下文部分代码省略,完整项目代码及数据集链接:抖音用户浏览行为数据分析与挖掘
目录
- 1.特征指标构建
- 0. 项目介绍与说明
- **数据集说明**
- 浏览行为
- 1. 数据简单处理
- 2. 特征指标构建
- 用户指标分析:
- 作者指标分析:
- 作品指标分析:
- 3. 特征指标统计分析
- 3.1 用户特征统计分析
- 3.2 作者特征统计分析
- 3.3 作品特征统计分析
- 4. 总结
- 2.数据可视化分析
- 0. 绘图函数封装
- 1. 用户特征分析
- 1.0 特征数据统计
- 1.1 用户浏览情况
- 1.2 用户点赞情况
- 1.3 用户完整观看情况
- 1.4 用户观看作品的平均完整时长分布
- 1.5 用户去过的城市数分布
- 2 作者特征分析
- 2.0 数据指标统计
- 2.1 作者浏览情况
- 2.2 作者点赞情况
- 2.3 作者去过的城市数
- 3. 作品特征分析
- 3.0 数据读取
- 3.1 作品各日发布情况
- 3.2 作品浏览量情况
- 3.3 作品点量率情况
- 3. 数据挖掘探索
- 3.1 聚类分析
- 1. 数据读取与数据处理
- 1.1 数据读取
- 1.2 数据处理
- 2. 聚类方法与定义
- 2.1 聚类方法
- 2.2 相关函数定义
- 3. 用户特征聚类
- 3.1 模型训练与保存
- 3.2 聚类k值选择
- 3.3 聚类结果
- 4. 作者特征聚类
- 4.1 模型训练与保存
- 4.2 聚类k值选择
- 4.3 聚类效果
- 总结
- 3.2 二分类预测
- 1. 数据读取与处理
- 1.1 数据读取
- 1.2 数据抽样处理
- 1.3 时间数据处理
- 1.4 数据集划分
- 2. 模型预训练
- 2.1 模型训练函数
- 2.2 模型训练
- 2.3 模型AUC曲线
- 3. 模型优化
- 3.1 n_e优化
- 3.2 max_f优化
- 3.3 模型训练
- 4. 模型预测
- 4.1 模型准确率
- 4.2 一些说明
1.特征指标构建
0. 项目介绍与说明
数据集说明
| 字段名 | 释义 | 字段名 | 释义 | 字段名 | 释义 |
|---|---|---|---|---|---|
| uid | 用户id | user_city | 用户城市 | item_id | 作品id |
| author_id | 作者id | item_city | 作者城市 | channel | 作品频道 |
| finish | 是否看完 | like | 是否点赞 | music_id | 音乐id |
| duration_time | 作品时长 | real_time | 具体发布时间 | H、date | 时、天(发布) |
浏览行为
每一条数据都是由用户主动发起的,与创作者视频进行交互的行为记录,包括
- 什么人(用户)
- 看了谁的(作者)
- 什么视频(作品、发布时间、音乐、时长)
- 什么渠道
- 是否看完
- 是否点赞
- 音乐和时间等
我们可以将浏览行为的数据简单的分类为:
- 用户信息: u i d , u s e r _ c i t y uid,user\_city uid,user_city
- 作品信息: i t e m _ i d , i t e m _ c i t y , c h a n n e l , m u s i c i d , d u r a t i o n _ t i m e , r e a l _ t i m e , H 、 d a t e item\_id, item\_city, channel, music_id, duration\_time, real\_time, H、date item_id,item_city,channel,musicid,duration_time,real_time,H、date
- 作者信息: a u t h o r i d author_id authorid
- 浏览行为描述: f i n i s h , l i k e finish, like finish,like
同时可以从浏览行为中抽象出:用户、作品、作者、音乐、城市等实体,在本项目中,我们仅对用户、作者和作品角度进行简单分析,并加入一些数据分析方法
import pandas as pd
import numpy as np
1. 数据简单处理
df = pd.read_csv('/home/mw/input/somnus8660/douyin_dataset.csv')
df.head()
| Unnamed: 0 | uid | user_city | item_id | author_id | item_city | channel | finish | like | music_id | duration_time | real_time | H | date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 15692 | 109.0 | 691661 | 18212 | 213.0 | 0 | 0 | 0 | 11513.0 | 10 | 2019-10-28 21:55:10 | 21 | 2019-10-28 |
| 1 | 5 | 44071 | 80.0 | 1243212 | 34500 | 68.0 | 0 | 0 | 0 | 1274.0 | 9 | 2019-10-21 22:27:03 | 22 | 2019-10-21 |
| 2 | 16 | 10902 | 202.0 | 3845855 | 634066 | 113.0 | 0 | 0 | 0 | 762.0 | 10 | 2019-10-26 00:38:51 | 0 | 2019-10-26 |
