文章目录
- 1.Hive介绍
- 1.1 hive 基本情况
- 1.2 Hive架构原理
- 1.3 Hive 安装
- 1.4 元数据配置
- 1.5 hive 服务部署
- 1.6Hive常用交互命令
- 1.6.1 Hive参数配置方式
1.Hive介绍
1.1 hive 基本情况
hive基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表。
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。
其中Hive中每张表的数据存储在HDFS,Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)并且执行程序运行在yarn上。
1.2 Hive架构原理
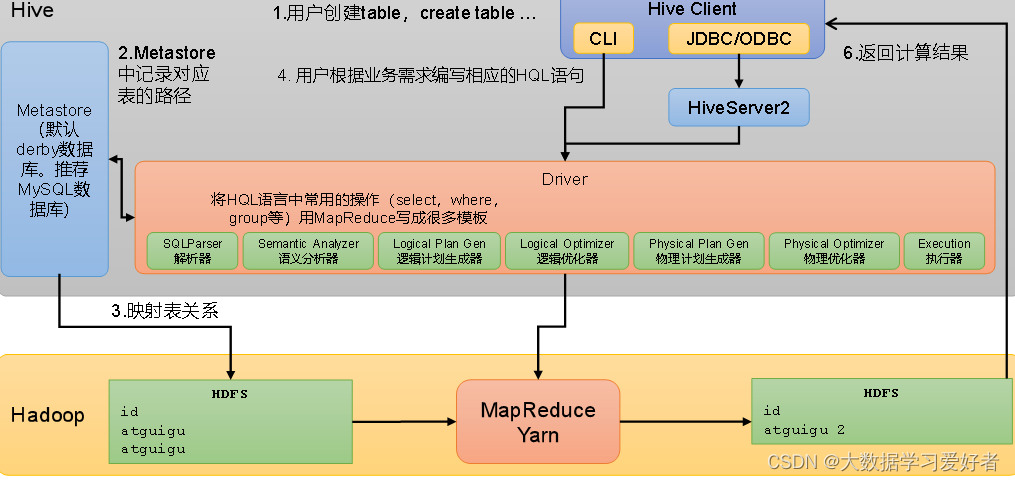
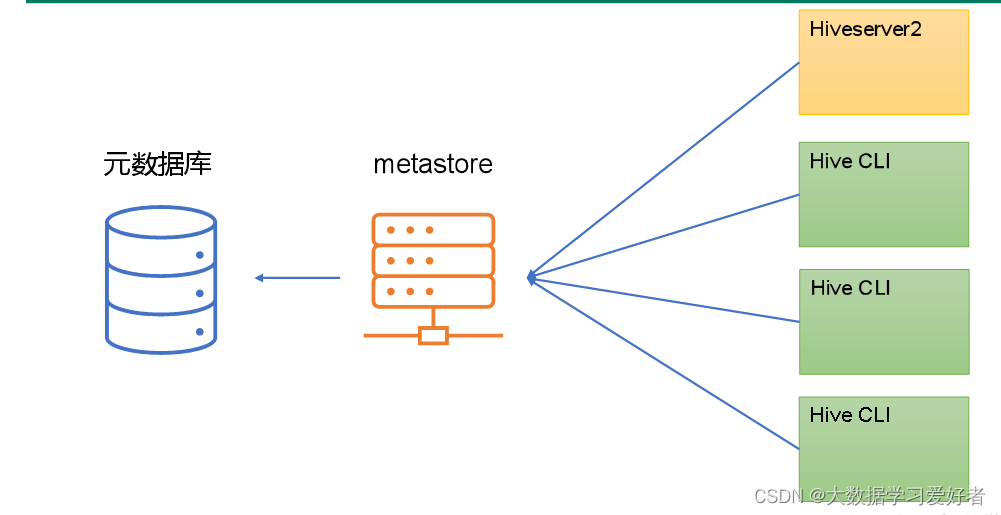
1.metastore 服务:
元数据访问接口,用户创建表的信息,表中的数据信息,数据库对应hdfs路径,表对应hdfs路径的信息。每个字段的类型等等。只提供元数据的访问接口,不保存元数据。
元数据保存在mysql数据库中。
2.Hiveserver2服务:
提供jdbc/odbc的访问的接口。用户认证的接口。
3.cli 命令行端口,远程访问jdbc的接口数据。
用户建表->meta信息对应表的路径信息->mysql 和hdfs的映射关系。文件的数据和hive一行的数据。
4.比如查询,编译和执行的都是在driver中执行。当运行在命令行客户端,driver就在命令行当中,当jdbc客户端hiveserver2的driver运行的hiveserver中。
driver就是讲hive sql转换成mapreduce执行。
driver在编译hivesql 需要使用的是元数据的,表和hdfs路径。
HSQL 编译流程:
词法分析:
sql 进行字符进行扫描,根据预置关键词生成token, select,tok。识别关键字。
语法分析:
对tok进行组合成一个短句。表达式。组成完整的语句。树结构,用sql抽象语法树
1.解析器(SQLParser):将SQL字符串转换成抽象语法树(AST)
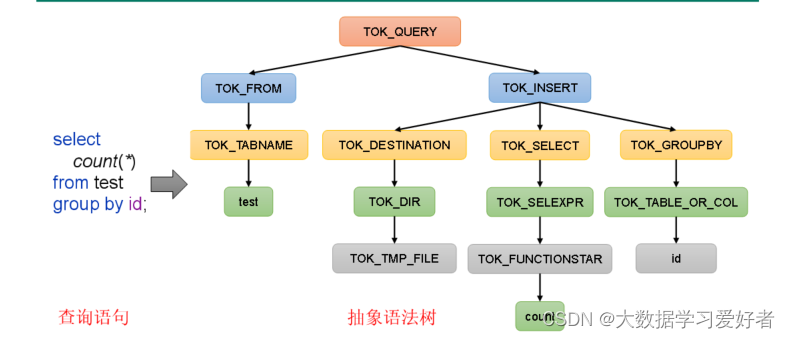
2.语义分析(Semantic Analyzer):将AST进一步划分为QeuryBlock
将抽象语法树转成查询块
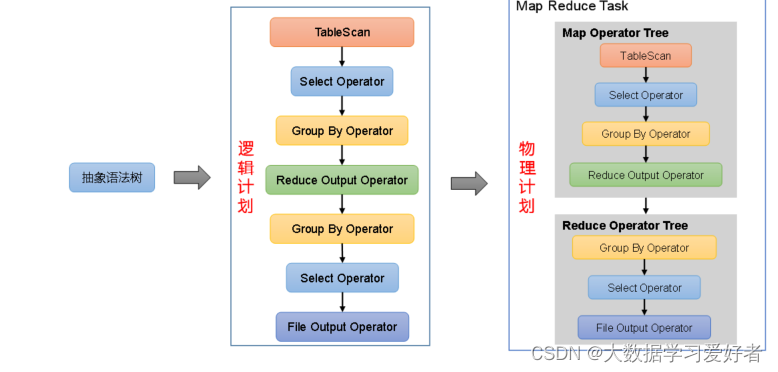
3.逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划
4.逻辑优化器(Logical Optimizer):对逻辑计划进行优化(谓词下推,将filter操作前移)
5.物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理计划
6.物理优化器(Physical Optimizer):对物理计划进行优化(map join ,判断是否有小表,小表转mapjoin,缓存到小表。没有reduce操作)
7.执行器(Execution):执行该计划,得到查询结果并返回给客户端
1.3 Hive 安装
