文章目录
- 几个概念
- 1)监督、无监督、弱监督学习(Weakly Supervised Learning)以及 自监督学习(Self-supervised Learning)
- 2)域偏移、域适应、域泛化
- 3)N-way K-shot(Few-shot learning)
- 4)support set 和 query set
- 5)度量学习
- 一、李宏毅--元学习
- 1) Meta-learning vs Machine-learning
- 2)《Model-agnostic meta-learning for fast adaptation of deep networks》【ICML'2017】
- 二、《Meta-Learning in Neural Networks: A Survey》【TPAMI'2021】
几个概念
1)监督、无监督、弱监督学习(Weakly Supervised Learning)以及 自监督学习(Self-supervised Learning)
根据训练过程中是否有label来监督,机器学习被分为:监督学习和无监督学习。分类问题和回归问题是监督学习的代表,聚类学习是非监督学习的代表。
尽管当前监督学习技术已经取得了巨大的成功,但是由于数据标注过程的成本太高,很多任务很难获得如全部真值标签这样的强监督信息。
因此,延伸出了无监督学习,它的数据集中没有任何的label。此外,自监督学习是一种特殊的无监督学习,它与传统的无监督学习区别如下:
- 自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。简而言之,自监督学习是从数据本身找标签来进行有监督学习。
- 与此不同,无监督学习不依赖任何标签值,没有标签拟合过程。它通过对数据内在特征的挖掘,找到样本间的关系, 从数据分布的角度来构造损失函数。
- 自监督的代表是语言模型,无监督的代表是聚类。
尽管如此,无监督学习由于学习过程太过困难,所以发展缓慢。在自然界中,数据也不可能一个标签没有,一般的情况是存在少数labeled data,和大量的unlabelled data。所以针对这种现实情况,在这两种学习范式之外有没有其他的学习范式?当然有,那就是弱监督学习。
弱监督学习指的是给定的数据有label,但是标签不全或不对。根据给定label的情况,弱监督学习可以分为三种典型的监督类型:不完全监督(Incomplete supervision),不确切监督(Inexact supervision),不精确监督(Inaccurate supervision)。
- 不完全监督:训练数据中只有一部分数据被给了标签,有一些数据是没有标签的。
- 不确切监督:训练数据只给出了粗粒度标签。我们可以把输入想象成一个包,这个包里面有一些示例,我们只知道这个包的标签,Y或N,但是我们不知道每个示例的标签。
- 不精确监督:给出的标签不总是正确的,比如本来应该是Y的标签被错误标记成了N。
用西瓜来举例,这三种弱监督情况如下所示:

针对这三种典型的弱监督情况,分别使用不同的技术去解决,如下图所示:

- 解决不完全监督:主动学习和半监督学习。一种是有人类(oracle,业务专家)干预的,一种是没有人类干预的。
- 解决不确切监督:多示例学习。
- 解决不精确监督:带噪学习。
重点讲一下半监督学习。在不完全监督情况下,我们已知少量带标签的数据,比如一个数据是positive,另一个数据是negative,和大量未标注数据。现在在两个label data正中间有一个test data,如果只根据这两个labeled data,我们是很难去判断这个test data到底是positive 还是negative的。但是如果我们被允许去观察一些unlabeled data的分布,观察到的结果如下图右边部分的灰点,这时我们就可以较肯定的认为test data是positive。这种半监督学习的方式有些类似于聚类。

