Cheng R, Jin Y. A competitive swarm optimizer for large scale optimization[J]. IEEE transactions on cybernetics, 2014, 45(2): 191-204.
1.1 背景介绍
CSO(competitive swarm optimizer)算法是在PSO(particle swarm optimization)算法的基础上改进而来的。PSO算法是一种功能强大、应用广泛的群体智能算法,主要用来解决优化问题。PSO算法包含一个粒子群,粒子群里面的每个粒子均有1个 n n n维位置变量和1个 n n n维速度变量。在算法的每次迭代过程中,每个粒子的位置变量 X i X_{i} Xi和速度变量 V i V_{i} Vi通过以下公式进行更新:
V i ( t + 1 ) = ω V i ( t ) + c 1 R 1 ( t ) ( p b e s t i ( t ) − X i ( t ) ) + c 2 R 2 ( t ) ( g b e s t ( t ) − X i ( t ) ) \begin{aligned} V_{i}(t+1)=\omega V_{i}(t) & +c_{1}R_{1}(t)(pbest_{i}(t)-X_{i}(t)) +c_{2} R_{2}(t)(gbest(t)-X_{i}(t)) \end{aligned} Vi(t+1)=ωVi(t)+c1R1(t)(pbesti(t)−Xi(t))+c2R2(t)(gbest(t)−Xi(t))
X i ( t + 1 ) = X i ( t ) + V i ( t + 1 ) X_{i}(t+1)=X_{i}(t)+V_{i}(t+1) Xi(t+1)=Xi(t)+Vi(t+1)
其中 t t t是当前迭代数, ω \omega ω是惯性权重, c 1 c_{1} c1和 c 2 c_{2} c2是加速度系数, R 1 ( t ) R_{1}(t) R1(t)和 R 2 ( t ) R_{2}(t) R2(t)是两个向量,向量中每个元素取值范围为 [ 0 , 1 ] n [0,1]^{n} [0,1]n, p b e s t i ( t ) pbest_{i}(t) pbesti(t)是第 i i i个粒子的历史最优解, g b e s t ( t ) gbest(t) gbest(t)是所有粒子的历史最优解。 c 1 R 1 ( t ) ( p b e s t i ( t ) − X i ( t ) ) c_{1}R_{1}(t)(pbest_{i}(t)-X_{i}(t)) c1R1(t)(pbesti(t)−Xi(t))为认知部分, c 2 R 2 ( t ) ( g b e s t ( t ) − X i ( t ) ) c_{2} R_{2}(t)(gbest(t)-X_{i}(t)) c2R2(t)(gbest(t)−Xi(t))为社会部分。
当优化问题存在大量局部最优值和具有高维特点时,传统PSO算法在处理此类问题时会过早收敛,从而导致其优化效果不佳。首先来看 g b e s t gbest gbest对算法收敛过程的影响,将上述公式进行变换,可得:
V i ( t + 1 ) = ω V i ( t ) + θ 1 ( p 1 − X i ( t ) ) V_{i}(t+1)=\omega V_{i}(t)+\theta_{1}(p_{1}-X_{i}(t)) Vi(t+1)=ωVi(t)+θ1(p1−Xi(t))
其中,
θ 1 = c 1 R 1 ( t ) + c 2 R 2 ( t ) \theta_{1}=c_{1}R_{1}(t)+c_{2} R_{2}(t) θ1=c1R1(t)+c2R2(t)
