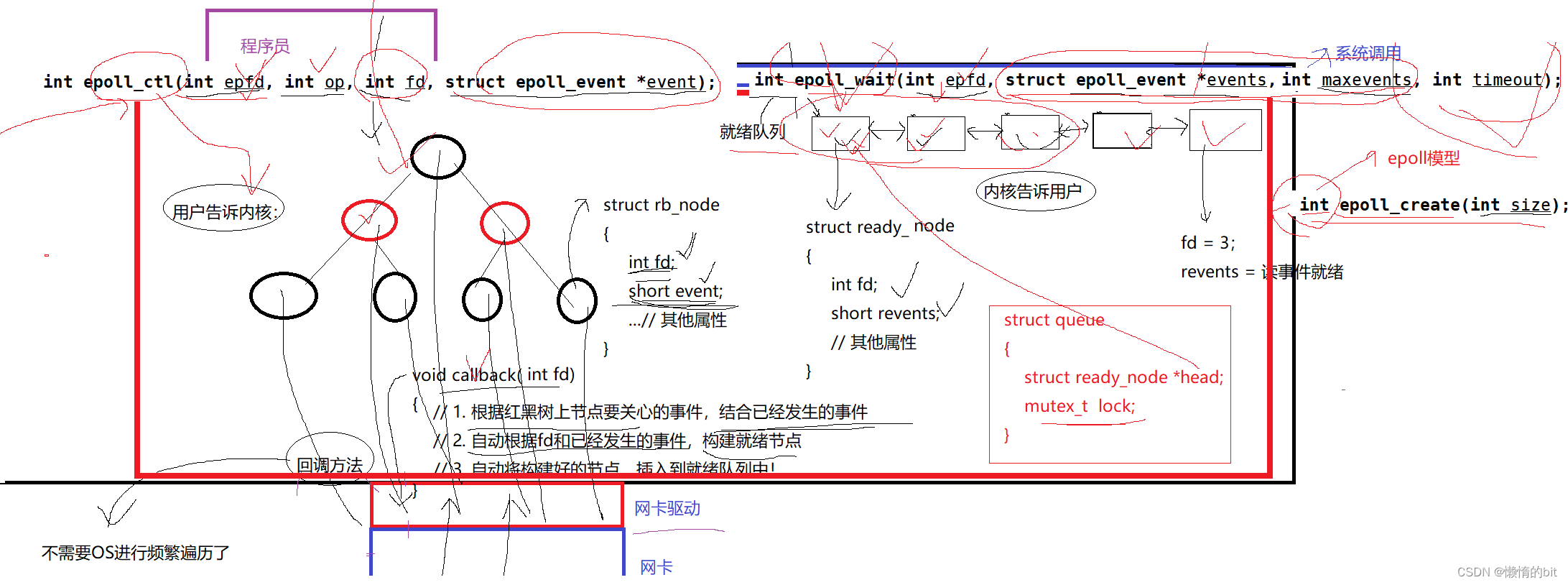
一、定义
1、无监督域自适应 Unsupervised domain adaptation
经典机器学习假设训练集和测试集来自相同的分布。
然而,这个假设在现实世界的应用程序中可能并不总是成立,例如,数据来源不同。
这种情况下,域分布之间会存在差异,直接将训练好的模型应用于新数据集可能会导致性能下降。
本贴主要讨论无监督域自适应(有标签的源域、无标签的目标域)。
2、域的组成
域由特征空间和边际概率分布(即数据的特征和这些特征在数据集中的分布)组成。根据这个定义,域的变化可能是由特征空间的变化或边际概率分布的变化引起的。当使用文本挖掘对文档进行分类时,特征空间的变化可能是由于语言的变化(例如,英语到西班牙语),而边际概率分布的变化可能是由于文档主题的变化(例如,计算机科学到英国文学)。
Homogeneous domain adaptation 均匀的 特征空间相同
heterogeneous domain adaptation 不均匀的 特征空间不同
二、相关问题
介绍相关问题,更好的界定domain adaptation的研究范围。
多域学习 (multi-domain learning ):如何将多个相关渠道的数据放在一起训练,而能够相互促进,而非相互干扰。一般数据量不是很多的时候这样做。
领域泛化(domain generalization):即在带有标记数据的多个源领域上训练模型,然后在训练过程中未看到的另外的目标领域上进行测试。这与领域自适应形成对比,在领域自适应中,目标示例(可能未标记)在训练期间可用。
迁移学习(transfer learning)问题可能是将知识从源领域转移到不同的目标领域,也可能是将知识从源任务转移到不同的目标任务(或两者的结合)。域由特征空间和边际概率分布(即数据的特征和这些特征在数据集中的分布)组成。任务由标签空间和客观预测函数(即从训练数据中学习到的标签集和预测函数)组成。域自适应是一类特殊的迁移学习。
三、背景
1、Generative adversarial networks(GANs)
1)理论基础
