.array(), 0, echoBuffer.position()));
echoBuffer.flip();
}
it.remove();
} else {
channel.close();
}
}
}
}
}
客户端(NIO):
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
public class NioTest {
public static void main(String[] args) throws Exception {
ByteBuffer echoBuffer = ByteBuffer.allocate(1024);
SocketChannel channel = null;
Selector selector = null;
channel = SocketChannel.open();
channel.configureBlocking(false);
// 请求连接
channel.connect(new InetSocketAddress("localhost", 8080));
selector = Selector.open();
channel.register(selector, SelectionKey.OP_CONNECT);
int num = selector.select();
Set selectedKeys = selector.selectedKeys();
Iterator it = selectedKeys.iterator();
while (it.hasNext()) {
SelectionKey key = (SelectionKey) it.next();
it.remove();
if (key.isConnectable()) {
if (channel.isConnectionPending()) {
if (channel.finishConnect()) {
// 只有当连接成功后才能注册OP_READ事件
key.interestOps(SelectionKey.OP_READ);
echoBuffer.put("123456789abcdefghijklmnopq".getBytes());
echoBuffer.flip();
System.out.println("##" + new String(echoBuffer.array()));
channel.write(echoBuffer);
System.out.println("写入完毕");
} else {
key.cancel();
}
}
}
}
}
}
运行结果:
开始监听……
##8 12345678
##8 9abcdefg
##8 hijklmno
##2 pq
接收完毕,断开连接
当然,BIO的客户端也可以,开启10个BIO客户端线程
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.InetAddress;
import java.net.InetSocketAddress;
import java.net.Socket;
import java.net.UnknownHostException;
import java.util.Random;
public class BioClientTest {
public static void main(String[] args) throws Exception {
BioClient n = new BioClient();
for (int i = 0; i < 10; i++) {
Thread t1 = new Thread(n);
t1.start();
}
}
}
class BioClient implements Runnable {
@Override
public void run() {
try {
Socket socket = new Socket("127.0.0.1", 8080);
OutputStream os = socket.getOutputStream();
InputStream is = socket.getInputStream();
ByteArrayOutputStream bos = new ByteArrayOutputStream();
String str = Thread.currentThread().getName() + "...........sadsadasJava";
os.write(str.getBytes());
StringBuffer sb = new StringBuffer();
byte[] b = new byte[1024];
int len;
while ((len = is.read(b)) != -1) {
bos.write(b, 0, len);
}
is.close();
os.close();
socket.close();
System.out.println(Thread.currentThread().getName() + " 写入完毕 " + new String(bos.toByteArray()));
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
##8 Thread-4
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-3
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-9
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-7
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-0
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-5
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-2
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-8
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-1
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
##8 Thread-6
##8 …
##8 …sadsa
##7 dasJava
接收完毕,断开连接