p 1 = c 1 R 1 ( t ) c 1 R 1 ( t ) + c 2 R 2 ( t ) p b e s t i ( t ) + c 2 R 2 ( t ) c 1 R 1 ( t ) + c 2 R 2 ( t ) g b e s t ( t ) p_{1} =\frac{c_{1} R_{1}(t)}{c_{1} R_{1}(t)+c_{2} R_{2}(t)} pbest_{i}(t) +\frac{c_{2} R_{2}(t)}{c_{1} R_{1}(t)+c_{2} R_{2}(t)}gbest(t) p1=c1R1(t)+c2R2(t)c1R1(t)pbesti(t)+c1R1(t)+c2R2(t)c2R2(t)gbest(t)
p 1 p_{1} p1和 X i X_{i} Xi的差决定了粒子群的种群多样性,而 p b e s t i pbest_{i} pbesti和 g b e s t gbest gbest的取值多样性决定了 p 1 p_{1} p1取值的多样性。由于 g b e s t gbest gbest的影响,随着迭代过程的继续,粒子逐渐向 g b e s t gbest gbest靠拢,这导致 p b e s t i pbest_{i} pbesti逐渐接近 g b e s t gbest gbest,进而导致粒子群的种群多样性大幅降低。 p 1 p_{1} p1在很大程度上决定着传统PSO算法在搜索过程中的勘探能力和开采能力。
为了解决传统PSO算法的过早收敛问题,本文提出了CSO算法。该算法去掉了 p b e s t i pbest_{i} pbesti和 g b e s t gbest gbest两个变量,引入了粒子间的成对竞争机制。在该机制中,竞争失败的粒子将向竞争胜利的粒子学习,而不是向 p b e s t i pbest_{i} pbesti和 g b e s t gbest gbest学习,这将较好地解决传统PSO算法的过早收敛问题。
1.2 算法流程

CSO算法的总体思想如图所示。在每一次迭代过程中,随机从粒子群 P ( t ) P(t) P(t)中选择一对粒子进行竞争。竞争成功的粒子直接进入下一次迭代,竞争失败的粒子将向竞争成功的粒子学习并更新自己的位置变量和速度变量。该操作完成后,将这一对粒子从粒子群 P ( t ) P(t) P(t)中剔除,将竞争成功的粒子和更新后的失败粒子加入到粒子群 P ( t + 1 ) P(t+1) P(t+1)中。当所有粒子从粒子群 P ( t ) P(t) P(t)中移到粒子群 P ( t + 1 ) P(t+1) P(t+1)中后,算法进入下一次迭代。根据上图可知,每一次迭代将会使粒子群 P P P中一半的粒子得到更新。
竞争失败的粒子的速度变量和位置变量更新如以下公式所示:
V l , k ( t + 1 ) = R 1 ( k , t ) V l , k ( t ) + R 2 ( k , t ) ( X w , k ( t ) − X l , k ( t ) ) + φ R 3 ( k , t ) ( X ˉ k ( t ) − X l , k ( t ) ) \begin{aligned} V_{l, k}(t+1) & =R_{1}(k, t) V_{l, k}(t) +R_{2}(k, t)(X_{w, k}(t)-X_{l, k}(t)) +\varphi R_{3}(k, t)(\bar{X}_{k}(t)-X_{l, k}(t)) \end{aligned} Vl,k(t+1)=R1(k,t)Vl,k(t)+R2(k,t)(Xw,k(t)−Xl,k(t))+φR3(k,t)(Xˉk(t)−Xl,k(t))
X l , k ( t + 1 ) = X l , k ( t ) + V l , k ( t + 1 ) X_{l, k}(t+1) = X_{l, k}(t)+V_{l, k}(t+1) Xl,k(t+1)=Xl,k(t)+Vl,k(t+1)
