Python分别用单线程,多线程,异步协程爬取一部小说,最快仅需要5s
Python异步爬虫之协程抓取妹子图片(aiohttp、aiofiles)
Python爬虫——教你异步爬虫二十秒爬完两百多万字六百多章的小说
python爬虫-异步爬虫
用python批量把小说编号由大写数字替换成阿拉伯数字
1 同步与异步
1.1 同步
同步是有序,为了完成某个任务,在执行的过程中,按照顺序一步一步执行下去,直到任务完成。
爬虫是IO密集型任务,我们使用requests请求库来爬取某个站点时,网络顺畅无阻塞的时候,正常情况如下图所示:
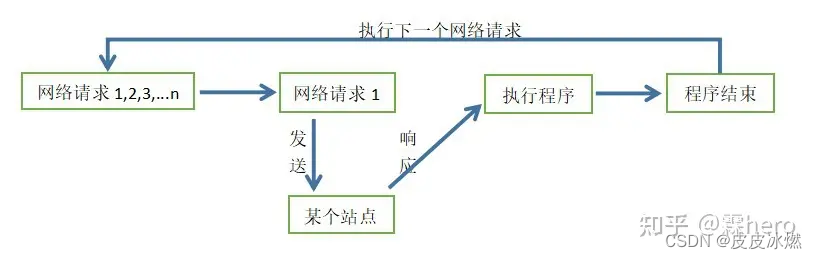
但在网络请求返回数据之前,程序是处于阻塞状态的,程序在等待某个操作完成期间,自身无法继续干别的事情,如下图所示:

当然阻塞可以发生在站点响应后的执行程序那里,执行程序可能是下载程序,下载是需要时间的。当站点没响应或者程序卡在下载程序的时候,CPU一直在等待而不去执行其他程序,那么就白白浪费了CPU的资源,导致我们的爬虫效率很低。
1.2 异步
异步是一种比多线程高效得多的并发模型,是无序的,为了完成某个任务,在执行的过程中,不同程序单元之间过程中无需通信协调,也能完成任务的方式,也就是说不相关的程序单元之间可以是异步的。如下图所示:
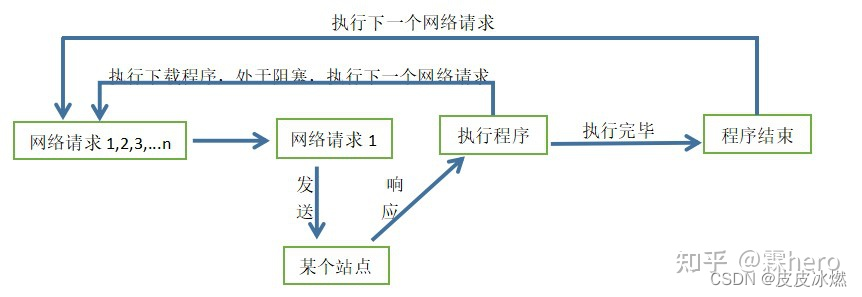
当请求程序发送网络请求1并收到某个站点的响应后,开始执行程序中的下载程序,由于下载需要时间或者其他原因使处于阻塞状态,请求程序和下载程序是不相关的程序单元,所以请求程序发送下一个网络请求,也就是异步。
(1)微观上异步协程是一个任务一个任务的进行切换,切换条件一般就是IO操作;
(2)宏观上异步协程是多个任务一起在执行;
注意:上面我们所讲的一切都是在单线程的条件下实现。
1.3 协程
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程 。最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是用户执行)。
优势就是性能得到了很大的提升,不会像线程切换那样消耗资源。协程的开销远远小于线程的开销。协程本质是单线程,在不占用更多系统资源的情况下,将IO操作进行了挂起,然后继续执行其他任务,等待IO操作完成之后,再返回原来的任务继续执行。
2 协程
import requests #同步的网络请求模块
import re #正则模块,用于提取数据
import asyncio #创建并管理事件循环的模块
import aiofiles #可异步的文件操作模块
import aiohttp #可异步的网络请求模块
import os #可调用操作系统的模块
2.1 协程库asyncio
从asyncio模块中直接获取一个EventLoop的引用,把需要执行的协程放在EventLoop中执行,这就实现了异步协程。协程通过async语法进行声明为异步协程方法,await语法进行声明为异步协程可等待对象,是编写asyncio应用的推荐方式。
(1)event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事情循环上,当满足发生条件时,就调用对应的处理方法。
(2)coroutine:中文翻译叫协程,在Python中常指代协程对象类型,我们可以将协程对象注册到时间循环中,它会被事件训话调用。我们可以使用async关键字来定义一个方法,这个方法在调用时不会立即被执行,而是会返回一个协程对象。
(3)task:任务,这是对协程对象的进一步封装,包含协程对象的各个状态。
(4)future:代表将来执行或者没有执行的任务的结果,实际上和task没有本质区别。
2.1.1 定义协程
# -*- coding: utf-8 -*-
import asyncio
# async定义的方法会变成一个无法直接执行的协程对象,
# 必须将此对象注册到事件循环中才可以执行。
async def execute(x):
print('Number:', x)
coroutine = execute(1)
# 此时直接调用async定义的方法,返回的只是一个协程对象
print('Coroutine:', coroutine)
print('after execute')
# 使用get_event_loop()方法创建一个事件循环loop,
# 并调用loop对象的run_until_complete方法将协程对象注册到了事件循环中,才会触发定义的方法。
loop = asyncio.get_event_loop()
loop.run_until_complete(coroutine)
print('after loop')