| 3 | 19 | 25300 | 21.0 | 3929579 | 214923 | 330.0 | 0 | 0 | 0 | 2332.0 | 15 | 2019-10-25 20:36:25 | 20 | 2019-10-25 |
| 4 | 24 | 3656 | 138.0 | 2572269 | 182680 | 80.0 | 0 | 0 | 0 | 238.0 | 9 | 2019-10-21 20:46:29 | 20 | 2019-10-21 |
无效字段的删除[Unnamed:0]
del df['Unnamed: 0']
# 数据基本信息基本信息
df.info(null_counts = True)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1737312 entries, 0 to 1737311
Data columns (total 13 columns):
uid 1737312 non-null int64
user_city 1737312 non-null float64
item_id 1737312 non-null int64
author_id 1737312 non-null int64
item_city 1737312 non-null float64
channel 1737312 non-null int64
finish 1737312 non-null int64
like 1737312 non-null int64
music_id 1737312 non-null float64
duration_time 1737312 non-null int64
real_time 1737312 non-null object
H 1737312 non-null int64
date 1737312 non-null object
dtypes: float64(3), int64(8), object(2)
memory usage: 172.3+ MB
数据无空缺
2. 特征指标构建
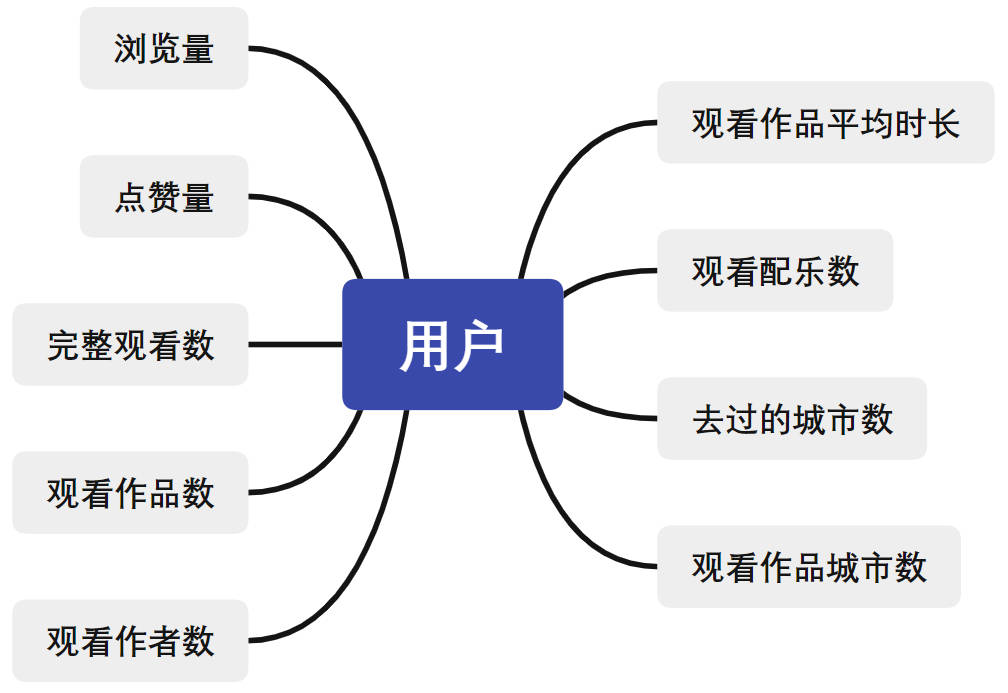
用户指标分析:
站在用户的角度,涉及到浏览量,点赞量,浏览的作品、作者、BGM的总数等,拟定统计指标如下:
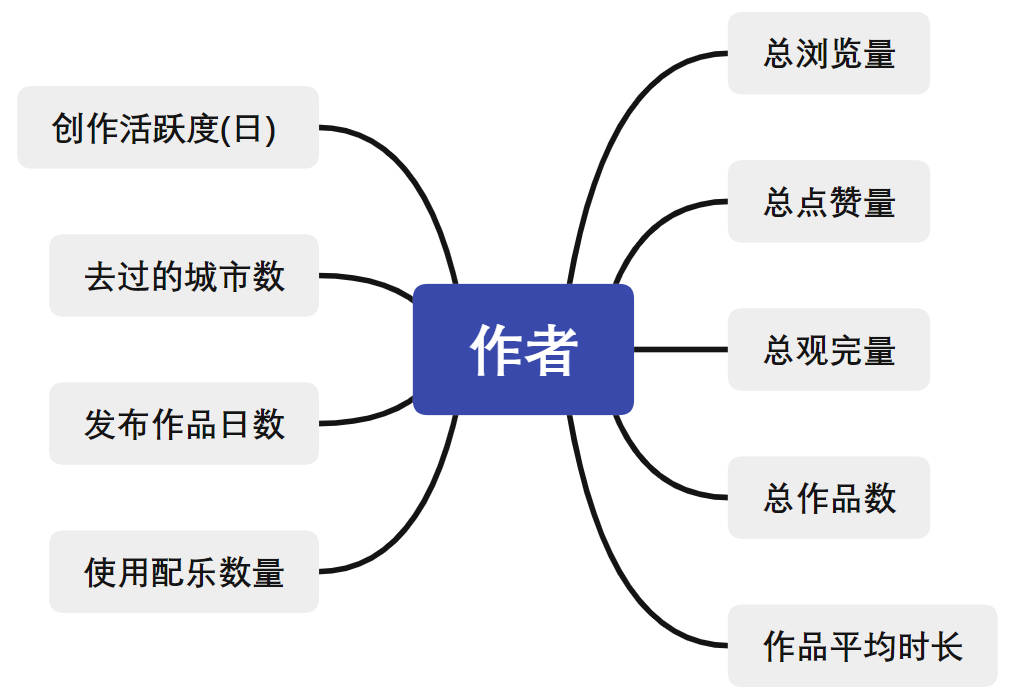
作者指标分析:
站在作者的角度,涉及到总浏览量,总点赞量等,拟定指标如下:
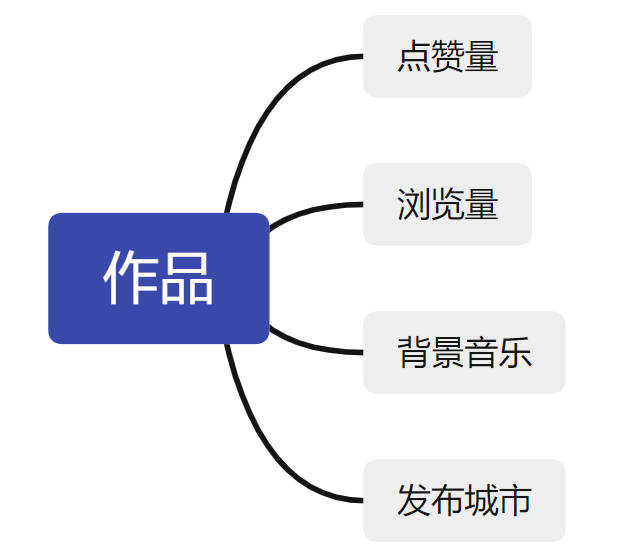
作品指标分析:
站在作品的角度,简单分析,拟定统计指标如下:
3. 特征指标统计分析
3.1 用户特征统计分析
user_df = pd.DataFrame()
user_df['uid'] = df.groupby('uid')['like'].count().index.tolist() # 将所有用户的uid提取为uid列
user_df.set_index('uid', inplace=True) # 设置uid列为index,方便后续数据自动对齐
user_df['浏览量'] = df.groupby('uid')['like'].count() # 统计对应uid下的浏览量
user_df['点赞量'] = df.groupby('uid')['like'].sum() # 统计对应uid下的点赞量
user_df['观看作者数'] = df.groupby(['uid']).agg({'author_id':pd.Series.nunique}) # 观看作者数
user_df['观看作品数'] = df.groupby(['uid']).agg({'item_id':pd.Series.nunique}) # 观看作品数
user_df['观看作品平均时长'] = df.groupby(['uid'])['duration_time'].mean() # 浏览作品平均时长
user_df['观看配乐数'] = df.groupby(['uid']).agg({'music_id':pd.Series.nunique}) # 观看作品中配乐的数量
user_df['完整观看数'] = df.groupby('uid')['finish'].sum() # 统计对应uid下的完整观看数
# 统计对应uid用户去过的城市数量
user_df['去过的城市数'] = df.groupby(['uid']).agg({'user_city':pd.Series.nunique})
# 统计对应uid用户看的作品所在的城市数量
user_df['观看作品城市数'] = df.groupby(['uid']).agg({'item_city':pd.Series.nunique})
user_df.describe()
user_df.to_csv('用户特征.csv', encoding='utf_8_sig')
3.2 作者特征统计分析
author_df = pd.DataFrame()
author_df['author_id'] = df.groupby('author_id')['like'].count().index.tolist()
author_df.set_index('author_id', inplace=True)
author_df['总浏览量'] = df.groupby('author_id')['like'].count()
author_df['总点赞量'] = df.groupby('author_id')['like'].sum()
author_df['总观完量'] = df.groupby('author_id')['finish'].sum()
author_df['总作品数'] = df.groupby('author_id').agg({'item_id':pd.Series.nunique})
