学习bert可以下载一些数据集练练手,目前打算选择官网给出GLUE的数据集。
bert整体代码框架结构如下:
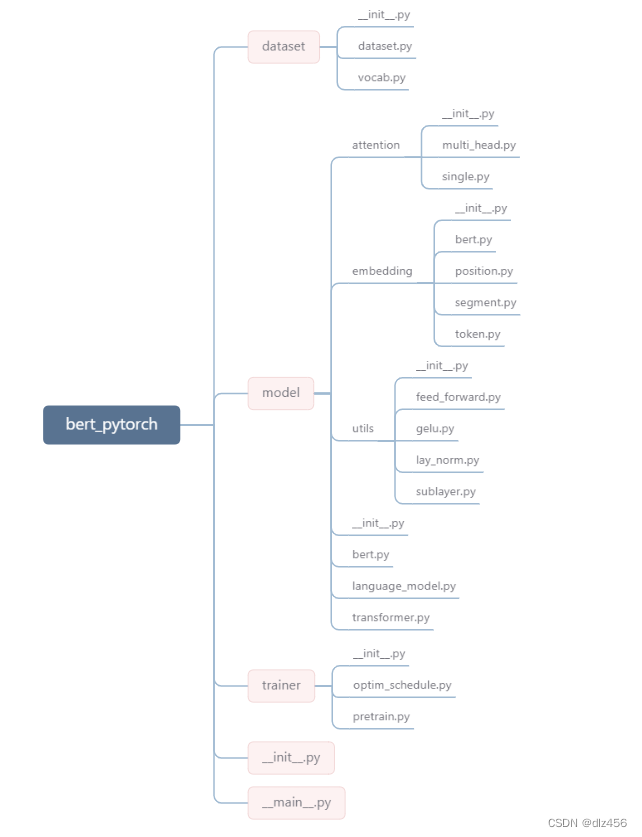
首先从main文件开始解读,打开__main__.py。这里面只有import导入语句和一个train函数。
train函数里面首先是对一些路径参数的填写:
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--train_dataset", required=True, type=str, help="train dataset for train bert")
parser.add_argument("-t", "--test_dataset", type=str, default=None, help="test set for evaluate train set")
parser.add_argument("-v", "--vocab_path", required=True, type=str, help="built vocab model path with bert-vocab")
parser.add_argument("-o", "--output_path", required=True, type=str, help="ex)output/bert.model")
其中train_dataset和test_dataset是自己选择的任务的训练数据和测试数据,一般呈之为corpus(语料库)。vocab_path指的是vocabulary库(词汇表库),相当于一个大字典,记录了所有可能出现的单词。语料库中的单词转为id的时候需要在这个大字典(vocabulary库)中去找。
注意:这个vocab.txt可以在huggingface上去找。
中间还有一些路径的参数(暂时跳过)
接下来代码如下:
print("Loading Vocab", args.vocab_path)
vocab = WordVocab.load_vocab(args.vocab_path)
print("Vocab Size: ", len(vocab))
这里就是加载单词表那个数据,从txt格式加载成python对象。
中间的WordVocab.load_vocab具体代码就是:
@staticmethod
def load_vocab(vocab_path: str) -> 'WordVocab':
with open(vocab_path, "rb") as f:
return pickle.load(f)
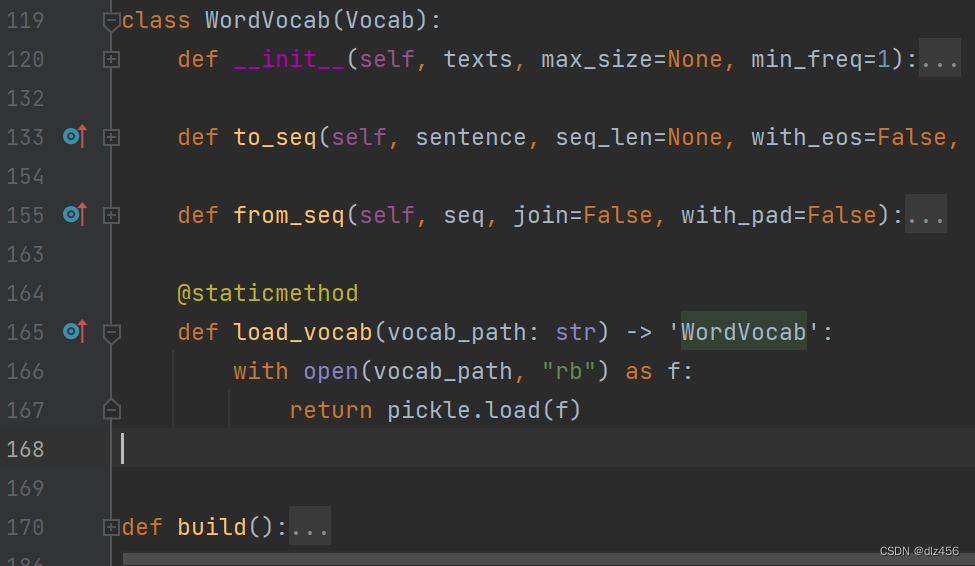
这部分代码是放在dataset里面的vocab.py里面的。
其中:
- 关于@staticmethod:Python面向对象编程中,@staticmethod 装饰的是静态方法。静态方法就是不实例化类的情况下可以直接访问该方法。该方法有两个特点:一是不需要约定的默认参数self。二是静态方法就是类对外部函数的封装,有助于优化代码结构和提高程序的可读性。
- 这个“ -> ‘WordVocab’ ”就是函数注解的一部分,表示希望的返回值的类型是什么。
- 然后就是open函数,rb参数表示以二进制格式打开一个文件用于只读。
- 打开vocab_path路径下的文件,然后借助pickle模块的pickle.load(file)函数加载,这个函数就是从文件中读取,并反序列化。那么什么是序列化和反序列化呢?序列化:把对象转换为字节序列的过程称为对象的序列化。反序列化:把字节序列恢复为对象的过程称为对象的反序列化。也就是说,把项目中的数据写入,变成文件保存本地就是序列化。反序列化就是把文件中一连串的字节转为一个对象放入内存里(其实就是文件读取的过程)。
然后继续返回到main文件中,下面的代码就是
print("Loading Train Dataset", args.train_dataset)
train_dataset = BERTDataset(args.train_dataset, vocab, seq_len=args.seq_len, corpus_lines=args.corpus_lines, on_memory=args.on_memory)
这个就是加载训练数据的过程。
更新中。。。。