让两个匹配良好的神经网络相互对抗,扮演数据鉴别器和数据生成器的角色,这对组合能够完善每个玩家(数据鉴别器、数据生成器)的能力,以执行合成数据生成等功能。
生成器的输入为噪声向量,其中包含从某些分布(如正态分布或均匀分布)中提取的随机值。
生成器网络的目标是输出一个与真实训练数据无法区分的向量。
鉴别器的输入为来自训练数据的真实样本或来自生成器的假样本作为输入。
鉴别器的目标是确定输入样本为真实的概率。
在训练过程中,这两个网络玩一个极大极小的游戏,其中生成器试图愚弄鉴别器,而鉴别器试图不被愚弄。优化目标如下,其中D(G(z)) 为生成数据G(z)为真的概率:

最终的目标,我们希望判别器能够鉴别真伪,即上式最大化;理想情况下,真实的判为真,
D(x)为1;假的判为假,logD(G(z))为0;log为单调递增函数,上式取得最大值;
而生成器的目标,则是混淆结果,上式最小化;理想情况下,真实的判为假,D(x)为0;假的判为真,logD(G(z))为1;log为单调递增函数,上式取得最小值;
通过这样的极大极小对抗,生成足以混淆生成器的样本,并实现好的分类效果。
2)面临问题
基于对抗思想,训练过程中可能会出现难以收敛、模式崩溃(生成器只学习生成数据分布的几个特定模式的真实样本)以及梯度消失等问题。
3)评价指标
生成器评价指标:Parzen窗口估计、记忆检测、确定多样性、测量真实性、近似对数似然的方法。
针对任务的评价指标:分割任务AUC、分类任务Accuracy等。
更多的时候,还是采用的针对任务的评价指标。
四、方法
域适应和神经网络结合,出现了一下几个研究方向:
4.1、Domain-Invariant Feature Learning 域不变特征学习
这类方法假设存在这样的特征表示,并且边缘标签分布没有显着差异。
通过创建域不变特征表示(通常以特征提取器神经网络的形式)来对齐源域和目标域。
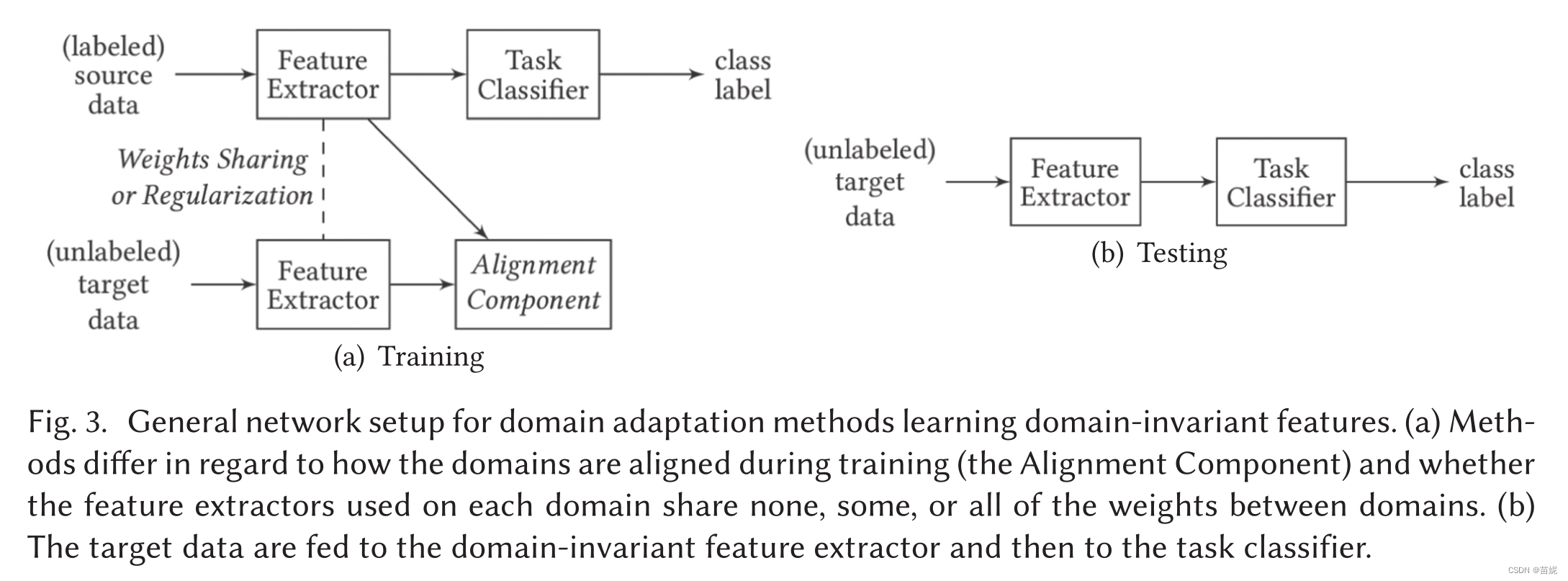
学习域不变特征的域自适应方法的一般网络设置如下图所示。(a)在训练过程中如何对齐域(对齐组件)以及每个域上使用的特征提取器是否在域之间不共享,部分共享或全部共享权重方面,方法有所不同。(b)将目标数据送入域不变特征提取器,再送入任务分类器。