item_time = df.groupby(['author_id', 'item_id']).mean().reset_index()
author_df['作品平均时长'] = item_time.groupby('author_id')['duration_time'].mean()
author_df['使用配乐数量'] = df.groupby('author_id').agg({'music_id':pd.Series.nunique})
author_df['发布作品日数'] = df.groupby('author_id').agg({'real_time':pd.Series.nunique})
# pd.to_datetime(df['date'].max()) - pd.to_datetime(df['date'].min()) # 作品时间跨度为40,共计40天
author_days = df.groupby('author_id')['date']
_ = pd.to_datetime(author_days.max()) - pd.to_datetime(author_days.min())
author_df['创作活跃度(日)'] = _.astype('timedelta64[D]').astype(int) + 1
author_df['去过的城市数'] = df.groupby(['author_id']).agg({'item_city':pd.Series.nunique})
author_df.describe()
author_df.to_csv('作者特征.csv', encoding='utf_8_sig')
3.3 作品特征统计分析
item_df = pd.DataFrame()
item_df['item_id'] = df.groupby('item_id')['like'].count().index.tolist()
item_df.set_index('item_id', inplace=True)
item_df['浏览量'] = df.groupby('item_id')['like'].count()
item_df['点赞量'] = df.groupby('item_id')['like'].sum()
item_df['发布城市'] = df.groupby('item_id')['item_city'].mean()
item_df['背景音乐'] = df.groupby('item_id')['music_id'].mean()
item_df.to_csv('作品特征.csv', encoding='utf_8_sig')
4. 总结
通过对浏览行为数据的认识和分析,构建并提取了用户、作者、作品的特征,特征的构造和提取并不唯一,如可以统计用户点赞率、作者的观众数等等
2.数据可视化分析
0. 绘图函数封装
1. 用户特征分析
1.0 特征数据统计
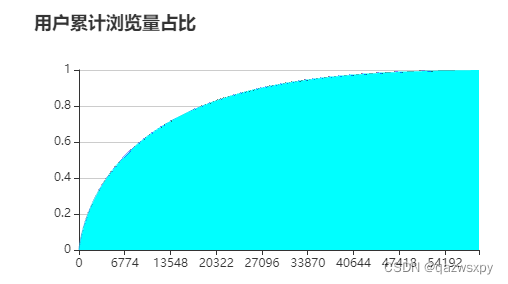
1.1 用户浏览情况

绘制类似二八分布的浏览量分布曲线:
- 按照浏览量从大到小将用户排序
- 依次计算前n个用户的浏览量之和占所有用户浏览量的比例
- 将人数n和前n人浏览量之和占总体比例绘制为图像
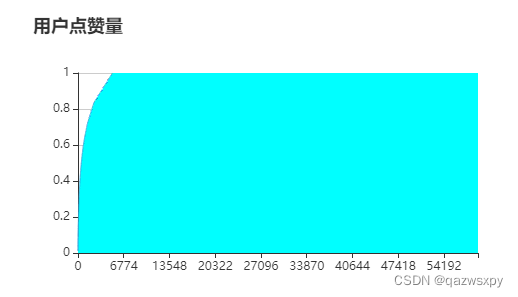
1.2 用户点赞情况
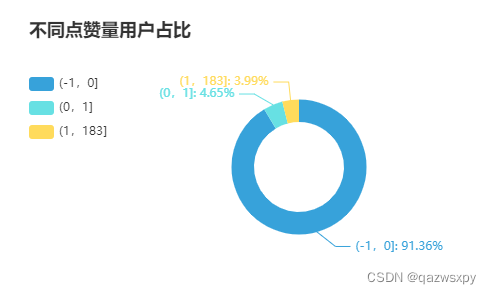
按照点赞量从大到小排序并求和,绘制类似二八分布的曲线
0.0% 的用户点了 0% 的赞
0.0% 的用户点了10% 的赞
0.1% 的用户点了20% 的赞
0.3% 的用户点了30% 的赞
0.5% 的用户点了40% 的赞
0.8% 的用户点了50% 的赞
1.3% 的用户点了60% 的赞
2.2% 的用户点了70% 的赞
3.5% 的用户点了80% 的赞
5.8% 的用户点了90% 的赞
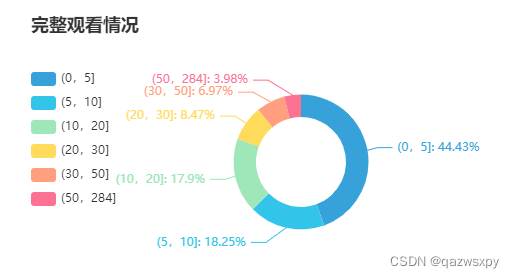
1.3 用户完整观看情况
1.4 用户观看作品的平均完整时长分布
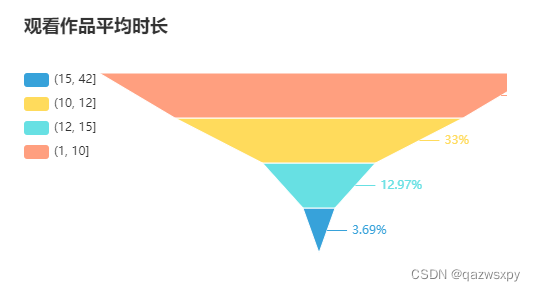
1.5 用户去过的城市数分布
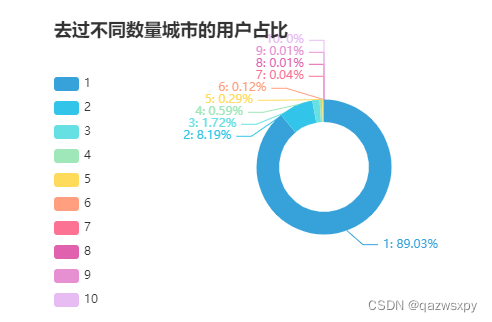
2 作者特征分析
2.0 数据指标统计
2.1 作者浏览情况
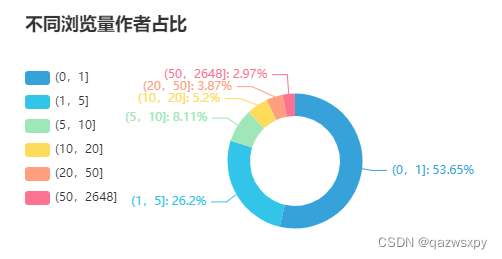
同样绘制浏览量的二八分布曲线(原理参考用户特征分析相同位置),受到一些奇怪条件,只加载头部(累计达到90%浏览量的用户数)
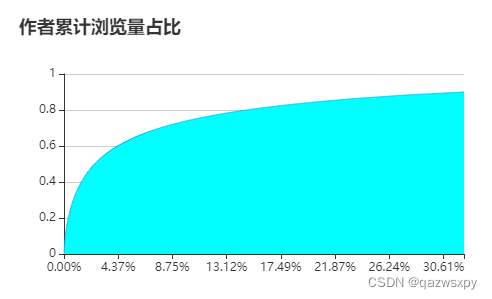
2.2 作者点赞情况
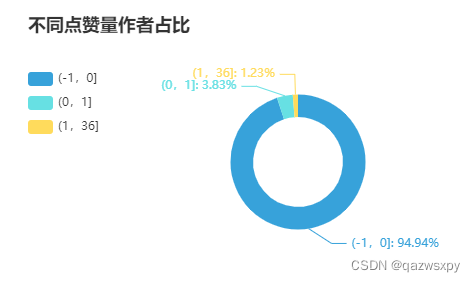
同样绘制浏览量的二八分布曲线(原理参考用户特征分析相同位置),受到一些奇怪条件,只加载头部(累计达到99%总点赞量的用户数)
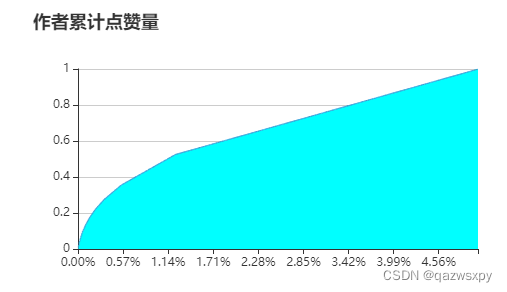
0.0% 的作者获得了 0% 的赞
0.1% 的作者获得了10% 的赞
0.2% 的作者获得了20% 的赞
0.4% 的作者获得了30% 的赞
0.7% 的作者获得了40% 的赞
1.1% 的作者获得了50% 的赞
1.8% 的作者获得了60% 的赞
2.6% 的作者获得了70% 的赞
3.4% 的作者获得了80% 的赞
4.2% 的作者获得了90% 的赞
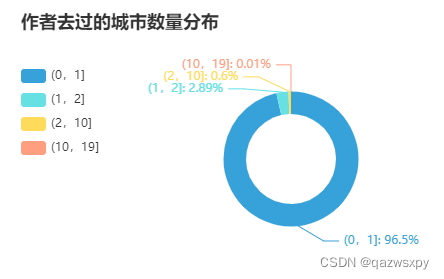
2.3 作者去过的城市数
3. 作品特征分析
3.0 数据读取
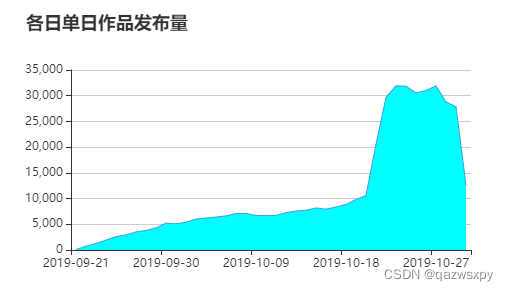
3.1 作品各日发布情况
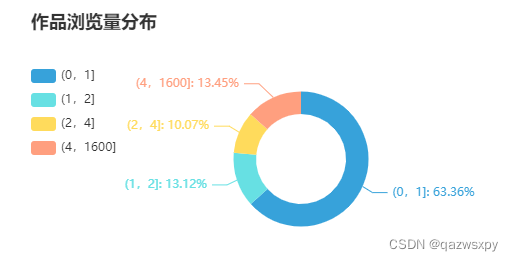
