本身LBP+SVM是比较经典的技术路线用来做图像识别、目标检测,没有什么特殊的地方
fer2013数据集在我之前的博文中也有详细的实践过,如下:
《fer2013人脸表情数据实践》 系统地基于CNN开发实现
《Python实现将人脸表情数据集fer2013转化为图像形式存储本地》 一键复制代码即可实现原始csv文件转储本地图像
LBP+SVM和fer2013组合起来去使用就出现了有意思的东西了,本身LBP提取出来的特征维度就很大一般都是将近2w维,然后fer2013数据集又有接近4w的数据量,这就导致SVM模型最终的训练极度膨胀缓慢。
我是昨天回去的时候放在云服务器上面跑的,但是隔了4个小时还没有结束就休息了,一早醒来看到结果出来了,就是觉得简单的事情做得挺波折,这个还是服务器的算力计算得到的,如果是普通的PC机估计就更慢了吧。
简单看下:

整体项目比较精简,train.json表示训练数据提取出来的LBP向量存储得到的文件,test.json表示测试数据提取出来的LBP向量存储得到的文件。mlModel.py是源代码,实现了数据加载,SVM模型训练和测试评估整套流程。results是存储下来的SVM模型和评估指标结果文件。
当我早上看到这个results体积的时候着实惊呆了,从来还没有看到过SVM模型这么这么的大,进入results目录看下,详情如下:
![]()
一个基于LBP特征训练出来的SVM模型居然达到了恐怖的3+GB。
但是从评估结果上来看结果却是比较惨淡的,如下:
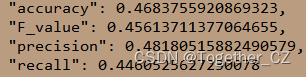
这里也统计了单个类别下的详情:
"angry": {
"accuracy": 0.41541755888650969,
"F_value": 0.08385562999783879,
"precision": 0.14285714285714286,
"recall": 0.05934536555521567
},
"disgust": {
"accuracy": 0.3392857142857143,
"F_value": 0.08444444444444444,
"precision": 0.16666666666666667,
"recall": 0.05654761904761905
},
"fear": {
"accuracy": 0.37298387096774196,
"F_value": 0.0776169498636459,
"precision": 0.14285714285714286,
"recall": 0.053283410138248849
},
"happy": {
"accuracy": 0.646927374301676,
"F_value": 0.11223105252955999,
"precision": 0.14285714285714286,
"recall": 0.09241819632881086
},
"neutral": {
"accuracy": 0.41186161449752886,
"F_value": 0.08334722453742291,
"precision": 0.14285714285714286,
"recall": 0.058837373499646978
},
"sad": {
"accuracy": 0.27565084226646249,
"F_value": 0.06173898130680843,
"precision": 0.14285714285714286,
"recall": 0.03937869175235178
},
"surprise": {
"accuracy": 0.6602409638554216,
"F_value": 0.11362222682977399,
"precision": 0.14285714285714286,
"recall": 0.09432013769363167
}整体来看:效果比较一般,这个还是比较适合用深度学习去做的,感觉这样的数据体量和状态下SVM很难有较好的效果!