其中, X w , k ( t ) X_{w, k}(t) Xw,k(t)表示第 t t t代的第 k k k轮竞争中竞争成功粒子的位置, X l , k ( t ) X_{l, k}(t) Xl,k(t)表示第 t t t代的第 k k k轮竞争中竞争失败粒子的位置, V l , k ( t ) V_{l, k}(t) Vl,k(t)表示第 t t t代的第 k k k轮竞争中竞争失败粒子的速度, R 1 ( k , t ) R_{1}(k, t) R1(k,t)、 R 2 ( k , t ) R_{2}(k, t) R2(k,t)、 R 3 ( k , t ) ∈ [ 0 , 1 ] R_{3}(k, t) \in \left [ 0,1 \right ] R3(k,t)∈[0,1]分别表示算法第 t t t次迭代的第 k k k轮竞争中随机生成的向量。
X ˉ k ( t ) \bar{X}_{k}(t) Xˉk(t)表示第 t t t代的第 k k k轮竞争中相关粒子的位置平均值,它分为全局版本和局部版本。
- X ˉ k g ( t ) \bar{X}_{k}^{g}(t) Xˉkg(t)表示 P ( t ) P(t) P(t)中所有粒子的位置平均值,是全局版本。
- X ˉ l , k l ( t ) \bar{X}_{l,k}^{l}(t) Xˉl,kl(t)表示在竞争失败粒子的预定义邻域内所有粒子的位置平均值,是局部版本。领域控制可以增加粒子群的种群多样性,这可能会提高CSO算法的搜索能力。

function [best_x, best_y, best_y_history] = Optimizer_CSO(obj_fun, num_vari, lower_bound, upper_bound, pop_size, max_gen, varphi)
generation = 1;
best_y_history = [];
pop_size = pop_size - rem(pop_size, 2); % rem:除后的余数。保证种群数是偶数。
pop_position = lhsdesign(pop_size, num_vari) * (upper_bound - lower_bound) + lower_bound; % 初始化种群
pop_fitness = feval(obj_fun, pop_position); % 计算种群的适应度函数值
pop_velocity = zeros(pop_size, num_vari);
while generation < max_gen - 1 % 迭代求解,保证总的评估次数为0.5*pop_size*max_gen
randrows = randperm(pop_size); % 模拟随机选择两个粒子的过程
mean_pop_position = mean(pop_position); % 这一行代码也可以放在for循环中
for i = 1 : pop_size / 2
first_particle = randrows(2 * (i - 1) + 1);
second_particle = randrows(2 * i);
if pop_fitness(first_particle) <= pop_fitness(second_particle) % 这里以求目标函数最小值为例
win = first_particle;
loss = second_particle;
else
win = second_particle;
loss = first_particle;
end
pop_velocity(loss, :) = rand(1, num_vari) .* pop_velocity(loss, :) + ... % 更新失败的粒子
rand(1, num_vari) .* (pop_position(win, :) - pop_position(loss, :)) + ...
varphi * rand(1, num_vari) .* (mean_pop_position - pop_position(loss, :));
position = pop_position(loss, :) + pop_velocity(loss, :);
position(position > upper_bound) = upper_bound;
position(position < lower_bound) = lower_bound; % 越界检查