当然,这只是一个测试,对于一个服务器,是有读取,也有写出的,这是文档给的一个服务端例子
import java.io.*;
import java.net.*;
import java.nio.*;
import java.nio.channels.*;
import java.util.*;
public class MultiPortEcho {
private int ports[];
private ByteBuffer echoBuffer = ByteBuffer.allocate(5);
public MultiPortEcho(int ports[]) throws IOException {
this.ports = ports;
go();
}
private void go() throws IOException {
Selector selector = Selector.open();
for (int i = 0; i < ports.length; ++i) {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ServerSocket ss = ssc.socket();
InetSocketAddress address = new InetSocketAddress(ports[i]);
ss.bind(address);
SelectionKey key = ssc.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("Going to listen on " + ports[i]);
}
while (true) {
int num = selector.select();
Set selectedKeys = selector.selectedKeys();
Iterator it = selectedKeys.iterator();
while (it.hasNext()) {
SelectionKey key = (SelectionKey) it.next();
if ((key.readyOps() & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT) {
ServerSocketChannel ssc = (ServerSocketChannel) key.channel();
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
SelectionKey newKey = sc.register(selector, SelectionKey.OP_READ);
it.remove();
System.out.println("Got connection from " + sc);
} else if ((key.readyOps() & SelectionKey.OP_READ) == SelectionKey.OP_READ) {
SocketChannel sc = (SocketChannel) key.channel();
int bytesEchoed = 0;
while (true) {
echoBuffer.clear();
int r = sc.read(echoBuffer);
if (r <= 0) {
sc.close();
break;
}
echoBuffer.flip();
sc.write(echoBuffer);
bytesEchoed += r;
}
System.out.println("Echoed " + bytesEchoed + " from " + sc);
it.remove();
}
}
// System.out.println( "going to clear" );
// selectedKeys.clear();
// System.out.println( "cleared" );
}
}
static public void main(String args[]) throws Exception {
int ports[] = new int[] { 8080 };
for (int i = 0; i < args.length; ++i) {
ports[i] = Integer.parseInt(args[i]);
}
new MultiPortEcho(ports);
}
}
现在,我们就写个客户端去跟服务器通信,把发过去的返回来:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import javax.swing.ButtonGroup;
public class NioClient {
public static void main(String[] args) throws IOException {
SocketChannel socketChannel = SocketChannel.open();
SocketAddress socketAddress = new InetSocketAddress("127.0.0.1", 8080);
socketChannel.connect(socketAddress);
String str = "你好a";
ByteBuffer buffer = ByteBuffer.wrap(str.getBytes());
socketChannel.write(buffer);
socketChannel.socket().shutdownOutput();
buffer.clear();
byte[] bytes;
int count = 0;
while ((count = socketChannel.read(buffer)) > 0) {
buffer.flip();
bytes = new byte[count];
buffer.get(bytes);
System.out.println(new String(buffer.array()));
buffer.clear();
}
socketChannel.socket().shutdownInput();
socketChannel.socket().close();
socketChannel.close();
}
}
运行结果
server:
Going to listen on 8080
Got connection from java.nio.channels.SocketChannel[connected local=/127.0.0.1:8080 remote=/127.0.0.1:63584]
