文章目录
- 1. torch_geometric.data介绍
- 2. 使用Planetoid下载Cora数据集的代码
- 3. 解决程序运行的机器无法联网的问题
- 3.1 尝试运行,查看数据集下载链接
- 3.2 放置到对应文件夹下
- 3.3 重新运行之前写的程序
- 4. 一点感慨
1. torch_geometric.data介绍
torch_geometric,简称pyg,是基于pytorch实现的图神经网络库。本文暂时不讲图神经网络的搭建,先介绍一下如何基于这个库获取官方已经集成的数据集。
torch_geometric.datasets这个子包下包含这些类,每个类可以用于下载一个或者几个相关的数据集:
datasets.AMiner( datasets.PascalPF( datasets.gemsec
datasets.AQSOL( datasets.PascalVOCKeypoints( datasets.geometry
datasets.Actor( datasets.Planetoid( datasets.github
datasets.AirfRANS( datasets.PolBlogs( datasets.gnn_benchmark_dataset
datasets.Airports( datasets.QM7b( datasets.graph_generator
datasets.Amazon( datasets.QM9( datasets.heterophilous_graph_dataset
datasets.AmazonProducts( datasets.RandomPartitionGraphDataset( datasets.hgb_dataset
datasets.AttributedGraphDataset( datasets.Reddit( datasets.hydro_net
datasets.BA2MotifDataset( datasets.Reddit2( datasets.icews
datasets.BAMultiShapesDataset( datasets.RelLinkPredDataset( datasets.imdb
datasets.BAShapes( datasets.S3DIS( datasets.infection_dataset
datasets.BitcoinOTC( datasets.SHREC2016( datasets.jodie
datasets.CitationFull( datasets.SNAPDataset( datasets.karate
datasets.CoMA( datasets.ShapeNet( datasets.last_fm
datasets.Coauthor( datasets.StochasticBlockModelDataset( datasets.lastfm_asia
datasets.CoraFull( datasets.SuiteSparseMatrixCollection( datasets.linkx_dataset
datasets.DBLP( datasets.TOSCA( datasets.lrgb
datasets.DBP15K( datasets.TUDataset( datasets.malnet_tiny
datasets.DGraphFin( datasets.Taobao( datasets.md17
datasets.DeezerEurope( datasets.Twitch( datasets.mixhop_synthetic_dataset
datasets.DynamicFAUST( datasets.UPFD( datasets.mnist_superpixels
datasets.EllipticBitcoinDataset( datasets.WILLOWObjectClass( datasets.modelnet