pop_position(loss, :) = position;
pop_fitness(loss) = feval(obj_fun,pop_position(loss, :));
end
[best_y, ind] = min(pop_fitness);
best_x = pop_position(ind, :);
best_y_history = [best_y_history; best_y];
%fprintf("CSO generation: %d fmin: %.4f\n", generation, best_y);
generation = generation + 1;
end
end
R 1 ( k , t ) V l , k ( t ) R_{1}(k, t) V_{l, k}(t) R1(k,t)Vl,k(t)类似传统PSO算法中的惯性项,用来保证CSO算法搜索的稳定性; R 2 ( k , t ) ( X w , k ( t ) − X l , k ( t ) ) R_{2}(k, t)(X_{w, k}(t)-X_{l, k}(t)) R2(k,t)(Xw,k(t)−Xl,k(t))是CSO算法的认知部分; φ R 3 ( k , t ) ( X ˉ k ( t ) − X l , k ( t ) ) \varphi R_{3}(k, t)(\bar{X}_{k}(t)-X_{l, k}(t)) φR3(k,t)(Xˉk(t)−Xl,k(t))是CSO算法的社会部分。
CSO算法流程如1.1所示。算法的时间复杂度为 O ( m a x T × m × n ) O(maxT \times m \times n) O(maxT×m×n)。 t < m a x T − 1 t < maxT - 1 t<maxT−1的目的是保证样本总的评估次数维持在 0.5 × m a x T × m 0.5\times maxT \times m 0.5×maxT×m次;随机排序的目的是模拟每次随机取两个粒子。
1.3 勘探能力与开采能力分析
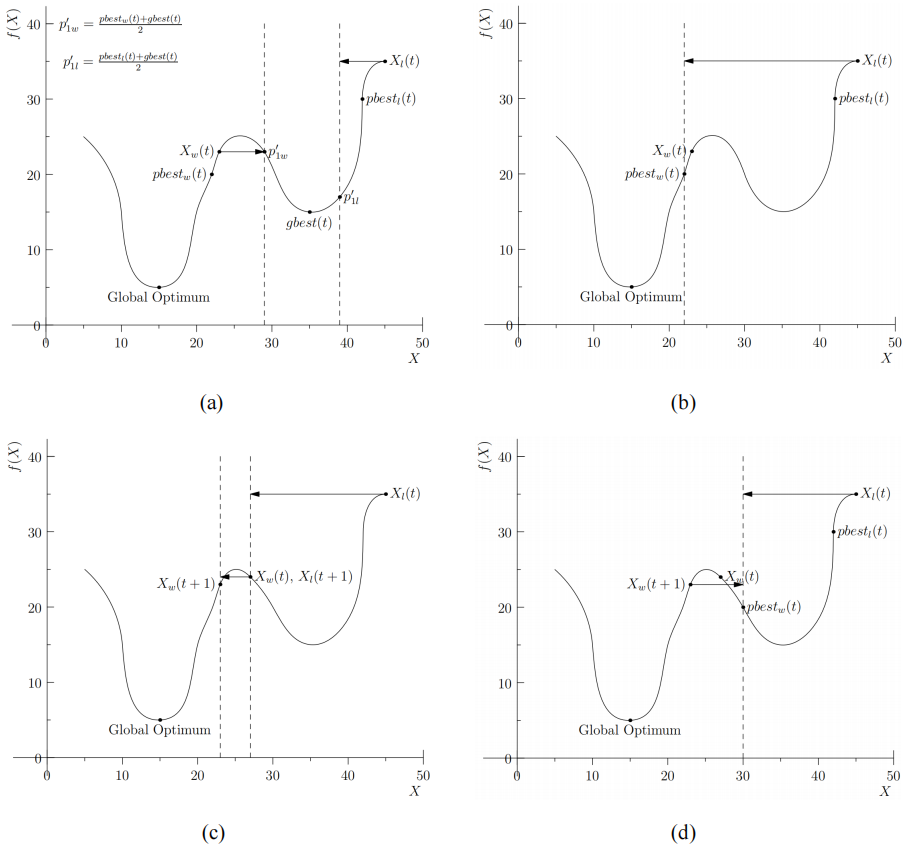
首先分析一下CSO算法的勘探能力,我们将上述公式转换:
V i ( t + 1 ) = R 1 ( k , t ) V i ( t ) + θ 2 ( p 2 − X i ( t ) ) V_{i}(t+1)=R_{1}(k, t)V_{i}(t)+\theta_{2}(p_{2}-X_{i}(t)) Vi(t+1)=R1(k,t)Vi(t)+θ2(p2−Xi(t))
θ 2 = R 2 ( k , t ) + φ R 3 ( k , t ) p 2 = R 2 ( k , t ) R 2 ( k , t ) + φ R 3 ( k , t ) X w ( t ) + φ R 3 ( k , t ) R 2 ( t ) + φ R 3 ( k , t ) X ˉ ( t ) \begin{aligned} \theta_{2} &=R_{2}(k, t)+ \varphi R_{3}(k, t)\\ p_{2} &=\frac{R_{2}(k, t)}{R_{2}(k, t)+\varphi R_{3}(k, t)} X_{w}(t)+\frac{\varphi R_{3}(k, t)}{R_{2}(t)+\varphi R_{3}(k, t)} \bar{X}(t) \end{aligned} θ2p2=R2(k,t)+φR3(k,t)=R2(k,t)+φR3(k,t)R2(k,t)Xw(t)+R2(t)+φR3(k,t)φR3(k,t)Xˉ(t)
CSO算法的种群多样性是高于传统PSO算法的,因为 X w ( t ) X_{w}(t) Xw(t)和 X ˉ ( t ) \bar{X}(t) Xˉ(t)的取值更加地多样。下面展示CSO算法的勘探能力是如何高于传统PSO算法的。
