如果仅仅从服务器的角度来看,这两个方法其实本质是一样的,以下内容是摘抄自oracle的官网:
Defines an object to assist a servlet in sending a response to the client. The servlet container creates a ServletResponse object and passes it as an argument to the servlet's service method.
To send binary data in a MIME body response, use the ServletOutputStream returned by getOutputStream(). To send character data, use the PrintWriter object returned by getWriter(). To mix binary and text data, for example, to create a multipart response, use a ServletOutputStream and manage the character sections manually.The charset for the MIME body response can be specified explicitly using the setCharacterEncoding(java.lang.String) and setContentType(java.lang.String) methods, or implicitly using the setLocale(java.util.Locale) method. Explicit specifications take precedence over implicit specifications. If no charset is specified, ISO-8859-1 will be used. The setCharacterEncoding, setContentType, or setLocale method must be called before getWriter and before committing the response for the character encoding to be used.
从服务器端角度看,两个方法就是给服务器返回前端的内容进行编码设置。
但是,再次强调,内容是要在平台上展示的,而平台也是有自己的charset的。如果平台用来展示内容的charset与内容不符合时,出现的依然是乱码。
看例子:
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setCharacterEncoding("utf-8");
ServletOutputStream stream = response.getOutputStream();
stream.write("<h1>AC米兰足球队</h1>".getBytes("utf-8"));
stream.close();
}那根据前面的解释,这段代码就是从服务器发给客户端一个响应,响应的内容是用UTF8编码的字符串<h1>AC米兰足球队</h1>。
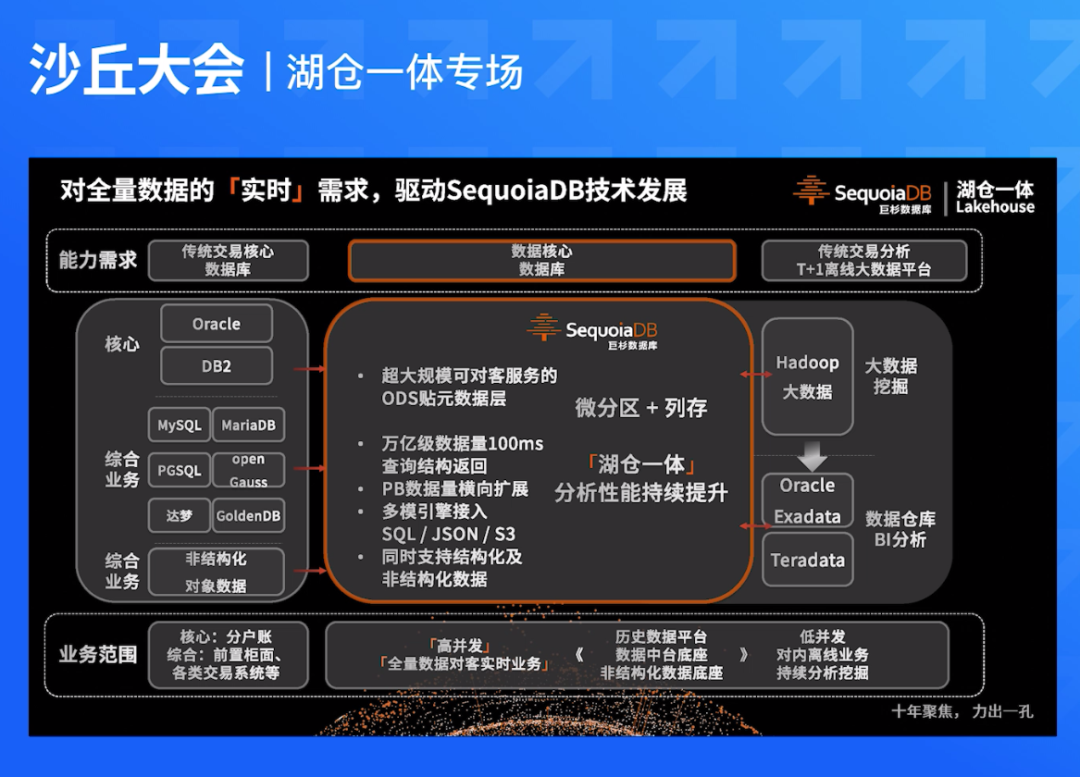
代码运行,通过chrome浏览器发起请求,访问/test得到的页面是:

用F12打开开发者工具,分别看一下网络的响应和预览:
首先是响应中看到的内容:
然后是预览中看到的内容:

发现不同之处了吗?那么背后的原因呢?
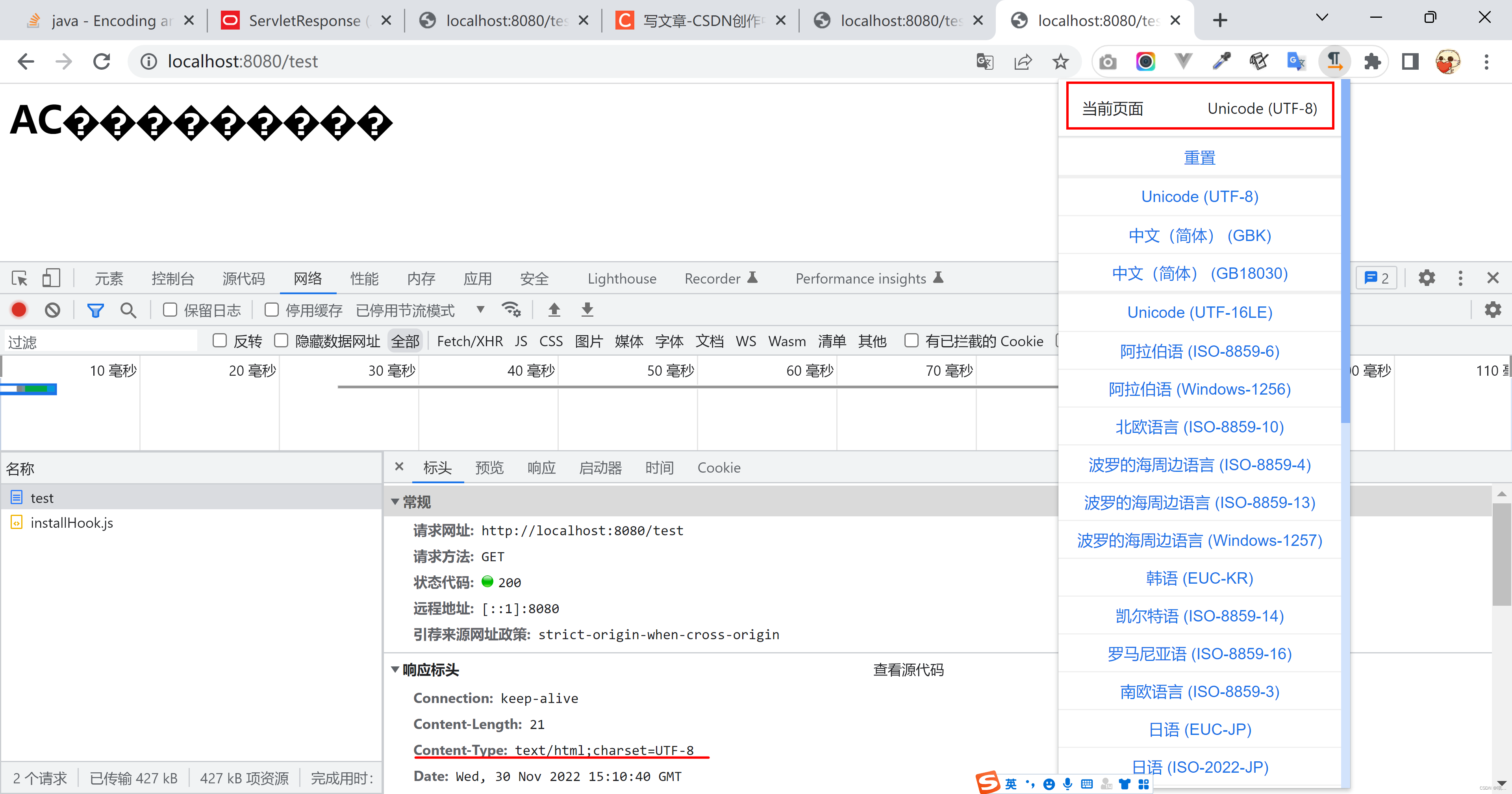
说明浏览器收到了正经UTF8编码的内容,但是浏览器并没有得到任何提示或者要求用什么编码方式来呈现这段内容!所以浏览器使用的是默认编码方式。那么Windows系统下的中文Chrome默认的编码方式是什么?猜也猜到了:GBK。
通过Chrome的Charset插件,就可以证明这一点:

好了,那我们如何告知浏览器用什么编码集来呈现内容呢?只要在响应头中加入contentType,浏览器会遵照contentType的指示来使用编辑呈现内容。如何在响应头中加入contentType,当然就是使用setContentType喽。
修改上面Servlet的doGet方法:
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//response.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");
ServletOutputStream stream = response.getOutputStream();
stream.write("<h1>AC米兰足球队</h1>".getBytes("utf-8"));
stream.close();
}这回使用了setContentType,用标准的MIME格式设置了服务器响应内容的字符集是UTF8,并且添加了响应头,告诉浏览器该使用什么编码集来显示内容:

这一次浏览器遵守contentType的指示,知道了收到的内容格式是text/html,要使用utf8字符集进行显示。
---------------------------------------------------------------------------------------------------------------------------------
所以,对于服务端来说,setCharacterEncoding和setContentType这两个方法的作用是一样的,都是显示的为服务器响应内容指定一个编码方案。
但是对于浏览器来说,setContentType是会添加响应头的,会指导浏览器用正确的字符集来显示服务器的响应内容,而setCharacterEncoding做不到这一点。
不过,现在你知道了Chrome的默认字符集是GBK,所以你完全可以用setCharacterEncoding("GBK")用GBK作为服务器响应内容的编码方案,这样也可以正常显示中文:
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setCharacterEncoding("GBK");
//response.setContentType("text/html;charset=utf-8");
ServletOutputStream stream = response.getOutputStream();
stream.write("<h1>AC米兰足球队</h1>".getBytes("GBK"));
stream.close();
} 
相较于setContentType来说,这种设置方式就是“巧了”,浏览器的默认编码方案碰巧是服务器响应内容的编码方案。
---------------------------------------------------------------------------------------------------------------------------------
还有一种代码编写风格是同时使用setContentType和setCharacterEncoding方法。同时使用者两种方法的效果是:setCharacterEncoding会补充或覆盖setContentType的内容。
1.补充:
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setCharacterEncoding("gb2312");
response.setContentType("text/html");
ServletOutputStream stream = response.getOutputStream();
stream.write("<h1>AC米兰足球队</h1>".getBytes("gb2312"));
stream.close();
}setContentType提供的MIME只有类型没有编码方案,此时setCharacterEncoding的内容就称为了contentType中charset的内容。所以,浏览器收到的内容是有一个形如text/html;charset=gb2312这样的contentType响应头的。

按照ContentType的指示,浏览器正确显示了服务器响应内容。
2.覆盖:
如果setContentType和setCharacterEncoding都设置了完整内容,那么setCharacterEncoding提供的编码方案将作为服务器内容的编码方案,但是浏览器会在收到响应内容的同时会收到由setContentType设置的请求头:
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setCharacterEncoding("gb2312");
response.setContentType("text/html;charset=UTF-8");
ServletOutputStream stream = response.getOutputStream();
stream.write("<h1>AC米兰足球队</h1>".getBytes("gb2312"));
stream.close();
}gb2312编码的内容,浏览器会使用请求头指示的UTF-8来显示,结果可想而知:
--------------------------------------------------------------------------------------------------------------------------------
以上就是对setContentType和setCharacterEncoding方法的使用说明。显然,我个人更倾向于使用setContentType,同时兼顾了服务端内容编码和浏览器端解码的问题。



![[附源码]JAVA毕业设计高校信息资源共享平台(系统+LW)](https://img-blog.csdnimg.cn/9037328c9e97432c81e879dd73d764b7.png)
![[附源码]Python计算机毕业设计Django高校学生宿舍管理系统](https://img-blog.csdnimg.cn/472c66f6210b430f861de0bf6b58bb83.png)


![[附源码]JAVA毕业设计-高中辅助教学系统-(系统+LW)](https://img-blog.csdnimg.cn/357aeed419f44f4b82182fc63c14c2b0.png)
![[附源码]Python计算机毕业设计Django电商小程序](https://img-blog.csdnimg.cn/7b33af2b994d4196938bf1f0e9188993.png)