参考:浅谈弱监督学习(Weakly Supervised Learning)、《A Brief Introduction to Weakly Supervised Learning》
2)域偏移、域适应、域泛化
在机器学习中,“域(domain)”通常指的是在训练或测试机器学习模型期间遇到的特定数据分布(distribution)。我们称训练集所在的域叫做Source Domain(源域),测试集所在的域叫做Target Domain(目标域)。以图像分类为例,不同的域可能对应不同类型的图像,例如照片、素描或卡通。
Domain shift/gap(域偏移/域间隙,DS) 指的是Source Domain和Target Domain的分布存在差异,导致Source Domain上训练的模型在Target Domain中性能下降的问题。解决域偏移是机器学习的一个重要问题,因为模型需要在new或unseen的数据上良好的执行。
域适应 (Domain Adaptation,DA) 和域泛化 (Domain Generalization,DG) 是解决域偏移问题的两种方法。
域适应可以看作是 transfer learning的变体,对于一个source-trained model,DA希望使用来自Target Domain的 sparse(少量带标签) 或 unlabelled data来修正或微调这个模型。这个微调的过程叫做Adaptation,相当于对在Source Domain上已经训练好的模型,使用Target Domain中的一些数据进行modify(or, finetuning),从而使模型能够适应新的领域,克服DS问题。
域泛化指的是在Source Domain上训练的模型足够鲁棒,以至于面对一个新的domain,无需adaption就可以实现良好的性能。
**总之, DA 和 DG 都旨在解决机器学习中的域偏移问题,但它们的区别是DG无需Adaption就可以实现良好的性能。**在实现DA或DG的过程中,可以用监督学习、无监督学习或弱监督学习。
此外,根据data的标注情况,DA还分为以下几种:(就是Adaption时数据的标注情况)
- Unsupervised Domain Adaptation(UDA)
- 在这种setting下,我们可以获取到目标域的数据,但是不能获取到对应的标签,即使用有标签的源域数据和无标签的目标域数据进行训练。
- Semi-supervised Domain Adaptation
- 由于UDA的性能较差,也不符合实际的应用。在实际的应用中,目标域不会完全的没有标注,一般会有少量的标注。在SSDA的setting下,训练时可以获取到少量的目标域标签,常见的是每个类别获取3或5个标签。
- Universal Domain Adaptation
- Source-Free Domain Adaptation
- 在上面的setting中,训练过程是可以访问到源域数据的。但是在实际情况中,由于隐私原因(医疗数据不能公开)或者数据传输问题(数据集非常大,下表),我们并不能获取到源域数据,而只能获取到源域所训练好的模型。这个setting的目的就是只利用源模型来完成domain adaptation。
3)N-way K-shot(Few-shot learning)
N-way K-shot是few-shot learning中常见的实验设置。N-way指训练数据中有N个类别,K-shot指每个类别下有K个被标记数据。
人类非常擅长通过极少量的样本识别一个新物体,比如小孩子只需要书中的一些图片就可以认识什么是“斑马”,什么是“犀牛”。在人类的快速学习能力的启发下,研究人员希望机器学习模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,这就是 Few-shot Learning 要解决的问题。
小样本学习的方法包括迁移学习、元学习、数据增强、半监督学习、主动学习等,这些方法可以降低模型对数据量的依赖,提高泛化性能,使得模型在处理长尾数据时具有更好的鲁棒性。(Few-shot Learning 是 Meta Learning 在监督学习领域的应用。)
长尾分布通常指由一个小部分高频数据和一个大部分低频数据组成的概率分布。在许多真实世界的数据集中,都存在大量的长尾分布数据。小样本学习是处理长尾数据的有效方法。
参考:小样本学习(Few-shot Learning)综述
4)support set 和 query set
在meta leanring中,一个task包含support set和query set,为N-way K-shot。同时task分为traning task和testing task。Tranining task是用来训练模型的,testing task用来测试。无论traning task还是testing task,其组成是一致的。
5)度量学习
度量学习是指在机器学习中,通过学习一个映射函数,将输入的数据映射到一个特征空间,并在该特征空间中定义一个距离函数来度量数据点之间的相似性或距离。度量学习一般适用于无监督学习或半监督学习中,通常通过度量相似性来解决聚类、分类、回归等问题。
度量学习的主要目的是通过学习合适的距离或相似度函数,使得同类样本更加接近,异类样本更加分散。在很多应用中,如人脸识别、图像检索、推荐系统等,度量学习都能够取得很好的效果。
常见的度量学习方法包括最近邻(KNN)、局部线性嵌入学习(LLE)、流形学习(Manifold Learning)、对比学习(Contrastive Learning)、三元组损失(Triplet Loss)等。在实际应用中,如何选择适合问题的度量学习算法以及调整度量学习算法的参数,是一个关键的问题。
一、李宏毅–元学习
1) Meta-learning vs Machine-learning
先回顾机器学习,它可以分为三个步骤: 先定义一个参数未知的function,然后定义一个关于θ的loss function, 最后要做的就是优化,找一个
θ
∗
\theta^*
θ∗使得
L
(
θ
)
L(\theta)
L(θ)越小越好。