datasets.EmailEUCore( datasets.WebKB( datasets.molecule_net
datasets.Entities( datasets.WikiCS( datasets.motif_generator
datasets.ExplainerDataset( datasets.WikipediaNetwork( datasets.movie_lens
datasets.FAUST( datasets.WordNet18( datasets.nell
datasets.FB15k_237( datasets.WordNet18RR( datasets.ogb_mag
datasets.FacebookPagePage( datasets.Yelp( datasets.omdb
datasets.FakeDataset( datasets.ZINC( datasets.pascal
datasets.FakeHeteroDataset( datasets.actor datasets.pascal_pf
datasets.Flickr( datasets.airfrans datasets.pcpnet_dataset
datasets.GDELT( datasets.airports datasets.planetoid
datasets.GEDDataset( datasets.amazon datasets.polblogs
datasets.GNNBenchmarkDataset( datasets.amazon_products datasets.ppi
datasets.GemsecDeezer( datasets.aminer datasets.qm7
datasets.GeometricShapes( datasets.aqsol datasets.qm9
datasets.GitHub( datasets.attributed_graph_dataset datasets.reddit
datasets.HGBDataset( datasets.ba2motif_dataset datasets.reddit2
datasets.HeterophilousGraphDataset( datasets.ba_multi_shapes datasets.rel_link_pred_dataset
datasets.HydroNet( datasets.ba_shapes datasets.s3dis
datasets.ICEWS18( datasets.bitcoin_otc datasets.sbm_dataset
datasets.IMDB( datasets.citation_full datasets.shapenet
datasets.InfectionDataset( datasets.classes datasets.shrec2016
datasets.JODIEDataset( datasets.coauthor datasets.snap_dataset
datasets.KarateClub( datasets.coma datasets.suite_sparse
datasets.LINKXDataset( datasets.dblp datasets.taobao
datasets.LRGBDataset( datasets.dbp15k datasets.torch_geometric
datasets.LastFM( datasets.deezer_europe datasets.tosca
datasets.LastFMAsia( datasets.dgraph datasets.tu_dataset
datasets.MD17( datasets.dynamic_faust datasets.twitch
datasets.MNISTSuperpixels( datasets.elliptic datasets.upfd
