传统上,内存层次结构的设计者专注于优化平均内存访问时间,这由缓存访问时间、未命中率和未命中惩罚决定。 然而,最近,功率已成为主要考虑因素。 在高端微处理器中,可能有 60 MiB 或更多的片上高速缓存,并且大型二级或三级高速缓存将消耗大量功率。 这个问题在 PMD 中的处理器中更为严重,其中 CPU 的攻击性较低,功率预算可能小 20 到 50 倍。 在这种情况下,缓存可以占总功耗的 25% 到 50%。 因此,更多的设计必须同时考虑性能和功耗的权衡。
当在缓存中找不到一个词时,必须从层次结构中的较低级别(可能是另一个缓存或主存储器)中取出该词并将其放入缓存中,然后再继续。 多个单词,称为块(或行),出于效率原因而被移动,并且由于空间局部性可能很快需要它们。 每个缓存块都包含一个标记,用于指示它对应于哪个内存地址。
缓存与内存:
- 缓存是CPU的一部分,存在于CPU里,而内存是一个独立的硬件设备,连接在CPU和主板之间。
- 缓存的速度比内存快得多,但是容量比内存小得多。缓存的作用是暂时存放CPU经常访问的数据,以减少CPU和内存之间的数据交换,提高CPU的运算效率。
- 缓存一般有多级,例如L1、L2、L3等,等级越高,速度越慢,容量越大。缓存之间采用不同的映射方式,例如直接映射、组关联或全关联等,来决定如何把主存中的块映射到缓存中的位置。
- 内存是以二进制的形式来存储数据的,所有的信息都是用0和1来表示的。内存中没有文档结构或图像格式之类的概念,只有计算机能够识别的二进制代码。内存中的每个单元都有一个唯一的地址,用来标识其位置和内容。
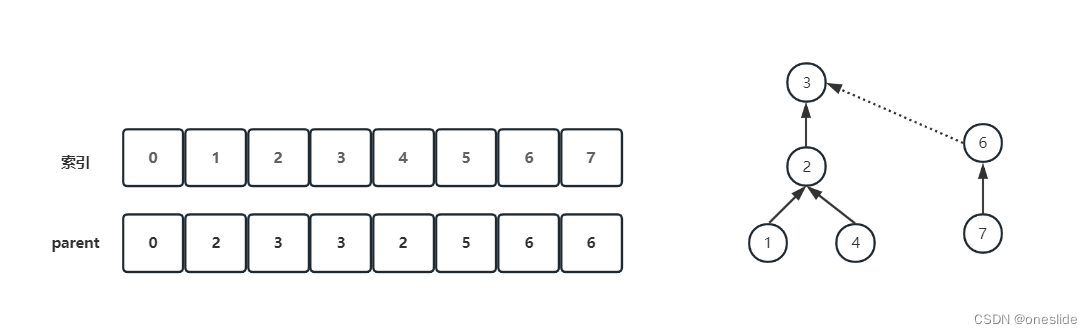
一个关键的设计决定是块(或行)可以放在缓存中的什么地方。 最流行的方案是集合关联,其中集合是缓存中的一组块。 一个块首先被映射到一个集合上,然后这个块可以被放置在该集合中的任何地方。 查找块包括首先将块地址映射到集合,然后搜索集合(通常是并行的)以查找块。 该集合由数据地址选择:
(Block address) MOD (Number of sets in cache)
也就是(区块地址) /(缓存组数)
如果一个集合中有 n 个块,则缓存放置称为 n 路集合关联。 集合结合性的端点有自己的名字。 直接映射缓存每组只有一个块(因此块总是放在同一位置),而完全关联缓存只有一组(因此块可以放在任何地方)。
1. 直接映射缓存(Direct mapped cache)
每个内存块只能存储到一个缓存槽。一个简单方案是通过块索引把内存块映射到缓存槽(块索引 % 缓存槽数量(即取余数操作))。映射到同一个槽的内存块不能同时存储在缓存中。
2. N路关联缓存(N-way set associative cache)
每个内存块映射到N个特定缓存槽的任意一个槽。例如一个16路缓存,任何一个内存块能够被映射到16个不同的缓存槽。通常,具有相同低bit位地址的内存块共享相同的16个槽。
3. 完全关联缓存(Fully associative cache)
每个内存块可以被映射到任意一个缓存槽(cache slot)。事实上,缓存操作和哈希表很像。
直接映射会遭遇冲突的问题——当多个块同时竞争缓存的同一个槽时,它们不停地将对方踢出缓存,这将降低命中率。另一方面,完全关联过于复杂,很难在硬件层面实现。N路关联是典型的处理器缓存设计方案,因为它在实现难度和提高命中率之间做了良好的折衷。
例如,我电脑上的4M L2 缓存采用 16 路关联的方案。所有的64字节大小的内存块被分配到集合中(基于块索引的低字节),同一个集合中的块竞争使用 L2 缓存的16个槽。
由于 L2 缓存有65536 个槽,而每个集合需要16个槽,因此我们有4096个集合。由此,块索引的低12比特能够确定这个块所在的集合(2^12 = 4096)。进而可以计算出,相差262144字节倍数的地址(4096*64)会竞争同一个槽。
缓存只读取的数据很容易,因为缓存和内存中的副本是相同的。 缓存写入比较困难; 例如,缓存和内存中的副本如何保持一致? 有两个主要策略。 直写高速缓存更新高速缓存中的项目并直写更新主内存。 回写缓存仅更新缓存中的副本。 当块即将被替换时,它被复制回内存。 两种写策略都可以使用写缓冲区来允许缓存在数据放入缓冲区后立即继续,而不是等待完全延迟将数据写入内存。
衡量不同缓存组织优势的一项指标是未命中率。 未命中率只是导致未命中的高速缓存访问的分数,即未命中的访问次数除以访问次数。
失败类别如下:
■ 强制性——对块的第一次访问不能在缓存中,因此必须将块放入缓存中。 强制未命中是即使拥有无限大小的缓存也会发生的那些。
■ 容量——如果缓存不能包含程序执行期间所需的所有块,容量缺失(除了强制缺失之外)将会发生,因为块被丢弃并在稍后检索。
■ 冲突——如果块放置策略不是完全关联的 ,冲突未命中(除了强制和容量未命中)将会发生,因为如果多个块映射到它的集合并且对不同块的访问混合在一起,那么一个块可能会被丢弃并稍后被检索。
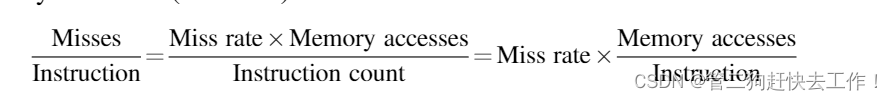
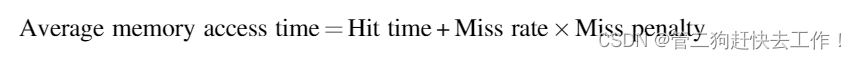 其中命中时间是命中缓存的时间,未命中惩罚是从内存中替换块的时间(即未命中的成本)。 平均内存访问时间仍然是性能的间接衡量标准; 尽管它比未命中率更好,但不能替代执行时间。
其中命中时间是命中缓存的时间,未命中惩罚是从内存中替换块的时间(即未命中的成本)。 平均内存访问时间仍然是性能的间接衡量标准; 尽管它比未命中率更好,但不能替代执行时间。