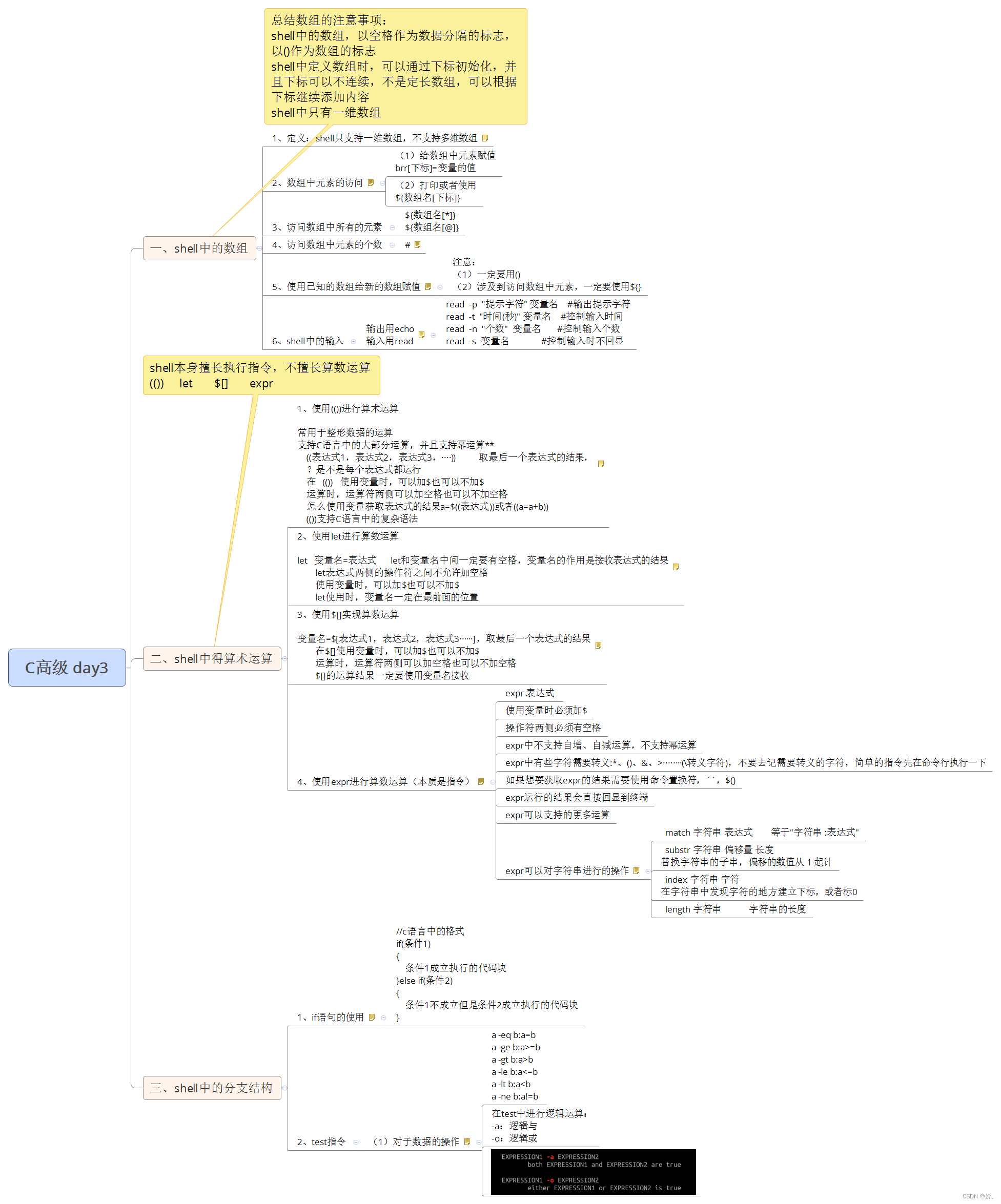
基于RV1126平台分类模型全流程部署
- 环境安装
- 模型训练
- ONNX模型转换
- RKNN模型转换
- 可执行文件上板推理
环境安装
首先要在虚拟机上安装瑞芯微Rv1126的SDK,重要的是要具有rknn_toolchain
一般在以下路径:
sdk/external/rknn-toolkit
按照doc里面的步骤安装即可
项目工程代码在:https://github.com/liuyuan000/rv1126_mnist/tree/main/RKNN_Cpp/rknn_mnist_demo
模型训练
首先以MNIST手写数字体的分类为例说明分类模型的全流程部署,首先要使用torch对模型进行训练,运行以下代码即可:
import torch
import numpy as np
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
"""
卷积运算 使用mnist数据集,和10-4,11类似的,只是这里:1.输出训练轮的acc 2.模型上使用torch.nn.Sequential
"""
# Super parameter ------------------------------------------------------------------------------------
batch_size = 64
learning_rate = 0.01
momentum = 0.5
EPOCH = 10
# Prepare dataset ------------------------------------------------------------------------------------
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中0.1307是mean均值和0.3081是std标准差
train_dataset = datasets.MNIST(root='./data/mnist', train=True, transform=transform,download=True) # 本地没有就加上download=True
test_dataset = datasets.MNIST(root='./data/mnist', train=False, transform=transform) # train=True训练集,=False测试集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i+1)
plt.tight_layout()
plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none')
plt.title("Labels: {}".format(train_dataset.train_labels[i]))
plt.xticks([])
plt.yticks([])
plt.show()
# 训练集乱序,测试集有序
# Design model using class ------------------------------------------------------------------------------
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 10, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(10, 20, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.fc = torch.nn.Sequential(
torch.nn.Linear(320, 50),
torch.nn.Linear(50, 10),
)
def forward(self, x):
batch_size = x.size(0)
x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)
x = self.conv2(x) # 再来一次
x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320
x = self.fc(x)
x = torch.sigmoid(x)
return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)
model = Net()
# Construct loss and optimizer ------------------------------------------------------------------------------
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量
# Train and Test CLASS --------------------------------------------------------------------------------------
# 把单独的一轮一环封装在函数类里
def train(epoch):
running_loss = 0.0 # 这整个epoch的loss清零
running_total = 0
