机器学习——logit正则化
文章目录
- 机器学习——logit正则化
- @[toc]
- 1 logit模型正则化
- 2 logit回归求解器
-
文章目录
- 机器学习——logit正则化
- @[toc]
- 1 logit模型正则化
- 2 logit回归求解器
1 logit模型正则化
logit模型能实现分类,识别研究事物的属性特征。如果影响研究对象的属性类别的特征变量较多时,需要考虑对logit模型的参数施加惩罚,即对损失函数进行正则化。正则化包括 ℓ 1 \ell_1 ℓ1正则化(L1范数)和 ℓ 2 \ell_2 ℓ2正则化(L2范数),进而识别和筛选出那些具有稳健性的特征变量。
为估计logit模型,给定参数
(
w
,
w
0
)
(w,w_0)
(w,w0),最小化成本损失函数
min
w
C
∑
i
=
1
n
(
−
y
i
log
(
p
^
(
X
i
)
)
−
(
1
−
y
i
)
log
(
1
−
p
^
(
X
i
)
)
)
+
r
(
w
)
\min _w C \sum_{i=1}^n\left(-y_i \log \left(\hat{p}\left(X_i\right)\right)-\left(1-y_i\right) \log \left(1-\hat{p}\left(X_i\right)\right)\right)+r(w)
wminCi=1∑n(−yilog(p^(Xi))−(1−yi)log(1−p^(Xi)))+r(w)
其中
p
^
(
X
i
)
=
1
1
+
exp
(
−
X
i
w
−
w
0
)
\hat{p}\left(X_i\right)=\dfrac{1}{1+\exp \left(-X_i w-w_0\right)}
p^(Xi)=1+exp(−Xiw−w0)1,
r
(
w
)
r(w)
r(w)为正则化(或惩罚)项,包括以下四种类型
| 正则化类型 | r ( w ) r(w) r(w) |
|---|---|
| None | 0 |
| ℓ 1 \ell_1 ℓ1—L1范数 | ∣ w 1 ∣ \lvert w_1\rvert ∣w1∣ |
| ℓ 2 \ell_2 ℓ2—L2范数 | 1 2 ∣ w ∣ 2 2 = 1 2 w T w \dfrac{1}{2}\lvert w\rvert_2^2 = \dfrac{1}{2}w^Tw 21∣w∣22=21wTw |
| Elasitic-Net | 1 − ρ 2 w T w + ρ ∣ w 1 ∣ \dfrac{1-\rho}{2} w^T w+\rho\lvert w_1\rvert 21−ρwTw+ρ∣w1∣ |
2 logit回归求解器
Python中,基于sklearn的LogisticRegression求解器包括: “liblinear”, “newton-cg”, “lbfgs”, “sag” and “saga”。
liblinear:使用作标下降法,不能实现多分类任务,取而代之的是将1对多任务进行分解,转化二类任务问题。lbfgs, sag和 newton-cg只支持 ℓ 2 \ell_2 ℓ2正则化或者无正则化,适合多分类任务,高维数据收敛速度更快。sag使用随机平均梯度下降;lbfgs属于拟牛顿的方法,建议用于小数据集, 大型数据集表现不佳。saga支持非光滑 ℓ 1 \ell_1 ℓ1正则化,也是唯一 一个支持弹性网正则化的优化方案。
2.1 ℓ 1 \ell_1 ℓ1和 ℓ 2 \ell_2 ℓ2正则化
首先生成虚拟数据
from sklearn.linear_model import LogisticRegression
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
import pandas as pd
from sklearn.model_selection import train_test_split
# DGP
np.random.seed(123456)
n = 100000
x = norm.rvs(loc=0, scale=1, size=n).reshape(10000, 10)
x = pd.DataFrame(x)
x.columns = ['x1', 'x2', 'x3','x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10']
# 误差项
u = pd.DataFrame(norm.rvs(loc=0, scale=10, size=10000).reshape(10000, 1))
y = x['x1'] - x['x2'] + x['x3'] - 5*x['x4'] +3*x['x5']+u.iloc[0:9999,0]
y = np.float32(y > 0)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)
使用liblinear求解器进行参数估计
# C正则化强度的倒数
lr_l1 = LogisticRegression(penalty="l1", C=0.01, solver="liblinear")
lr_l2 = LogisticRegression(penalty="l2", C=0.01, solver="liblinear")
lr_l1.fit(X_train, y_train)
lr_l2.fit(X_train, y_train)
print(f'使用l1正则化参数估计为\n{lr_l1.coef_}\n')
print(f'使用l2正则化参数估计为\n{lr_l2.coef_}\n')