1.把apache-hive-3.1.3-bin.tar.gz上传到Linux的/opt/software目录下
2.解压apache-hive-3.1.3-bin.tar.gz到/opt/module/目录下面
tar -zxvf /opt/software/apache-hive-3.1.3-bin.tar.gz -C /opt/module/
mv /opt/module/apache-hive-3.1.3-bin/ /opt/module/hive
sudo vim /etc/profile.d/my_env.sh
(1)添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/my_env.sh
观察HDFS的路径/user/hive/warehouse/stu,体会Hive与Hadoop之间的关系。
Hive中的表在Hadoop中是目录;Hive中的数据在Hadoop中是文件。
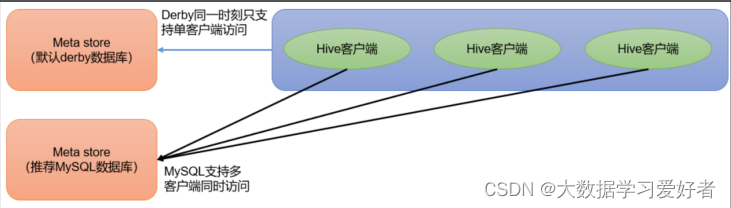
1.4 元数据配置
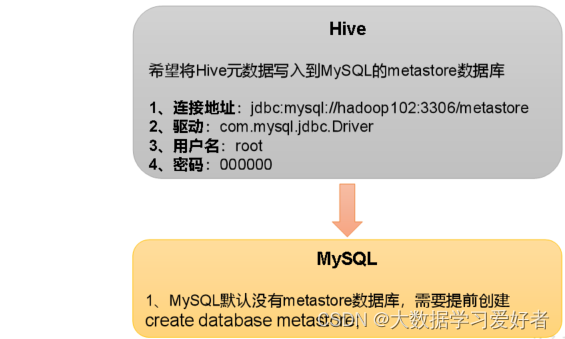
1)新建Hive元数据库
#登录MySQL
mysql -uroot -p123456
mysql> create database metastore;
mysql> quit;
cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
vim $HIVE_HOME/conf/hive-site.xml
添加如下内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
初始化Hive元数据库(修改为采用MySQL存储元数据)
bin/schematool -dbType mysql -initSchema -verbose
验证元数据是否配置成功多个连接器来连。
查看MySQL中的元数据
查看元数据库中存储的库信息
mysql> select * from DBS;
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+
| 1 | Default Hive database | hdfs://hadoop102:8020/user/hive/warehouse | default | public | ROLE | hive |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+
(2)查看元数据库中存储的表信息
mysql> select * from TBLS;
+--------+-------------+-------+------------------+---------+------------+-----------+-------+----------+---------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE |
+--------+-------------+-------+------------------+---------+------------+-----------+-------+----------+---------------+