Echoed 7 from java.nio.channels.SocketChannel[closed]
client:
你好a
深入理解NIO
-
初识NIO:
在 JDK 1. 4 中新加入了 NIO( New Input/ Output)类,引入了一种基于通道和缓冲区的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆的 DirectByteBuffer 对象作为这块内存的引用进行操作,避免了在 Java 堆和 Native 堆中来回复制数据。
NIO 是一种同步非阻塞的 IO 模型。同步是指线程不断轮询 IO 事件是否就绪,非阻塞是指线程在等待 IO 的时候,可以同时做其他任务。同步的核心就是 Selector,Selector 代替了线程本身轮询 IO 事件,避免了阻塞同时减少了不必要的线程消耗;非阻塞的核心就是通道和缓冲区,当 IO 事件就绪时,可以通过写道缓冲区,保证 IO 的成功,而无需线程阻塞式地等待。 -
Buffer:
为什么说NIO是基于缓冲区的IO方式呢?因为,当一个链接建立完成后,IO的数据未必会马上到达,为了当数据到达时能够正确完成IO操作,在BIO(阻塞IO)中,等待IO的线程必须被阻塞,以全天候地执行IO操作。为了解决这种IO方式低效的问题,引入了缓冲区的概念,当数据到达时,可以预先被写入缓冲区,再由缓冲区交给线程,因此线程无需阻塞地等待IO。 -
通道:
当执行:SocketChannel.write(Buffer),便将一个 buffer 写到了一个通道中。如果说缓冲区还好理解,通道相对来说就更加抽象。网上博客难免有写不严谨的地方,容易使初学者感到难以理解。
引用 Java NIO 中权威的说法:通道是 I/O 传输发生时通过的入口,而缓冲区是这些数据传输的来源或目标。对于离开缓冲区的传输,您想传递出去的数据被置于一个缓冲区,被传送到通道。对于传回缓冲区的传输,一个通道将数据放置在您所提供的缓冲区中。
例如有一个服务器通道 ServerSocketChannel serverChannel,一个客户端通道 SocketChannel clientChannel;服务器缓冲区:serverBuffer,客户端缓冲区:clientBuffer。
当服务器想向客户端发送数据时,需要调用:clientChannel.write(serverBuffer)。当客户端要读时,调用 clientChannel.read(clientBuffer)
当客户端想向服务器发送数据时,需要调用:serverChannel.write(clientBuffer)。当服务器要读时,调用 serverChannel.read(serverBuffer)
这样,通道和缓冲区的关系似乎更好理解了。在实践中,未必会出现这种双向连接的蠢事(然而这确实存在的,后面的内容还会涉及),但是可以理解为在NIO中:如果想将Data发到目标端,则需要将存储该Data的Buffer,写入到目标端的Channel中,然后再从Channel中读取数据到目标端的Buffer中。 -
Selector:
通道和缓冲区的机制,使得线程无需阻塞地等待IO事件的就绪,但是总是要有人来监管这些IO事件。这个工作就交给了selector来完成,这就是所谓的同步。
Selector允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。
要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪,这就是所说的轮询。一旦这个方法返回,线程就可以处理这些事件。
Selector中注册的感兴趣事件有:
-
优化:
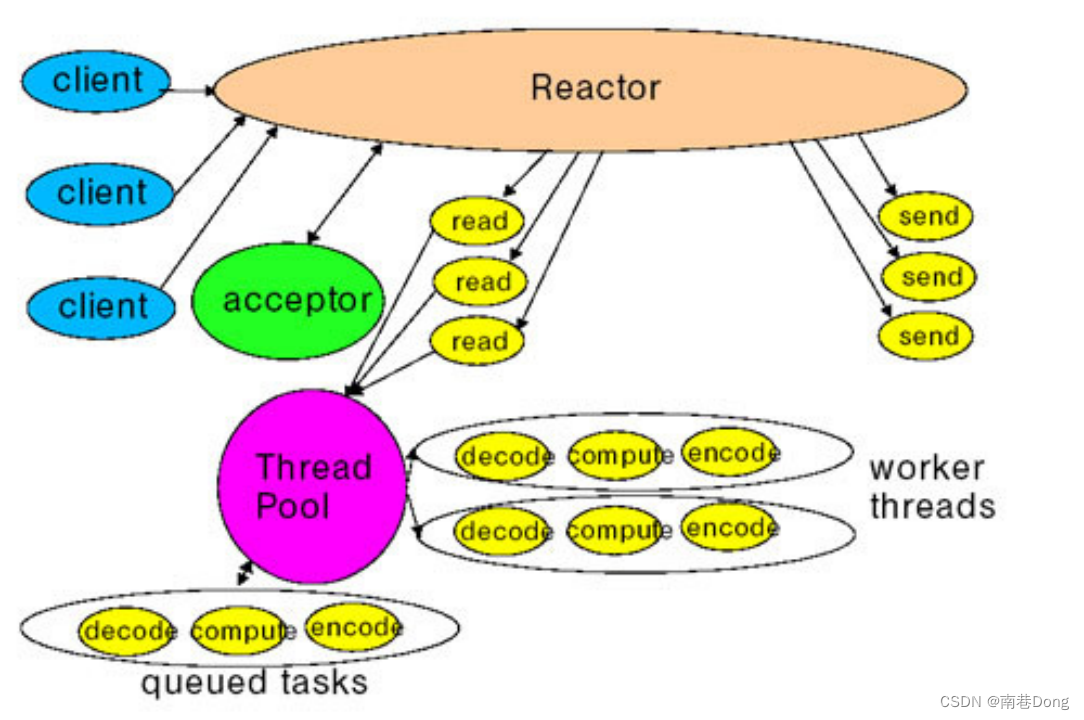
一种优化方式是:将Selector进一步分解为Reactor,将不同的感兴趣事件分开,每一个Reactor只负责一种感兴趣的事件。这样做的好处是:1、分离阻塞级别,减少了轮询的时间;2、线程无需遍历set以找到自己感兴趣的事件,因为得到的set中仅包含自己感兴趣的事件。 -
NIO和epoll:
epoll是Linux内核的IO模型。我想一定有人想问,AIO听起来比NIO更加高大上,为什么不使用AIO?AIO其实也有应用,但是有一个问题就是,Linux是不支持AIO的,因此基于AIO的程序运行在Linux上的效率相比NIO反而更低。而Linux是最主要的服务器OS,因此相比AIO,目前NIO的应用更加广泛。
说到这里,可能你已经明白了,epoll一定和NIO有着很深的因缘。没错,如果仔细研究epoll的技术内幕,你会发现它确实和NIO非常相似,都是基于“通道”和缓冲区的,也有selector,只是在epoll中,通道实际上是操作系统的“管道”。和NIO不同的是,NIO中,解放了线程,但是需要由selector阻塞式地轮询IO事件的就绪;而epoll中,IO事件就绪后,会自动发送消息,通知selector:“我已经就绪了。”可以认为,Linux的epoll是一种效率更高的NIO。 -
NIO轶事:
一篇有意思的博客,讲的 Java selector.open()的时候,会创建一个自己和自己的链接(windows上是tcp,linux上是通道)
这么做的原因:可以从 Apache Mina 中窥探。在 Mina 中,有如下机制:
Mina框架会创建一个Work对象的线程。
Work对象的线程的run()方法会从一个队列中拿出一堆Channel,然后使用Selector.select()方法来侦听是否有数据可以读/写。
最关键的是,在select的时候,如果队列有新的Channel加入,那么,Selector.select()会被唤醒,然后重新select最新的Channel集合。
要唤醒select方法,只需要调用Selector的wakeup()方法。
而一个阻塞在select上的线程有以下三种方式可以被唤醒:
有数据可读/写,或出现异常。
阻塞时间到,即time out。
收到一个non-block的信号。可由kill或pthread_kill发出。
首先 2 可以排除,而第三种方式,只在linux中存在。因此,Java NIO为什么要创建一个自己和自己的链接:就是如果想要唤醒select,只需要朝着自己的这个loopback连接发点数据过去,于是,就可以唤醒阻塞在select上的线程了。
外传
😜 原创不易,如若本文能够帮助到您的同学
🎉 支持我:关注我+点赞👍+收藏⭐️
📝 留言:探讨问题,看到立马回复
💬 格言:己所不欲勿施于人 扬帆起航、游历人生、永不言弃!🔥