3.2 作品浏览量情况
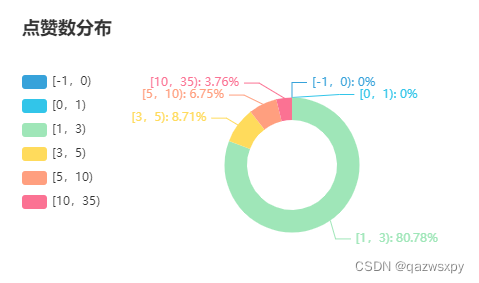
3.3 作品点量率情况
3. 数据挖掘探索
3.1 聚类分析
在对用户、作者、作品进行简单的描述性统计分析与可视化展示后,我们尝试通过一些数据挖掘方法对数据进一步探究
对于抖音平台本身而言,如何对用户进行分类,或者分级,然后差异化的提供服务,是一个非常重要的方向
对于商务合作和广告投放者而言,如何对作者进行分类,如何选择合作的作者,也是有一定价值的问题
3.1中将针对用户和作者的数据特征,使用kmeans聚类算法量化的将两个群体进行分类
import numpy as np
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as opts
from sklearn.cluster import KMeans
import joblib
from sklearn import metrics
from scipy.spatial.distance import cdist
1. 数据读取与数据处理
1.1 数据读取
user_feature = pd.read_csv('用户特征.csv', index_col=0)
author_feature = pd.read_csv('作者特征.csv', index_col=0)
1.2 数据处理
用户聚类可以服务于平台对用户分级,探索性的分析用户特点,但在二、数据可视化分析中,可以看到有一部分用户使用程度平台低 ,浏览少,不点赞,对这样的用户进行聚类分析是无效多余的,增加筛选认为至少观看过一个完整短视频且有一定浏览量的用户才具有分析意义
user_data = user_feature[(user_feature['完整观看数']>=1)&(user_feature['浏览量']>=5)]
print(len(user_data)/len(user_feature))
0.7097514856834144
而在对作者的考量上,聚类的结果是服务于商务合作和广告投放,此时核心是浏览量
而大部分的作者总浏览量非常小,这些作者是无需考虑的,故进行筛选
author_data = author_feature[(author_feature['总观完量']>=1)&(author_feature['总浏览量']>=3)]
print(len(author_data)/len(author_feature))
0.2990244347629775
2. 聚类方法与定义
2.1 聚类方法
关键参数:
- init=‘k-means++’ (其实默认就是这个,可以不用写)
对于kmeans算法,初始中心的选取是至关重要的。
kmeans的随机选取方法可能会出现初始中心过于接近,导致迭代结果收敛慢,效果差
kmeans++通过逐个选取中心,并优先选取距离较远的中心来优化初始中心的选择 - n_clusters: 聚类数
聚类数的确定通过综合不同指标,应用肘部法则进行判断
评价指标
- SSE: 误差平方和
当前迭代得到的中心位置到各自中心点簇的欧式距离总和 - 轮廓系数:sc轮廓系数
都是结合了聚类的类内凝聚度和类间分离度
sc轮廓系数∈[-1, 1],越接近1越好
2.2 相关函数定义
Kmeans
def km(data, name):
K = range(2, 10) # K值选取范围
X = data # 数据
# scores = { 'SSE': [], 'sc': [], 'sse': []}
scores = {'sc': [], 'sse': []}
for _k in K:
# 初始化模型并进行聚类 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
kmeans = KMeans(n_clusters=_k, init='k-means++', random_state=0)
kmeans.fit(X)
_y = kmeans.predict(X) # 预测结果
# 计算模型评估指标 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
sse = sum(np.min(cdist(X,kmeans.cluster_centers_,'euclidean'),axis=1))/X.shape[0]
sc = metrics.silhouette_score(X, _y) # 计算轮廓系数
joblib.dump(kmeans, f'{name}{_k}聚类.model')
# 储存评估值 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# scores['SSE'].append(SSE)
scores['sse'].append(sse)
scores['sc'].append(sc)
print(f'聚{_k}类计算完成', end='\t')
joblib.dump(scores, f'{name}聚类指标.score')
print('指标储存完毕')
return scores
绘制sse和sc曲线
def draw(k, sse, sc):
chart = (
Line(init_opts=opts.InitOpts(
theme='light',
width='350px',
height='350px'
))
.add_xaxis(k)
.add_yaxis('sse', sse, yaxis_index=0, label_opts=opts.LabelOpts(is_show=False))
.add_yaxis('sc', sc, yaxis_index=1, label_opts=opts.LabelOpts(is_show=False))