datasets.MalNetTiny( datasets.email_eu_core datasets.utils
datasets.MixHopSyntheticDataset( datasets.entities datasets.webkb
datasets.ModelNet( datasets.explainer_dataset datasets.wikics
datasets.MoleculeNet( datasets.facebook datasets.wikipedia_network
datasets.MovieLens( datasets.fake datasets.willow_object_class
datasets.NELL( datasets.faust datasets.word_net
datasets.OGB_MAG( datasets.flickr datasets.yelp
datasets.OMDB( datasets.freebase datasets.zinc
datasets.PCPNetDataset( datasets.gdelt
datasets.PPI( datasets.ged_dataset
2. 使用Planetoid下载Cora数据集的代码
这里以常用的datasets.Planetoid为例,介绍如何下载和使用数据集:
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./testdata/Cora',name='Cora')
data = dataset._data
print(data.x) # 节点表示
print(data.edge_index)
print(data.y)
这里下载了Cora数据集,这是一个表示论文引用网络的数据集,每个节点为1433维,是一个用one-hot表示词袋的向量。通过对Planetoid类说明的阅读,可以看到这个类还可以用于下载Cite Seer和PubMed两个数据集,使用方法相同。
class Planetoid(InMemoryDataset):
r"""The citation network datasets :obj:`"Cora"`, :obj:`"CiteSeer"` and
:obj:`"PubMed"` from the `"Revisiting Semi-Supervised Learning with Graph
Embeddings" <https://arxiv.org/abs/1603.08861>`_ paper.
Nodes represent documents and edges represent citation links.
Training, validation and test splits are given by binary masks.
Args:
root (str): Root directory where the dataset should be saved.
name (str): The name of the dataset (:obj:`"Cora"`, :obj:`"CiteSeer"`,
:obj:`"PubMed"`).
...
"""
3. 解决程序运行的机器无法联网的问题
在上面的代码中,我们传入了两个参数,第一个参数root表示数据集要下载的位置,第二个参数表示数据集名称(如果该类只能下载一个数据集,一般没有name参数)。这里国内用户常常遇到的问题是,程序会自动从github等网站上下载数据集,但我们的机器常常因为网络问题而无法连接,这个时候我们可以手动把数据集下载,然后传到服务器的对应目录。
具体做法分为三步:
3.1 尝试运行,查看数据集下载链接
运行程序会看到这样一行输出:
Downloading https://github.com/kimiyoung/planetoid/raw/master/data/ind.cora.x