2.1.2 定义任务
# -*- coding: utf-8 -*-
import asyncio
# (1)async定义的方法会变成一个无法直接执行的协程对象
async def execute(x):
print('Number:', x)
return x
coroutine = execute(555)
# (2)使用get_event_loop()方法创建一个事件循环loop
loop = asyncio.get_event_loop()
# (3)将协程对象转化为task任务,此时的任务还是pending状态
# (3-1)方式一
task = loop.create_task(coroutine)
# (3-2)方式二
# task = asyncio.ensure_future(coroutine)
print('Task:', task)
# (4)将task任务注册到事件循环中,然后task状态变为了finished,
# result=555是execute()执行的结果
loop.run_until_complete(task)
print('Task:', task)
print('after loop')

2.1.3 多任务协程
执行多次请求,可以定义一个task列表,然后使用asyncio包中的wait方法执行。
# -*- coding: utf-8 -*-
# @Time : 2023/5/12 15:48
# @Author : zb
# @File : xieCheng.py
# @Project : 爬虫
import asyncio
# (1)async定义的方法会变成一个无法直接执行的协程对象
async def execute(x):
print('Number:', x)
return x
# (2)创建task任务列表
tasks = []
for i in range(3):
tasks.append(asyncio.ensure_future(execute(i)))
# (3)使用get_event_loop()方法创建一个事件循环loop
loop = asyncio.get_event_loop()
# (4)将task任务注册到事件循环中
loop.run_until_complete(asyncio.wait(tasks))
for task in tasks:
print('Task Result:', task.result())
2.2 HTTP框架aiohttp
aiohttp是基于asyncio实现的HTTP框架,用于HTTP服务器和客户端。
# -*- coding: utf-8 -*-
import aiohttp
import asyncio
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
async def Main():
async with aiohttp.ClientSession() as session:
async with session.get('https://www.baidu.com',headers=headers) as response:
html = await response.text()
print(html)
loop = asyncio.get_event_loop()
loop.run_until_complete(Main())
其实aiohttp.ClientSession() as session相当于将requests赋给session,也就是说session相当于requests,而发送网络请求、传入的参数、返回响应内容都和requests请求库大同小异,只是aiohttp请求库需要用async和await进行声明,然后调用asyncio.get_event_loop()方法进入事件循环,再调用loop.run_until_complete(Main())方法运行事件循环,直到Main方法运行结束。
3 下载速度对比
分别运用了单线程爬取,多线程爬取和异步协程爬取。
小说地址http://www.doupo321.com/doupocangqiong/。
步骤就是先爬取到网页下的子链接,然后通过子链接爬取到每章小说内容。
3.1 单线程
# -*- coding: utf-8 -*-
import time
import requests
from lxml import etree
def download(url, title): # 下载内容
resp = requests.get(url)
resp.encoding = 'utf-8'
html = resp.text
tree = etree.HTML(html)
body = tree.xpath("/html/body/div/div/div[4]/p/text()")
body = '\n'.join(body)
with open(f'斗破2/{title}.txt', mode='a+', encoding='utf-8') as fw:
fw.write(body)
def geturl(url): # 获取子链接
resp = requests.get(url)
resp.encoding = 'utf-8'
html = resp.text
tree = etree.HTML(html)
lis = tree.xpath("/html/body/div[1]/div[2]/div[1]/div[3]/div[2]/ul/li")
print("总共{}章".format(len(lis)))
for li in lis:
href = li.xpath("./a/@href")[0].strip('//')
href = "http://"+href
title = li.xpath("./a/text()")[0]
download(href, title)
print(title)
if __name__ == '__main__':
url1 = "http://www.doupo321.com/doupocangqiong/"
st = time.time()
geturl(url1)
ed = time.time()
print("耗时:", ed-st)
大约花费了30min。