.extend_axis(yaxis=opts.AxisOpts())
.set_global_opts(
title_opts=opts.TitleOpts(title='聚类效果'),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=True),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
return chart
3. 用户特征聚类
3.1 模型训练与保存
user_score = km(user_data, '用户')
聚2类计算完成 聚3类计算完成 聚4类计算完成 聚5类计算完成 聚6类计算完成 聚7类计算完成 聚8类计算完成 聚9类计算完成 指标储存完毕
3.2 聚类k值选择
user_score = joblib.load(f'用户聚类指标.score')
draw([str(x) for x in range(2,10)], user_score['sse'], user_score['sc']).render_notebook()
<div id="27634cadac5946d99e47111d0e2304ec" style="width:350px; height:350px;"></div>
通过综合肘部法则和sc值,选择 k = 4 k=4 k=4作为用户聚类模型
3.3 聚类结果
user_km = joblib.load(f'用户4聚类.model')
user_centers = pd.DataFrame(user_km.cluster_centers_, columns=user_feature.columns)
user_centers['人数']=pd.Series(user_km.predict(user_data)).value_counts()
user_centers
| 浏览量 | 点赞量 | 观看作者数 | 观看作品数 | 观看作品平均时长 | 观看配乐数 | 完整观看数 | 去过的城市数 | 观看作品城市数 | 人数 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 65.559893 | 0.651947 | 63.616853 | 65.559040 | 11.175167 | 58.035413 | 27.440747 | 1.274133 | 47.094827 | 9366 |
| 1 | 381.603365 | 3.012019 | 353.144231 | 381.598558 | 10.969891 | 276.408654 | 92.346154 | 1.324519 | 140.896635 | 416 |
| 2 | 162.612409 | 1.259288 | 154.847185 | 162.610494 | 11.078860 | 131.901187 | 54.075450 | 1.293757 | 88.666794 | 2610 |
| 3 | 16.791653 | 0.190634 | 16.512585 | 16.791518 | 11.315000 | 15.934307 | 8.124806 | 1.170288 | 14.572070 | 29648 |
4. 作者特征聚类
4.1 模型训练与保存
author_score = km(author_data, '作者')
聚2类计算完成 聚3类计算完成 聚4类计算完成 聚5类计算完成 聚6类计算完成 聚7类计算完成 聚8类计算完成 聚9类计算完成 指标储存完毕
4.2 聚类k值选择
author_score = joblib.load(f'作者聚类指标.score')
draw([str(x) for x in range(2,10)], author_score['sse'], author_score['sc']).render_notebook()
<div id="c4d8bf39862142f49913449f26f579e1" style="width:350px; height:350px;"></div>
通过综合肘部法则和sc值,选择 k = 4 k=4 k=4作为用作者聚类模型
4.3 聚类效果
author_km = joblib.load(f'作者4聚类.model')
author_centers = pd.DataFrame(author_km.cluster_centers_, columns=author_feature.columns)
author_centers['人数'] = pd.Series(author_km.predict(author_data)).value_counts()
author_centers
| 总浏览量 | 总点赞量 | 总观完量 | 总作品数 | 作品平均时长 | 使用配乐数量 | 发布作品日数 | 创作活跃度(日) | 去过的城市数 | 人数 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11.973167 | 0.115981 | 5.019598 | 3.636747 | 10.783111 | 3.198138 | 3.636625 | 11.301008 | 1.114046 | 57356 |
| 1 | 376.060858 | 3.428769 | 165.146611 | 20.035961 | 11.126590 | 13.811895 | 20.034578 | 24.224066 | 1.289073 | 723 |
| 2 | 1092.821053 | 8.347368 | 461.315789 | 31.126316 | 11.165662 | 19.957895 | 31.126316 | 27.926316 | 1.326316 | 95 |