首先看图a, g b e s t ( t ) gbest(t) gbest(t)陷入了局部最优,在传统PSO算法中,两个被选择的粒子均会向 g b e s t ( t ) gbest(t) gbest(t)靠近,这最终使得算法陷入局部最优的陷阱,导致算法优化结果的不佳。现在去掉向 g b e s t ( t ) gbest(t) gbest(t)更新的方式,所有粒子均只向各自的 p b e s t ( t ) pbest(t) pbest(t)更新,如图b。从图可以看出,被选择的粒子会跳出局部最优的陷阱,使得算法的勘探能力得到了提升。但是如果 p b e s t ( t ) pbest(t) pbest(t)也陷入了局部最优,如图c,算法也会陷入局部最优的陷阱,导致算法的勘探能力下降。因此,去掉向 g p b e s t ( t ) gpbest(t) gpbest(t)更新的方式,粒子的更新采用成对粒子竞争更新机制,传统PSO算法也就演变为CSO算法。如图d,由于所有粒子分布在样本空间的不同位置,粒子的更新就变得更加多样化,非常有助于算法脱离局部最优的陷阱,从而使得算法的勘探能力大幅提升。
然后分析一下CSO算法的开采能力。CSO算法的开采阶段是在勘探阶段之后,是在勘探阶段基础上继续小规模地提高算法的优化结果。在传统的PSO算法中,有以下关系:
{ f ( g b e s t ( t ) ) ≤ f ( p b e s t w ( t ) ) ≤ f ( X w ( t ) ) f ( g b e s t ( t ) ) ≤ f ( b e s t l ( t ) ) ≤ f ( X l ( t ) ) \left\{\begin{array}{l} f(gbest(t)) \leq f\left(pbest_{w}(t)\right) \leq f\left(X_{w}(t)\right) \\ f(gbest(t)) \leq f\left(best_{l}(t)\right) \leq f\left(X_{l}(t)\right) \end{array}\right. {f(gbest(t))≤f(pbestw(t))≤f(Xw(t))f(gbest(t))≤f(bestl(t))≤f(Xl(t))
随着迭代过程的继续, t t t越来越大,有:
{ p b e s t w ( t ) ≈ g b e s t ( t ) p b e s t l ( t ) ≈ g b e s t ( t ) \left\{\begin{array}{l} pbest_{w}(t) \approx gbest(t) \\ pbest_{l}(t) \approx gbest(t) \end{array}\right. {pbestw(t)≈gbest(t)pbestl(t)≈gbest(t)
然后令:
Δ F 1 ( t ) = ∣ f ( X l ( t ) ) − f ( g b e s t ) ∣ = ∣ f ( X l ( t ) ) − f ( g b e s t ( t ) + g b e s t ( t ) 2 ) ∣ ≈ ∣ f ( X l ( t ) ) − f ( g b e s t ( t ) + p e s t l ( t ) 2 ) ∣ = ∣ f ( X l ( t ) ) − f ( p 1 ′ ) ∣ Δ F 2 ( t ) = ∣ f ( X l ( t ) ) − f ( X w ( t ) ) ∣ = ∣ f ( X l ( t ) ) − f ( p 2 ′ ) ∣ \begin{aligned} \Delta F_{1}(t) & =\mid f\left(X_{l}(t)\right)-f(gbest) \mid \\ & =\left|f\left(X_{l}(t)\right)-f\left(\frac{gbest(t)+gbest(t)}{2}\right)\right| \\ & \approx\left|f\left(X_{l}(t)\right)-f\left(\frac{gbest(t)+pest_{l}(t)}{2}\right)\right| \\ & =\left|f\left(X_{l}(t)\right)-f\left(p_{1}^{\prime}\right)\right| \\ \Delta F_{2}(t) & =\left|f\left(X_{l}(t)\right)-f\left(X_{w}(t)\right)\right| \\ & =\left|f\left(X_{l}(t)\right)-f\left(p_{2}^{\prime}\right)\right| \end{aligned} ΔF1(t)ΔF2(t)=∣f(Xl(t))−f(gbest)∣= f(Xl(t))−f(2gbest(t)+gbest(t)) ≈ f(Xl(t))−f(2gbest(t)+pestl(t)) =∣f(Xl(t))−f(p1′)∣=∣f(Xl(t))−f(Xw(t))∣=∣f(Xl(t))−f(p2′)∣
其中 p 1 ′ p_{1}^{\prime} p1′是 p 1 p_{1} p1的数学期望, p 2 ′ p_{2}^{\prime} p2′是 p 2 p_{2} p2在 φ = 0 \varphi = 0 φ=0的数学期望。可以得到:
Δ F 2 ( t ) ≤ Δ F 1 ( t ) \Delta F_{2}(t)\leq \Delta F_{1}(t) ΔF2(t)≤ΔF1(t)
与传统PSO算法相比,CSO算法有更好的能力开发与最优粒子相接近的粒子,也就是其开发能力更好,即局部搜索能力更强。此证明过程主要与其勘探过程结合来看。
1.4 算法收敛证明
首先重写之前的公式:
V i ( t + 1 ) = 1 2 V i ( t ) + 1 2 ( X w ( t ) − X i ( t ) ) + φ 1 2 ( X ˉ i ( t ) − X i ( t ) ) X i ( t + 1 ) = X i ( t ) + V i ( t + 1 ) \begin{aligned} V_{i}(t+1) & =\frac{1}{2} V_{i}(t) +\frac{1}{2}(X_{w}(t)-X_{i}(t)) +\varphi \frac{1}{2}(\bar{X}_{i}(t)-X_{i}(t)) \\ X_{i}(t+1) &= X_{i}(t)+V_{i}(t+1) \end{aligned} Vi(t+1)Xi(t+1)=21Vi(t)+21(Xw(t)−Xi(t))+φ21(Xˉi(t)−Xi(t))=Xi(t)+Vi(t+1)
定理一:给定任何 φ ≥ 0 \varphi \ge 0 φ≥0,上述公式可以收敛。
下面来证明这个定理。首先将上述公式进行转换:
V i ( t + 1 ) = 1 2 V i ( t ) + θ ( p − X i ( t ) ) X i ( t + 1 ) = X i ( t ) + V i ( t + 1 ) θ = 1 + φ 2 p = 1 1 + φ X w ( t ) + φ 1 + φ X ˉ ( t ) \begin{aligned} V_{i}(t+1)&=\frac{1}{2} V_{i}(t)+\theta\left(p-X_{i}(t)\right) \\ X_{i}(t+1)&=X_{i}(t)+V_{i}(t+1)\\ \theta&=\frac{1+\varphi}{2} \\ p&=\frac{1}{1+\varphi} X_{w}(t)+\frac{\varphi}{1+\varphi} \bar{X}(t) \end{aligned} Vi(t+1)Xi(t+1)θp=21Vi(t)+θ(p−Xi(t))=Xi(t)+Vi(t+1)=21+φ=1+φ1Xw(t)+1+φφXˉ(t)
将上面两个公式转换为矩阵形式,可得:
y ( t + 1 ) = A y ( t ) + B p y(t+1)=Ay(t)+Bp y(t+1)=Ay(t)+Bp
其中,