回顾了machine-learning的步骤之后,再来理解 meta-learning。因为整体上,meta-learning与machine-learning的框架很相似,都可以分为“定义函数、设计损失、进行优化”这三步。
那Meta-learning要做的是什么呢? 学习如何学习。meta-learning要做的就是学习“如何学习”这个过程,它手工定义了一个函数
F
F
F(其实就是一个学习算法),这个函数表示的意思就是"如何学习"这个过程,所以它的输入是训练资料,输出是机器学习中的预测函数
f
f
f。

因此,在meta-learning中,我们要做的就是学习一个“学习算法F”,它的输入是data,输出是预测函数 f ,最后再用输出函数 f 做预测。就是说我们的学习目标从“预测函数 f ”转换为了“学习算法F”。
做了这样的定义后,就相当于机器学习的第一个步骤“定义参数未知的函数”。定义好函数后,那接下来要做的就是为这个函数定义一个损失函数,进一步的再优化。
那在这个“学习算法F”中,有什么东西是需要学习的呢?它们可以是:网络架构、初始化参数、学习率等,被统称为learnable components。 其实,不同类别的meta-learning方法,就是学习不同的learnable components。

虽然meta-learning与machine-learning的宏观架构相同,但是在训练细节上仍有区别。machine-learning的数据集是一批data,被分为training data,testing data。与此不同,meta-learning是task-level,它的整个数据集是一批tasks,进一步地被分为training tasks,testing tasks。每个task中都包含了一批data,被分为train set和test set,为了避免歧义,我们一般称为 support set 和 query set。
为什么要这么做?是因为我们要去评判训练后的学习算法
F
ϕ
F_\phi
Fϕ的效果是好是坏,需要拿学习到的预测函数
f
f
f的预测效果来间接性衡量,
f
f
f的预测效果好,就证明学习算法
F
ϕ
F_\phi
Fϕ的效果好,
f
f
f的预测效果差,就证明学习算法
F
ϕ
F_\phi
Fϕ的效果差。为了衡量学习算法
F
ϕ
F_\phi
Fϕ,也就是定义loss function,我们在meta-learning的训练数据中,也要有供学习
F
ϕ
F_\phi
Fϕ的training examples,和供测试学到函数
f
f
f效果的testing examples,所以才将整个数据集划分成这样。


此外,以分类问题而言,Meta-learning的目的是不仅学会水果的分类,还要学会其他的分类,比如车子的分类,总的来讲就是Meta-learning要学会如何得到分类器这件事。因此在同一个task domain下,需要使Meta-learning在该task domain上的很多任务上训练,这样才能使Meta-learning在任何物体上都能实现分类,所以Meta-learning的训练样本是各种任务的分类,这也是为什么说Meta-learning是task-level。

定义好函数,设计好loss之后,剩下的就是优化了。假设上述的损失函数对
ϕ
\phi
ϕ可微分,则可以用梯度下降来优化,如果不可微分,则可以用强化学习或演化算法等来优化。总之,对上述损失函数进行优化后,就可以得到一个学习算法
F
ϕ
F_\phi
Fϕ。
到此,Meta-learning的整体框架总结如下:

从这里其实就能看出,few-shot learning是meta-learning的应用,两者还是有着微妙的区别。few-shot learning有点像我们要实现的目标,只需要一点样本的监督,就可以让模型有不错的性能。而meta-learning是学习如何学习这件事,训练完后的meta-learning在testing task上,给定一点点labeled data来训练,就可以在test data上有不错的性能,这样算是实现了few-shot learning。或者说,few-shot learning的algorithm,可以用meta-learning得到。
讲了这么多,meta-learning与machine-learning的区别到底是什么?
- 从task角度而言,machine-learning是within-task training,meta-learning是across-task training。在meta-learning的train里面,包含了一次within-task training,和一次within-task testing,这称之为一次episode。


在以MAML为主的 “learning to initialize” 文献中,称 across-task training 为 outer loop,称 within-task training 为 inner loop。

2)《Model-agnostic meta-learning for fast adaptation of deep networks》【ICML’2017】
了解完meta-learning后,我们知道它可以用来学习很多东西, 但用的比较多的 meta-learning 方式是 “learning to initialize” ,就是用 meta-learning 来学习一个比较好的初始化参数,因为我们知道初始化参数对模型的影响是较大的。好的初始参数能够提高模型收敛速度,并且更加接近最优解;而不好的初始参数会导致梯度传播异常,降低训练速度,影响训练效果。这类工作中,最有代表性的就是本篇文章,简称MAML(此外还有一个MAML的变体,叫Reptile)。
MAML其实与Self-supervised learning异曲同工,他们的目标都是寻找一个好的初始化参数,他们其实都是为了 fast adaptation。MAML的核心思想是:通过少量的数据寻找一个合适的初始值范围,使得模型能够在有限的数据集上快速拟合,并获得一个不错的效果。这个方法的优点在于,无论是什么样的损失函数,无论是什么样的网络结构,都可以轻松实现适配,所以MAML更像是一个基于元学习的预训练框架。
MAML的伪代码如下:

首先看两个Require:
- 第一个Require的意思是,从任务池中构造训练集。
- 第二个Require的意思是,设置两个学习率(step size)。为什么要设置两个学习率?因为MAML论文中有个词叫gradient by gradient,它的意思就是MAML是基于二重梯度的,也就说MAML在每次迭代过程中涉及到两次参数更新,一次来自于外循环,一次来自于内循环。
再来看算法的每一步:
- 第一步,随机初始化模型的参数
- 第二步,设置循环
- 第三步,从训练任务池中随机抽取出若干个task,形成一个batch。相当于pytorch中的DataLoader。
- 第四-七步,对“学习算法F”进行训练,因为是在batch内的不同task之间训练的,所以这一步叫做外循环,outer loop。具体的是,对于batch内的每一个task,在对应的support set内分别进行参数更新。在每一个task内,support set都是N-way K-shot,也就是有N个类别,每个类别有K个样本,如果是回归问题,loss就是MSE,对每一个样本做MSE计算loss并更新梯度。
- 第八步:进行内循环的参数更新。这里与上一步有两个不同:① 一处是我们不再是分别利用每个task的loss更新梯度,而是像常见的模型训练过程一样,计算一个batch的loss总和,对梯度进行随机梯度下降SGD。② 另一处是这里参与计算的样本,是task中的query set,目的是增强模型在task上的泛化能力,避免过拟合support set。步骤8结束后,模型结束在该batch中的训练,开始回到步骤3,继续采样下一个batch。
MAML真正好在哪里?ICLR‘2020有篇文章对其进行了解释《Rapid learning or feature reuse? towards understanding the effectiveness of maml》,结果是好在了Feature reused上。