| 3 | 117.075717 | 1.148983 | 51.548395 | 12.432737 | 10.993801 | 9.434942 | 12.431267 | 21.253124 | 1.236217 | 4079 |
总结
聚类的结果解释性较为明显,其核心与浏览量相关,提供了一定数据特征下的量化分类作用
3.2 二分类预测
在用户对作品的浏览过程中,是否点赞是一个非常重要的指标
通过点赞行为,我们可以判断出用户的喜好,评价作品的质量等
拟通过用户特征和作品特征,训练一个用于预测用户是否会点赞的二分类模型
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
from sklearn import ensemble
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.size'] = 20
1. 数据读取与处理
1.1 数据读取
读取数据,并保留用户特征、作品特征和是否点赞,其余无效字段如channel(不确定),finish(没有浏览行为时不存在), H、date(real_time中包括)
df = pd.read_csv('/home/mw/input/somnus8660/douyin_dataset.csv')
del df['Unnamed: 0'], df['H'], df['date'], df['finish'], df['channel']
df.head()
| uid | user_city | item_id | author_id | item_city | like | music_id | duration_time | real_time | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 15692 | 109.0 | 691661 | 18212 | 213.0 | 0 | 11513.0 | 10 | 2019-10-28 21:55:10 |
| 1 | 44071 | 80.0 | 1243212 | 34500 | 68.0 | 0 | 1274.0 | 9 | 2019-10-21 22:27:03 |
| 2 | 10902 | 202.0 | 3845855 | 634066 | 113.0 | 0 | 762.0 | 10 | 2019-10-26 00:38:51 |
| 3 | 25300 | 21.0 | 3929579 | 214923 | 330.0 | 0 | 2332.0 | 15 | 2019-10-25 20:36:25 |
| 4 | 3656 | 138.0 | 2572269 | 182680 | 80.0 | 0 | 238.0 | 9 | 2019-10-21 20:46:29 |
其中uid, user_city为用户信息
item_id, author_id, item_city, music_id, duration_time, real_time都为作品附带信息
like即预测目标是否点赞
1.2 数据抽样处理
为了减少训练成本,对数据集中的数据进行抽样训练
通过等距抽样获取部分浏览信息作为训练数据(需要同时保证点赞数据的合理比例)
df_like = df[df['like']==1]
df_dislike = df[df['like']==0]
data = pd.concat([df_like[::20], df_dislike[::40]], axis=0)
print(len(data)/len(df))
0.02524186789707318
1.3 时间数据处理
训练数据中的real_time字段包括的是字符串对象对应代表时间值,通过将其转化为与固定时间的差值(秒)来进行数值化
flag = pd.to_datetime('2019-01-01 00:00:00')
data['real_time'] = pd.to_datetime(data['real_time'])
data['real_time'] = pd.to_timedelta( data['real_time'] - flag).dt.total_seconds()
data.head()
| uid | user_city | item_id | author_id | item_city | like | music_id | duration_time | real_time | |
|---|---|---|---|---|---|---|---|---|---|
| 134 | 32039 | 2.0 | 1324665 | 48937 | 15.0 | 1 | 578.0 | 10 | 24181411.0 |
| 2181 | 14571 | 142.0 | 2489542 | 37131 | 229.0 | 1 | 1318.0 | 7 | 25305835.0 |
| 3955 | 25090 | 136.0 | 1582882 | 16382 | 69.0 | 1 | 680.0 | 10 | 23180382.0 |
| 5685 | 11153 | 73.0 | 209250 | 28248 | 137.0 | 1 | 4545.0 | 9 | 24856880.0 |
| 8647 | 2159 | 106.0 | 1019916 | 246 | 18.0 | 1 | 3928.0 | 9 | 25677638.0 |
1.4 数据集划分
xtrain,xtest, ytrain, ytest = \
train_test_split(
data.drop('like', axis=1), # X
data['like'],test_size=0.3, # Y