那我们就来看一看https://github.com/kimiyoung/planetoid/raw/master/data/下面有哪些内容吧。
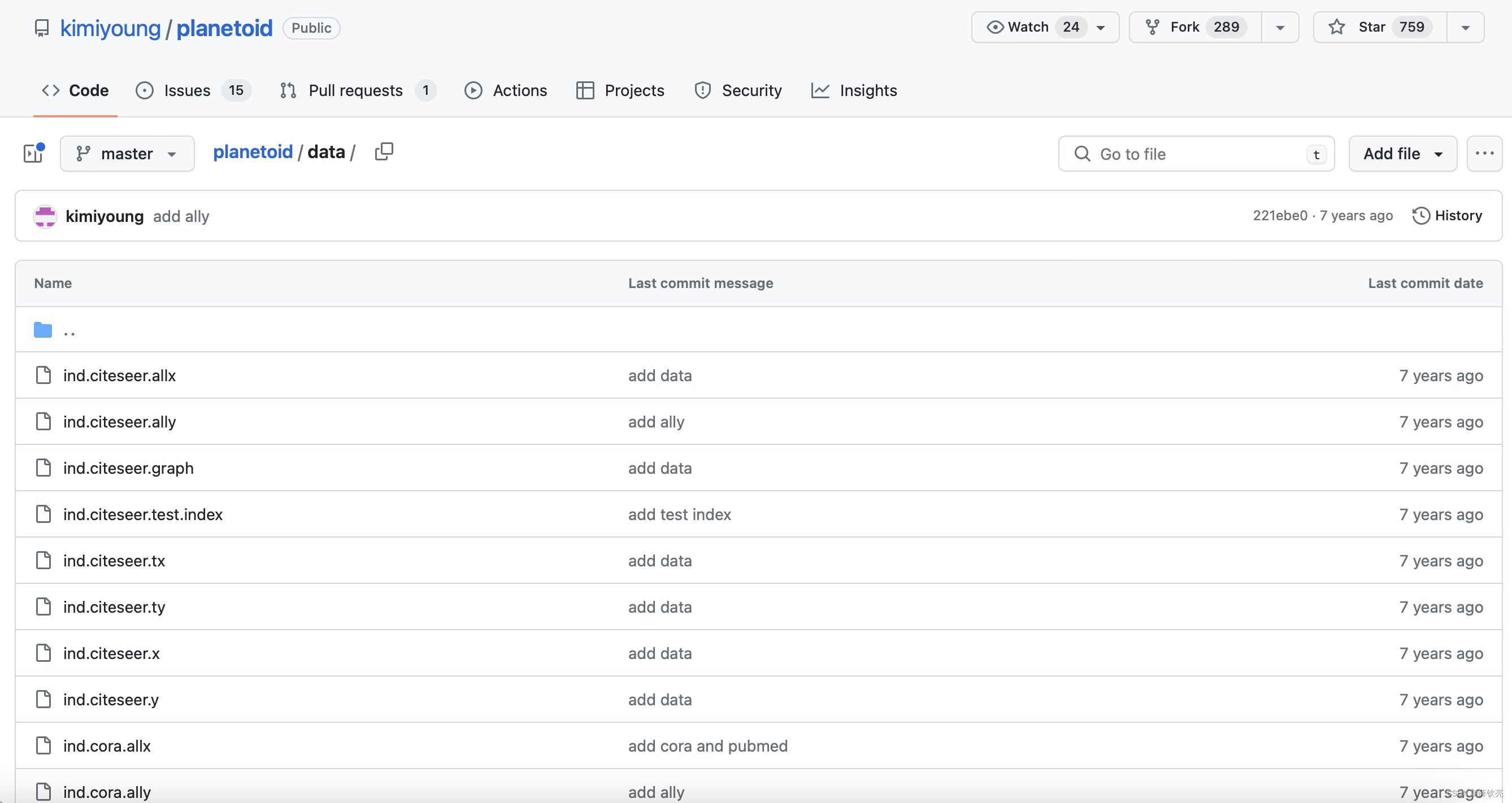
可以看到这里包含了Cora、PubMed、CiteSeer相关的数据,我们可以先把Cora相关的文件下载下来。
3.2 放置到对应文件夹下
实际上,torch_geometric.datasets中的类会先检测指定位置是否有所需文件,如果没有才会去下载,如果有则直接处理使用。我们第一步下载的文件,必须放到对应文件夹下,Planetoid类才能找到数据,不再从网络上下载。
观察一下Planetoid源码,raw_dir和raw_file_names就是决定Planetoid类对象寻找对象的位置:
@property
def raw_dir(self) -> str:
if self.split == 'geom-gcn':
return osp.join(self.root, self.name, 'geom-gcn', 'raw')
return osp.join(self.root, self.name, 'raw')
@property
def processed_dir(self) -> str:
if self.split == 'geom-gcn':
return osp.join(self.root, self.name, 'geom-gcn', 'processed')
return osp.join(self.root, self.name, 'processed')
@property
def raw_file_names(self) -> List[str]:
names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
return [f'ind.{self.name.lower()}.{name}' for name in names]
可以看到raw_dir是self.root、self.name和'raw'拼起来的路径,我们上面传入的root是'./testdata/Cora',name是'Cora',所以raw_dir就是'./testdata/Cora/Cora/raw'。
raw_file_names返回值包含正则表达式,容易看出要找的就是:'ind.cora.x'、'ind.cora.tx'、'ind.cora.allx'、'ind.cora.y'、'ind.cora.ty'、'ind.cora.ally'、'ind.cora.graph'、'ind.cora.test.index'这几个文件。看一眼上一步的文件列表,正好都有,我们把这些下载好的文件放在'./testdata/Cora/Cora/raw'这个目录下即可。
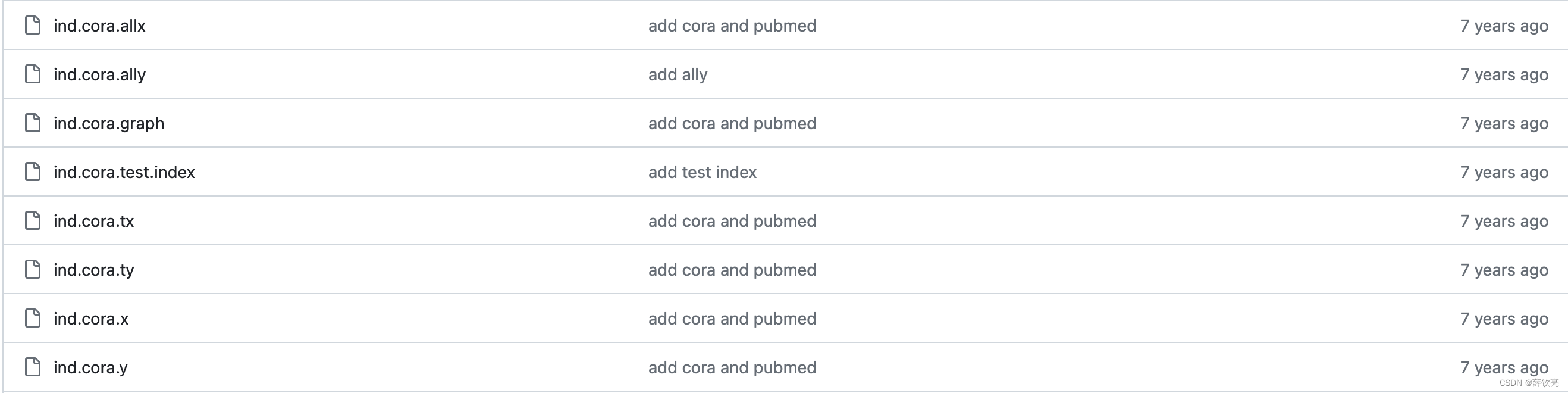
3.3 重新运行之前写的程序
程序会检测到数据已经在所需目录下,跳过下载步骤,直接开始处理数据,成功的话,我们会看到:
$ python planetoid.py
Processing...
Done!
这里的Processing我们不用管具体过程,大体上就是从数据集繁杂的文件中读取数据并处理成我们最终需要的格式。最终输出的格式为torch_geometric.data.Data类型,包含x(节点特征)、edge_index(稀疏矩阵)、y(节点标签)等信息。这个类型已经可以直接装入dataloader处理成batch进行深度学习。
处理之后的数据保存在3.2我们看到的processed_dir中,在本文中也就是'./testdata/Cora/Cora/processed'。如果程序发现该目录下有处理之后的文件,再次运行也会跳过Processing,不再重复处理。
4. 一点感慨
torch_geometric.datasets真的方便,基本集成了常见所有的图数据集,不需要手动下载处理,直接到位!