除了像MAML一样学习初始化,meta-learning还可以学习网络结构、优化器等,这些不在这里展开。
参考:(强推)李宏毅2021/2022春机器学习课程,Model-Agnostic Meta-Learning (MAML)模型介绍及算法详解
二、《Meta-Learning in Neural Networks: A Survey》【TPAMI’2021】
多任务学习与元学习的区别:
- The mutil-task learning problem: learn all of the tasks more quickly or more proficirntly than learning them independtly. 对所有的任务一起学习,相对于单独学习每个任务更快且更有效。
- The meta-learning problem: Given data/experience on previous tasks, learn a new task more quickly and/or more proficiently. 在之前的相关任务上训练过,对于新的任务可以更快地学习。
Meta Learning,也称为Learning to Learn,即学会学习,它的目的就是学会某种学习的技巧,从而在新的任务task上可以学的又快又好。这种学习的技巧我们可以称为Meta-knowledge。
- Meta Learning是Task Level的;
- Meta Learning优化思想是:BiLevel Optimization。即两层优化过程,在inner-loop(内层)中使用train set更新model,然后在outer-loop(外层)基于更新后的model优化meta knowledge。
Meta learning是一个通用性的方法论,可以对几乎任意的可调整参数进行meta learning。在这篇综述中作者对Meta Learning按照是什么(What,Meta-Representation),怎么做(How,Meta-Optimizer),**为什么(Why, Objective)**来分类。
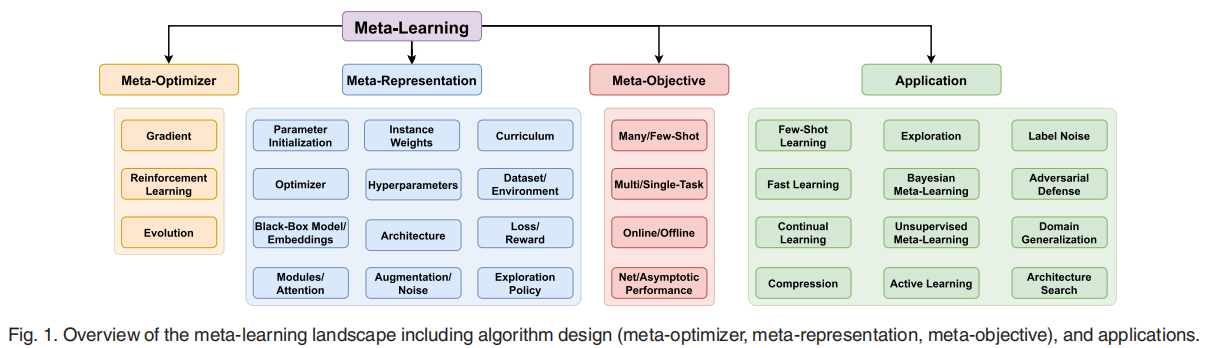
- Meta-Representation:即 meta 要 learn 的东西,可以是整个model,也可以是超参,网络结构,loss,data等等,常用的就是MAML类的Parameter Initialization。
- Meta-Optimizer:主要指Bilevel-Optimization中的Outer-loop采用的优化方式,这个跟李宏毅讲的一样有三种:Gradient,RL及Evolution,根据需要选用。
- Meta-Objective:即Meta Learning的具体目标,不同的应用会有不同的目标。
Meta learning的第一大应用就是few-shot learning(FSL)了。FSL是一个挑战性的任务,数据量通常是影响性能的主要因素,用小数据集训练大模型会导致过拟合或不收敛。
分类:Meta learning最常见的应用就是few-shot multi-class image recognition,其中内、外loss一般是在训练、验证集上的cross-entropy。在这类工作中,Optimizer-centric, black-box, 和metric learning模型也有涉及到。与早期的方法相比,这一类工作已经导致了性能的稳步提高,但性能仍然远远落后于完全监督的方法,所以还有更多的工作要做。目前的研究问题包括改进跨域泛化,在由元元素和元测试类定义的联合标签空间内的识别,以及增量添加新的少镜头类。
除了分类外,应用Meta learning的FSL应用还有:关键点预测、目标检测、目标分割、行为识别、图像和视频生成。
参考:荐读 Meta-Learning in Neural Networks: A survey