running_correct = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# 把运行中的loss累加起来,为了下面300次一除
running_loss += loss.item()
# 把运行中的准确率acc算出来
_, predicted = torch.max(outputs.data, dim=1)
running_total += inputs.shape[0]
running_correct += (predicted == target).sum().item()
if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率
print('[%d, %5d]: loss: %.3f , acc: %.2f %%'
% (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total))
running_loss = 0.0 # 这小批300的loss清零
running_total = 0
running_correct = 0 # 这小批300的acc清零
torch.save(model.state_dict(), './model_Mnist.pth')
# torch.save(optimizer.state_dict(), './optimizer_Mnist.pth')
def test():
correct = 0
total = 0
with torch.no_grad(): # 测试集不用算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标
total += labels.size(0) # 张量之间的比较运算
correct += (predicted == labels).sum().item()
acc = correct / total
print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数
return acc
# Start train and Test --------------------------------------------------------------------------------------
if __name__ == '__main__':
acc_list_test = []
for epoch in range(EPOCH):
train(epoch)
# if epoch % 10 == 9: #每训练10轮 测试1次
acc_test = test()
acc_list_test.append(acc_test)
plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy On TestSet')
plt.show()
程序会自动下载数据集,并进行训练
运行结束后我们得到:model_Mnist.pth模型
ONNX模型转换
仍然使用torch加载训练后的模型,将其转换成onnx模型格式,转换代码如下:
import torch
import numpy as np
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 10, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(10, 20, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.fc = torch.nn.Sequential(
torch.nn.Linear(320, 50),
torch.nn.Linear(50, 10),
)
def forward(self, x):
batch_size = x.size(0)
x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)
x = self.conv2(x) # 再来一次
x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320
x = self.fc(x)
x = torch.sigmoid(x)
return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)
model = Net()
model.load_state_dict(torch.load('./model_Mnist.pth'))
model.eval()
x=torch.randn((1,1,28,28))
torch.onnx.export(model, # 搭建的网络
x, # 输入张量
'mnist.onnx', # 输出模型名称
input_names=["input"], # 输入命名
output_names=["output"], # 输出命名
opset_version=10,
dynamic_axes={'input':{0:'batch'}, 'output':{0:'batch'}} # 动态轴
)
其中需要注意的是opset_version,算子的版本不要选的太高,不然在后续模型转换的时候可能会出问题。
这样我们就能得到mnist.onnx文件,使用Netron可以打开:

可以看出整个网络的结构还是很简单的。
RKNN模型转换
得到onnx模型之后,我们就可以使用rknn.api中的RKNN将其转换为RKNN格式,方便上板推理。
此时应当使用虚拟机连接开发板,转换后会自动使用开发板进行模型推理等操作。
在进行转换之前,还需要准备几张数据集图片,把图片路径放到dataset.txt文件中,方便量化时微调网络参数。
从MNIST数据集中提取图片可以使用以下程序:
import os
import shutil
from tqdm import tqdm
from torchvision import datasets
from concurrent.futures import ThreadPoolExecutor
def mnist_export(root: str = './data/minst'):
"""Export MNIST data to a local folder using multi-threading.
Args:
root (str, optional): Path to local folder. Defaults to './data/minst'.
"""
for i in range(10):
os.makedirs(os.path.join(root, f'./{i}'), exist_ok=True)
split_list = ['train', 'test']
data = {
split: datasets.MNIST(
root='./tmp',
train=split == 'train',
download=True
) for split in split_list
}
total = sum([len(data[split]) for split in split_list])
with tqdm(total=total) as pbar:
with ThreadPoolExecutor() as tp:
for split in split_list:
for index, (image, label) in enumerate(data[split]):
tmp = os.path.join(root, f'{label}/{split}_{index}.png')
tp.submit(image.save, tmp).add_done_callback(
lambda func: pbar.update()
)
shutil.rmtree('./tmp')
if __name__ == '__main__':
mnist_export('./data/minst')
dataset.txt存放图片路径即可,示例如下:
/home/alientek/atk/mnist/data/minst/0/test_3.png
/home/alientek/atk/mnist/data/minst/0/test_10.png
/home/alientek/atk/mnist/data/minst/0/test_13.png
/home/alientek/atk/mnist/data/minst/0/test_25.png
/home/alientek/atk/mnist/data/minst/0/test_28.png
/home/alientek/atk/mnist/data/minst/0/test_55.png
/home/alientek/atk/mnist/data/minst/0/test_69.png
/home/alientek/atk/mnist/data/minst/0/test_7.png
/home/alientek/atk/mnist/data/minst/0/test_101.png
/home/alientek/atk/mnist/data/minst/0/test_126.png
此时使用python执行量化操作,指定平台为RV1126:
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
ONNX_MODEL = 'mnist.onnx'
RKNN_MODEL = 'mnist.rknn'
def show_outputs(outputs):
output = outputs[0][0]
output_sorted = sorted(output, reverse=True)
top5_str = 'resnet50v2\n-----TOP 5-----\n'
for i in range(5):
value = output_sorted[i]
index = np.where(output == value)
for j in range(len(index)):
if (i + j) >= 5:
break
if value > 0:
topi = '{}: {}\n'.format(index[j], value)
else:
topi = '-1: 0.0\n'
top5_str += topi
print(top5_str)
def readable_speed(speed):
speed_bytes = float(speed)
speed_kbytes = speed_bytes / 1024
if speed_kbytes > 1024:
speed_mbytes = speed_kbytes / 1024
if speed_mbytes > 1024:
speed_gbytes = speed_mbytes / 1024
return "{:.2f} GB/s".format(speed_gbytes)
else:
return "{:.2f} MB/s".format(speed_mbytes)
else:
return "{:.2f} KB/s".format(speed_kbytes)
def show_progress(blocknum, blocksize, totalsize):
speed = (blocknum * blocksize) / (time.time() - start_time)
speed_str = " Speed: {}".format(readable_speed(speed))