random_state=0 # random_seed
)
2. 模型预训练
2.1 模型训练函数
def train(name, model):
model = model.fit(xtrain, ytrain)
print(f'{name}准确率: \t{model.score(xtest, ytest)}')
return model
2.2 模型训练
# 逻辑回归
lgs = train('lgs', LogisticRegression(solver='liblinear', C=100.0,random_state=1))
# 朴素贝叶斯
gnb = train('gnb', GaussianNB().fit(xtrain,ytrain))
# 单棵决策树
clf = train('clf', DecisionTreeClassifier(class_weight='balanced',random_state=0))
# 随机森林
rfc = train('rfc', RandomForestClassifier(n_estimators=100, class_weight='balanced',random_state=0))
lgs准确率: 0.9805411979325023
gnb准确率: 0.9801611432046214
clf准确率: 0.959866220735786
rfc准确率: 0.9805411979325023
2.3 模型AUC曲线
def my_auc(model):
y_test_proba = model.predict_proba(xtest)
false_positive_rate, recall, thresholds = roc_curve(ytest, y_test_proba[:, 1])
roc_auc = auc(false_positive_rate, recall)
return false_positive_rate, recall, roc_auc
lgs_auc = my_auc(lgs)
gnb_auc = my_auc(gnb)
clf_auc = my_auc(clf)
rfc_auc = my_auc(rfc)
# 画图 画出俩模型的ROC曲线
plt.plot(lgs_auc[0], lgs_auc[1], color='cyan', label='AUC_lgs=%0.3f' % lgs_auc[2])
plt.plot(gnb_auc[0], gnb_auc[1], color='blue', label='AUC_gnb=%0.3f' % gnb_auc[2])
plt.plot(clf_auc[0], clf_auc[1], color='green', label='AUC_clf=%0.3f' % clf_auc[2])
plt.plot(rfc_auc[0], rfc_auc[1], color='yellow', label='AUC_rfc=%0.3f' % rfc_auc[2])
plt.legend(loc='best', fontsize=12, frameon=False)
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()

综合准确率和AUC值表现,模型的效果不是很好,在数据抽样时扩大抽样规模会有效的提高auc值,同时点赞和不点赞的数据分布较为不均衡也是重要原因
这里只做继续方法的演示,相对来说随机森林的效果比较好,所以选择随机森林作为二分类模型
3. 模型优化
使用GridSearchCV模块进行格栅优化,可以理解为每一个训练参数都是表格的一个维度,根据传入值,遍历格栅中每一种参数组合,最后告诉你最优组合
一般来说直接把多个模型参数输入即可,但是多个维度参数的组合会导致训练模型量剧增
这里遍历了9个n_e值和10个max_f值,加上cv=3需要三折交叉,就产生了9x10x3=270次训练,非常抽象
一个合理的解决方法是解耦,通过把两个参数分离优化来减少训练量,达到相对较好但不是最优的效果
## 需要270次的最优方法
# params = {
# 'n_estimators': [x for x in range(100,1000,100)],
# 'max_features': range(1,20,2)
# }
# grid = GridSearchCV(
# RandomForestClassifier(class_weight='balanced', random_state=0),
# params, scoring="roc_auc",
# cv=3, verbose=1, n_jobs=-1
# ).fit(xtrain, ytrain)
3.1 n_e优化
params = {
'n_estimators': [x for x in range(100,1500,100)]
}
grid = GridSearchCV(
RandomForestClassifier(class_weight='balanced', random_state=0),
params, scoring="roc_auc",
cv=3, verbose=1, n_jobs=-1
).fit(xtrain, ytrain)
Fitting 3 folds for each of 14 candidates, totalling 42 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.
/opt/conda/lib/python3.6/site-packages/joblib/externals/loky/process_executor.py:706: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak.