# 使用l1正则化参数估计为
# [[ 0.06384757 -0.08083441 0.10173666 -0.72628788 0.37431005 0.
# 0. 0. 0. 0. ]]
# 使用l2正则化参数估计为
# [[ 0.12446733 -0.14140626 0.16069834 -0.75861182 0.42387989 -0.0039323
# -0.02225432 -0.03519713 -0.03028171 0.02025389]]
使用 ℓ 1 \ell_1 ℓ1具有变量筛选功能,某些变量系数为0,而 ℓ 2 \ell_2 ℓ2所有回归系数不为0(从结果看)。接下来绘制两种正则化系数搜索路径
clf = LogisticRegression(
penalty="l2",
solver="saga",
tol=1e-6,
max_iter=int(1e6),
warm_start=True,
intercept_scaling=1.0,
)
coefs1 = []
coefs2 = []
for i in np.linspace(0.0001, 100, 1000):
l1 = LogisticRegression(penalty="l1", solver="liblinear", C=i, max_iter=1000)
l2 = LogisticRegression(penalty="l2", solver="liblinear", C=i, max_iter=1000)
lrl1 = l1.fit(X_train, y_train)
lrl2 = l2.fit(X_train, y_train)
coefs1.append(lrl1.coef_.ravel().copy())
coefs2.append(lrl2.coef_.ravel().copy())
print(i)
coefs1 = np.array(coefs1)
coefs2 = np.array(coefs2)
plt.subplot(121)
plt.plot(np.log10(np.linspace(0.0001, 100, 1000)), coefs1,label = x.columns)
ymin, ymax = plt.ylim()
plt.xlabel("$log(C)$")
plt.ylabel("Coefficients")
plt.title("Logistic Regression $\ell_1$ Path")
plt.axis("tight")
plt.grid()
plt.legend()
plt.show()
plt.subplot(122)
plt.plot(np.log10(np.linspace(0.0001, 100, 1000)), coefs2,label = x.columns)
plt.xlabel("$log(C)$")
plt.ylabel("Coefficients")
plt.title("Logistic Regression $\ell_2$ Path")
plt.axis("tight")
plt.grid()
plt.legend()
plt.show()

2.2 e l a s t i c − n e t elastic-net elastic−net正则化
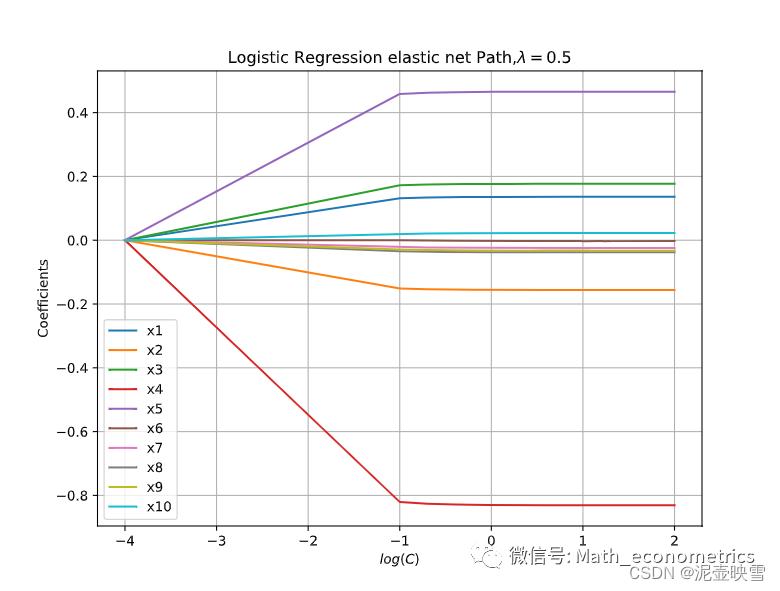
接下来使用弹性网正则化进行估计,为减少估计时间,指定 ρ = 0.5 \rho = 0.5 ρ=0.5
coefs = []
for i in np.linspace(0.0001, 100, 1000):
el = LogisticRegression(penalty="elasticnet", solver="saga", C=i, l1_ratio=0.5, max_iter=1000)
result = el.fit(X_train, y_train)
coefs.append(result.coef_.ravel().copy())
print(i)
coefs = np.array(coefs)
# 可视化
plt.plot(np.log10(np.linspace(0.0001, 100, 1000)), coefs, label=x.columns)
ymin, ymax = plt.ylim()
plt.xlabel("$log(C)$")
plt.ylabel("Coefficients")
plt.title("Logistic Regression elastic net Path,$\lambda = 0.5$")
plt.axis("tight")
plt.grid()
plt.legend()
plt.show()
[1] https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression<\br>