y ( t ) = [ V i ( t ) X ( t ) ] , A = [ 1 2 − θ 1 2 1 − θ ] , B = [ θ θ ] y(t)=\left[\begin{array}{l} V_{i}(t) \\ X(t) \end{array}\right], A=\left[\begin{array}{cc} \frac{1}{2} & -\theta \\ \frac{1}{2} & 1-\theta \end{array}\right], B=\left[\begin{array}{l} \theta \\ \theta \end{array}\right] y(t)=[Vi(t)X(t)],A=[2121−θ1−θ],B=[θθ]
其中,在动力系统理论中, A A A称作状态矩阵, p p p称作外部输入, B B B称作输入矩阵。如果根据动力系统理论,上述公式能否收敛取决于状态矩阵 A A A的特征值。首先来求解状态矩阵 A A A的特征值:
λ 2 − ( 3 2 − θ ) λ + 1 2 = 0 \lambda^{2}-\left(\frac{3}{2}-\theta\right) \lambda+\frac{1}{2}=0 λ2−(23−θ)λ+21=0
其特征值为:
{ λ 1 = 3 4 − θ 2 + ( 3 2 − θ ) 2 − 2 2 λ 2 = 3 4 − θ 2 − ( 3 2 − θ ) 2 − 2 2 \left\{\begin{array}{l} \lambda_{1}=\frac{3}{4}-\frac{\theta}{2}+\frac{\sqrt{\left(\frac{3}{2}-\theta\right)^{2}-2}}{2} \\ \lambda_{2}=\frac{3}{4}-\frac{\theta}{2}-\frac{\sqrt{\left(\frac{3}{2}-\theta\right)^{2}-2}}{2} \end{array}\right. ⎩ ⎨ ⎧λ1=43−2θ+2(23−θ)2−2λ2=43−2θ−2(23−θ)2−2
上述公式收敛的充分必要条件为 ∣ λ 1 ∣ < 1 \left | \lambda _{1} \right | < 1 ∣λ1∣<1和 ∣ λ 2 ∣ < 1 \left | \lambda _{2} \right | < 1 ∣λ2∣<1。因此,可以得到:
θ > 0 \theta > 0 θ>0
将 θ \theta θ转换为 φ \varphi φ:
φ > − 1 \varphi > -1 φ>−1
所以,给定任何 φ ≥ 0 \varphi \ge 0 φ≥0,CSO算法可以收敛。
1.5 实验研究
首先来看一下不同种群大小下CSO算法的优化结果,优化结果见表1.1。算法实验的测试函数集为CEC2008,测试函数的维度统一设置为200, φ \varphi φ设置为0,实验的测试函数为 f 1 f_{1} f1、 f 2 f_{2} f2、 f 3 f_{3} f3和 f 6 f_{6} f6,实验的种群数分别为20、40、80、100、 200、400和800,实验总的评估次数为5000 × \times × n,算法运行10次,取10次结果的平均值作为算法最终的优化结果。根据表1.1可以看出,种群数量过大或者过小对CSO算法的优化都有不利的影响。当种群数量过大时,种群收敛速度比较慢,而且算法的迭代次数会减少,导致其优化结果不佳;当种群数量过少时,虽然算法的迭代次数会增加,但种群其收敛速度过快,从而导致算法过早收敛,这也会造成其优化结果不佳。

然后来看一下不同 φ \varphi φ值情况下CSO算法的优化结果。实验设置和前面一致。 φ \varphi φ值越大,算法收敛速度会加快。从表1.2可以看出,当种群数量过大时,如 m = 800 m=800 m=800时,种群收敛速度比较慢,如果增大 φ \varphi φ值,可以加快种群收敛速度,使优化结果变好。

后面在看了领域控制相关的文章后,会探讨一下 X ˉ k ( t ) \bar{X}_{k}(t) Xˉk(t)的全局版本和局部版本对CSO算法的影响。个人绝对局部版本有研究价值,特别是在CSO算法处理高维优化问题时,利用局部版本提高种群多样性将是一个有效的手段。