3.2 多线程
# -*- coding: utf-8 -*-
import time
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
def download(url, title):
resp = requests.get(url)
resp.encoding = 'utf-8'
html = resp.text
tree = etree.HTML(html)
body = tree.xpath("/html/body/div/div/div[4]/p/text()")
body = '\n'.join(body)
with open(f'斗破1/{title}.txt', mode='w', encoding='utf-8')as fw:
fw.write(body)
def geturl(url):
# 获取每一章的链接
resp = requests.get(url)
resp.encoding = 'utf-8'
html = resp.text
tree = etree.HTML(html)
lis1 = tree.xpath("/html/body/div[1]/div[2]/div[1]/div[3]/div[2]/ul/li")
print("总共{}章".format(len(lis1)))
return lis1
if __name__ == '__main__':
url1 = "http://www.doupo321.com/doupocangqiong/"
st = time.time()
lis = geturl(url1)
with ThreadPoolExecutor(1000) as t: # 创建线程池,最多有1000个线程
for li in lis:
href = li.xpath("./a/@href")[0].strip('//')
href = "http://" + href
title = li.xpath("./a/text()")[0]
t.submit(download, url=href, title=title)
print(title)
ed = time.time()
print("耗时:", ed-st)
仅耗时22秒。

3.3 异步协程
安装依赖库pip install aiohttp
安装依赖库pip install aiofiles
# -*- coding: utf-8 -*-
import requests
import aiohttp
import asyncio
import aiofiles
from lxml import etree
import time
async def download(url,title,session):
async with session.get(url) as resp: # resp = requests.get()
html = await resp.text()
tree = etree.HTML(html)
body = tree.xpath("/html/body/div/div/div[4]/p/text()")
body = '\n'.join(body)
async with aiofiles.open(f'斗破/{title}.txt', mode='w', encoding='utf-8')as f: # 保存下载内容
await f.write(body)
async def geturl(url):
resp = requests.get(url)
resp.encoding = 'utf-8'
html = resp.text
tree = etree.HTML(html)
lis = tree.xpath("/html/body/div[1]/div[2]/div[1]/div[3]/div[2]/ul/li")
print("总共{}章".format(len(lis)))
tasks = []
async with aiohttp.ClientSession() as session: # request
for li in lis:
href = li.xpath("./a/@href")[0].strip('//')
href = "http://"+href
title = li.xpath("./a/text()")[0]
print(title)
# 插入异步操作
tasks.append(asyncio.ensure_future(download(href, title, session)))
await asyncio.wait(tasks)
if __name__ == '__main__':
url1 = "http://www.doupo321.com/doupocangqiong/"
st = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(geturl(url1))
ed = time.time()
print("耗时:", ed-st)
大约需要32秒

可以看出,用多线程,仅仅22秒就扒完了一部1600多章的小说,但是多线程会对系统的开销较大;如果用异步协程,爬取速度会稍微慢些,需要大概32秒,但是对系统开销较小,建议大家采用异步协程的方式,但是用单线程去爬取会慢很多,扒完一部小说耗时需要30min,不是很推荐。
拿到的小说是乱序的,后期想办法解决。
4 大写数字替换成阿拉伯数字
# -*- coding: utf-8 -*-
import re
pattern = re.compile(u'第(.*)章')
mulu = u'''第一千五百四十六章 道韵高低'''
# constants for chinese_to_arabic
# 中文对应阿拉伯数字
CN_NUM = {
'〇': 0, '一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '零': 0,
'壹': 1, '贰': 2, '叁': 3, '肆': 4, '伍': 5, '陆': 6, '柒': 7, '捌': 8, '玖': 9, '貮': 2, '两': 2,
}
# 中文对应单位
CN_UNIT = {
'十': 10,
'拾': 10,
'百': 100,
'佰': 100,
'千': 1000,
'仟': 1000,
'万': 10000,
'萬': 10000,
'亿': 100000000,
'億': 100000000,
'兆': 1000000000000,
}
def chinese_to_arabic(cn):
print(cn)
unit = 0 # current
ldig = [] # digest
for cndig in reversed(cn):
print(cndig)
if cndig in CN_UNIT:
unit = CN_UNIT.get(cndig)
if unit == 10000 or unit == 100000000:
ldig.append(unit)
unit = 1
else:
dig = CN_NUM.get(cndig)
if unit:
dig *= unit
unit = 0
ldig.append(dig)
if unit == 10:
ldig.append(10)
val, tmp = 0, 0
for x in reversed(ldig):
if x == 10000 or x == 100000000:
val += tmp * x
tmp = 0
else:
tmp += x
val += tmp
return val
print(pattern.findall(mulu))