recv_size = blocknum * blocksize
f = sys.stdout
progress = (recv_size / totalsize)
progress_str = "{:.2f}%".format(progress * 100)
n = round(progress * 50)
s = ('#' * n).ljust(50, '-')
f.write(progress_str.ljust(8, ' ') + '[' + s + ']' + speed_str)
f.flush()
f.write('\r\n')
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN()
# If resnet50v2 does not exist, download it.
# Download address:
# https://s3.amazonaws.com/onnx-model-zoo/resnet/resnet50v2/resnet50v2.onnx
# pre-process config
print('--> config model')
rknn.config(mean_values=[[0]], std_values=[[1]], reorder_channel='0 1 2',target_platform='rv1126')# 灰度图,均值方差单通道
print('done')
# Load tensorflow model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load mnist failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
if ret != 0:
print('Build resnet50 failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export resnet50v2.rknn failed!')
exit(ret)
print('done')
# Set inputs
#img = cv2.imread('/home/alientek/atk/mnist/data/minst/0/test_3.png',0)
img = cv2.imread('/home/alientek/atk/mnist/data/minst/1/test_2.png',0)# 推理图片路径,灰度图
#img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(target='rv1126')
#ret = rknn.init_runtime(target='rv1126',perf_debug=True,eval_mem=True)
#ret = rknn.eval_perf(inputs=[img], is_print=True)
#memory_detail = rknn.eval_memory()
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
show_outputs(outputs)
print('done')
rknn.release()
运行以上程序即可得到:
--> Export RKNN model
done
--> Init runtime environment
I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:36)
D RKNNAPI: ==============================================
D RKNNAPI: RKNN VERSION:
D RKNNAPI: API: 1.7.0 (f75fb8e build: 2021-07-20 16:23:11)
D RKNNAPI: DRV: 1.7.0 (7880361 build: 2021-08-16 14:05:08)
D RKNNAPI: ==============================================
done
--> Running model
resnet50v2
-----TOP 5-----
[1]: 1.0
-1: 0.0
-1: 0.0
-1: 0.0
-1: 0.0
done
最终输出的结果是1,并且网络具有100%把握。
可执行文件上板推理
最终为了效率等考量,一般在开发板上运行cpp编写成的可执行文件。
这里我把整个项目上传到github
网址如下:https://github.com/liuyuan000/rv1126_mnist/
下载后打开到:RKNN_Cpp/rknn_mnist_demo路径下
修改交叉编译工具链,修改成你的路径:
RV1109_TOOL_CHAIN=/opt/atk-dlrv1126-toolchain/usr
GCC_COMPILER=${RV1109_TOOL_CHAIN}/bin/arm-linux-gnueabihf
然后直接执行以下命令即可
./build.sh
执行后如下所示:

我们得到 build 和 install文件夹

将install下的mnist/RKNN_Cpp/rknn_mnist_demo/install/rknn_mnist_demo文件夹拷贝到开发板:
adb push ./rknn_mnist_demo/ /demo/MY
并且拷贝一张mnist数据集里的图片到开发板上
然后执行:
adb shell
进入开发板命令行:

执行以下命令加载模型和测试图片:
./rknn_mnist_demo ./model/mnist.rknn ./model/test_871.png
程序输出:

最终871图片分类为0,查看一下:

分类成功结束。


![[架构之路-194]-《软考-系统分析师》- 软件复用技术之软件产品线](https://img-blog.csdnimg.cn/35324a5efcbb4b449be9b03471a33353.png)