下面讨论各种特征对齐方式。
4.1.1 Divergence.
4.1.2 Reconstruction.
4.1.3 Adversarial.
这里介绍的是特征级对抗域自适应方法。不同方法主要是对齐组件的组成不同。在大多数情况下,对齐组件由域分类器组成,当然也有可能是学习近似Wasserstein距离的网络或GAN。
域分类器的主要作用是判断输出特征是从来自源域还是目标域。
对比,GAN中的判别器,它试图准确地预测样本是来自真实数据分布还是来自生成器。换句话说,鉴别器区分两个分布,一个是实分布,一个是假分布。
域分类器的目标是正确地对域(源或目标)进行分类。在这种情况下,对特征提取器进行训练,使得域分类器无法对特征表示来自哪个领域进行分类。
通常,这些网络通过在这两个步骤之间交替进行对抗性训练。在执行反向传播以更新特征提取器权重时通过训练特征提取器,使具有梯度反转层的域分类器的梯度为负,从而使域分类器表现不佳,最大程度地混淆域分类器(当它在二元标签上输出均匀分布时),或反转标签。
由于数据分布通常是多模态的,因此可以通过在特征表示和任务分类器预测的多线性映射上调节域分类器来改善结果,这考虑了分布的多模态性质。
五、参考文献
1、Wilson G, Cook D J. A survey of unsupervised deep domain adaptation[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2020, 11(5): 1-46.
2、Swami Sankaranarayanan, Yogesh Balaji, Arpit Jain, Ser Nam Lim, and Rama Chellappa. 2018. Learning from synthetic data: Addressing domain shift for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
3、
【迁移学习】Domain Adaptation系列论文解析(不断更新中) - 知乎
【迁移学习】Domain Adaptation系列论文解析(二) - 知乎