"timeout or by a memory leak.", UserWarning
[Parallel(n_jobs=-1)]: Done 42 out of 42 | elapsed: 10.1min finished
a = grid.cv_results_['mean_test_score']
plt.plot(params['n_estimators'], a, color='blue')
plt.show()

grid.best_params_
{'n_estimators': 1000}
选择参数为1000
3.2 max_f优化
params = {
'max_features': range(2,10,2)
}
grid = GridSearchCV(
RandomForestClassifier(n_estimators=1000, class_weight='balanced', random_state=0),
params, scoring="roc_auc",
cv=3, verbose=1, n_jobs=-1
).fit(xtrain, ytrain)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=-1)]: Done 12 out of 12 | elapsed: 8.2min finished
a = grid.cv_results_['mean_test_score']
plt.plot(params['max_features'], a, color='blue')
plt.show()

grid.best_params_
{'max_features': 6}
3.3 模型训练
rfc0 = RandomForestClassifier(n_estimators=1000,
max_features=6,
class_weight='balanced',
random_state=0)
rfc0 = train('rfc++', rfc0)
rfc++准确率: 0.9805411979325023
对比优化前后
auc_rfc0 = my_auc(rfc0)
# 画图 画出俩模型的ROC曲线
plt.plot(auc_rfc0[0], auc_rfc0[1], color='cyan', label='rfc++=%0.3f' % auc_rfc0[2])
plt.plot(rfc_auc[0], rfc_auc[1], color='yellow', label='rfc=%0.3f' % rfc_auc[2])
plt.legend(loc='best', fontsize=12, frameon=False)
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()

虽然整体的效果不行,auc值比较低,但是可以看到有优化提升
4. 模型预测
4.1 模型准确率
df.head()
| uid | user_city | item_id | author_id | item_city | like | music_id | duration_time | real_time | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 15692 | 109.0 | 691661 | 18212 | 213.0 | 0 | 11513.0 | 10 | 2019-10-28 21:55:10 |
| 1 | 44071 | 80.0 | 1243212 | 34500 | 68.0 | 0 | 1274.0 | 9 | 2019-10-21 22:27:03 |
| 2 | 10902 | 202.0 | 3845855 | 634066 | 113.0 | 0 | 762.0 | 10 | 2019-10-26 00:38:51 |
| 3 | 25300 | 21.0 | 3929579 | 214923 | 330.0 | 0 | 2332.0 | 15 | 2019-10-25 20:36:25 |
| 4 | 3656 | 138.0 | 2572269 | 182680 | 80.0 | 0 | 238.0 | 9 | 2019-10-21 20:46:29 |
转换一下df中的时间,看看使用2.5%左右的数据训练出来的模型准确率能有多少
flag = pd.to_datetime('2019-01-01 00:00:00')
df['real_time'] = pd.to_datetime(df['real_time'])
df['real_time'] = pd.to_timedelta( df['real_time'] - flag).dt.total_seconds()
rfc0.score(df.drop('like', axis=1), df['like'])
0.9906533771711702
4.2 一些说明
表面上来看准确率是比较高的,但是我们来看一下不点赞的数据占比
lk = df['like'].value_counts()
lk
0 1720539
1 16773
Name: like, dtype: int64
lk[0]/lk.sum()
0.9903454301817981
也就是只要全都预测不点赞,也能有99.03的准确率,模型稍微准一点,还行,但是auc值低是硬伤
![[附源码]SSM计算机毕业设计影院售票系统JAVA](https://img-blog.csdnimg.cn/150b62413b6f49ffac92dc682e328585.png)



![[附源码]计算机毕业设计springboot天狗电子商城系统](https://img-blog.csdnimg.cn/b454b73450fb4945b5c3c0b8dfbb1bb9.png)