| 1 | 1656318303 | 1 | 0 | atguigu | USER | 0 | 1 | stu | MANAGED_TABLE |
+--------+-------------+-------+------------------+---------+------------+-----------+-------+----------+---------------+
(3)查看元数据库中存储的表中列相关信息
mysql> select * from COLUMNS_V2;
+-------+----------+---------+------------+-------------+-------------+--------+
| CS_ID | CAT_NAME | DB_NAME | TABLE_NAME | COLUMN_NAME | COLUMN_TYPE | TBL_ID |
+-------+----------+---------+------------+-------------+-------------+--------+
| 1 | hive | default | stu | id | int | 1 |
| 2 | hive | default | stu | name | string | 1 |
+-------+----------+---------+------------+-------------+-------------+--------+
1.5 hive 服务部署
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能。
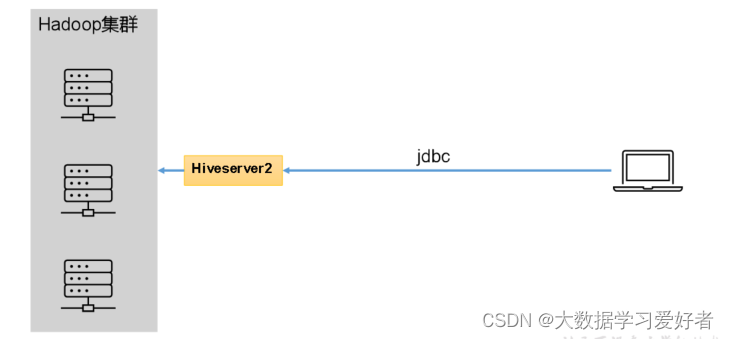
独立
独立服务模式需做以下配置:
首先,保证metastore服务的配置文件hive-site.xml中包含连接元数据库所需的以下参数:
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
其次,保证Hiveserver2和每个Hive CLI的配置文件hive-site.xml中包含访问metastore服务所需的以下参数:
<!-- 指定metastore服务的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
注意:主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083。
1.6Hive常用交互命令
“-e”不进入hive的交互窗口执行hql语句
bin/hive -e "select id from student;"
bin/hive -f /opt/module/hive/datas/hivef.sql --运行sql.
> /opt/module/hive/datas/hive_result.txt
1.6.1 Hive参数配置方式
配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定
命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。例如:
bin/hive -hiveconf mapreduce.job.reduces=10;