接上篇,继续梳理 Python 爬虫入门的知识点。这里将重点说明,如何识别网站反爬虫机制及应对策略,使用 Selenium 模拟浏览器操作等内容,干货满满,一起学习和成长吧。
1、识别反爬虫机制及应对策略
1.1 测试网站是否开启了反爬虫
随着互联网技术的日益革新,大多数的网站都会使用反爬虫机制。我们在爬取目标页面之前,第一步就是要识别需不需要应对网站的反爬虫,常见的测试方式有:
<1>、使用 requests 模块提供的 API
# 以get方式发送请求,暂时不加入请求头
response = requests.get(url)
if response.status_code != 200:
print(f"网站开启了发爬虫机制,响应状态为{status_code}")<2>、使用爬虫框架提供的测试命令
以 Scrapy 框架为例,需先下载该依赖(pip install Scrapy),接着在 CMD 命令行 或 其他终端键入测试命令:
Scrapy shell 目标url如果上述的测试返回响应码为200,说明网站不存在反爬虫机制,如果是其他的响应码类型,需要具体分析对应哪种反爬虫机制。
响应状态码
这里,顺带普及下响应状态码 Status Code 的内容,它是用 3 位十进制数表示,以代码的形式表示服务器对请求的处理结果。现行的 RFC 标准把状态码分成了五类,用数字的第一位表示分类,范围在100~599 之间。这五类的具体含义,如下:
1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
2××:成功,报文已经收到并被正确处理;
3××:重定向,资源位置发生变动,需要客户端重新发送请求;
4××:客户端错误,请求报文有误,服务器无法处理;
5××:服务器错误,服务器在处理请求时内部发生了错误。最常用的状态码有,200(成功),301(永久移动),302(临时移动),400(错误请求),401(未授权),403(请求被禁止),404(未找到),500(服务器内部错误)。使用爬虫过程中,遇到最多的则是 200 和 403 了。
当然,目前 RFC 标准里总共有 41 个状态码,但状态码定义是开放的,允许自行扩展。因此像 Apache、Nginx 等 Web 服务器都定义了一些专有的状态码。如果自己开发 Web 应用的话,也可以在不冲突的前提下定义项目专有的状态码。
1.2 User-Agent检查
在上篇已经介绍过,检查 User-Agent 是一种最简单且最常见的反爬虫策略,网站会检查发送的请求中是否存在请求头信息,如果检查不存在的话,网站服务器会拒绝请求!
应对策略也很简单,发送请求的时候加上请求头信息即可,如下:
import requests
from fake_useragent import UserAgent
# 请求头
headers = UserAgent(path="D:\\XXX\\reptile\\fake_useragent.json").google
# 发送请求
response = requests.get(url, headers)
# 获取整个html文档
html = response.text
print(html)1.3 访问频率检查
通常情况下,人工去点击页面,不会在1s内访问几十甚至上百个网页,也不会有类似 5s/次 访问页面的精确操作,一旦识别到这类情况,网站则会怀疑你是机器人,就会触发反爬虫机制,拒绝这种高频次或精准性的请求操作。
应对这种情况,根据这种机制特征,我们需要设置随机的访问时间间隔,降低请求网站的频率(最好考虑目标网站的访问承受能力,不要把人家搞崩了~)。当然,也可以使用 Selenium 模拟浏览器操作,该模块的使用在后面再详细的说明,这里不展开。
1.4 Session访问限制
我们知道 HTTP 是一种无状态的协议,为了维持客户端与服务器之间的通信状态,使用 Cookie 技术来保持双方的通信状态。有些网站的网页是需要登录才允许爬取数据的,而登录的原理就是浏览器首次通过用户名密码登录之后,服务器给客户端发送一个随机的 Cookie,下次浏览器请求其它页面时,就把刚才的 Cookie 随着请求一起发送给服务器,这样服务器就知道该用户已经是登录用户。
应对这种情况,需要调整下爬虫代码,使用带 Session 会话的请求登陆,然后再访问目标网页,如下:
import requests
# 构建Session会话
session = requests.Session()
# 通过post请求登陆
session.post(login_url, data={username, pwd})
# 访问目标网页
r = session.get(home_url)
# 释放会话资源
session.close()当构建一个 Session 会话之后,客户端第一次发起请求登录账户,服务器自动把 Cookie 信息保存在 Session 对象中,发起第二次请求时 requests 自动把 Session 中的 Cookie 信息发送给服务器,使之保持通信状态。
1.5 IP访问限制
有些网站为了不让你爬取,可能会精准识别你的 IP 操作。比如,如果发现短时间内该 IP多次访问同一个页面,则会判定你在使用爬虫,触发网站的反爬虫,则会封杀你的 IP(至于永久封杀还是一定时间内不能再次访问,看具体网站的策略了~)。这种情况不好识别,因为当你意识到这种情况时,你当前 IP 可能无法继续访问了。
当然,应对这种情况,通过代理 IP 可以迎刃而解。我们可以爬取网上公开且免费的代理 IP,有了大量代理 IP 后可以每请求几次更换一个 IP,这样就能继续之前的爬虫操作了。
import requests
import re
def get_ip_list(url, headers, pattern):
ip_list = []
response = requests.get(url, headers)
if response.status_code == 200:
html = response.text
# 按正则先匹配到提取的范围
match_all_data = re.findall(pattern, html)
for i in range(len(match_all_data)):
# 对每一条url进行精准匹配,可根据具体的情况进行分析
url = re.findall(pattern, match_all_data[i])
ip_list.append(url)
return ip_list这里,为了能最有效率的利用这些代理 IP,爬取完成后可以考虑放到数据库保存,每次使用时先从数据库里拿。另外,当数据库里可用的代理 IP 数量低于某个阈值时,可以考虑再爬取一批代理 IP,用于更新或补充自己的 IP 池,这样 IP 池里就会保持处于可用状态。
1.6 验证码校验
生活中,我们看到的验证码可谓五花八门,主要类型有:随机数字图片验证码、滑动验证码、手机验证码、邮箱/手机号组合验证等。网站通过常规验证码和滑动验证码的校验,可以区分人机操作,并防止恶意注册、暴力破解、刷票、论坛灌水、黑客攻击等行为;而通过手机号码、邮箱手机号组合等校验,主要是验证用户信息,保护用户信息安全。对于爬虫而言,自动爬取后两种的网页数据就无能为力了,一般是对前两种验证码策略的应对。
随机数字图片验证码,又可以细分很多小类型,需要根据不同的类型采取不同的策略。比如,字母/数字组合类型(Z5f0ty)、计算题类型(1+5=?),这种简单的验证码可通过机器学习识别。又比如,图片验证类型,这种复杂的验证码可通过专门的付费打码平台人工打码。
滑动验证码,采用的是高精度人机行为识别技术,用户只需向右滑动拼图,补齐缺块儿,即可完成验证,这种可以使用 Selenium 模拟浏览器执行滑动操作。
1.7 动态网页
有时候,我们使用 requests 模块获取网页内容会很少,并且也不包含我们采集的目标数据,这是因为页面展示的实时信息是动态渲染的,比如股票行情实时的数据、证券交易公开的数据等。面对这种动态的网页,使用 requests 模块就不再适合了。
我们使用浏览器的【开发者工具】定位看到的数据,有可能是动态渲染过的,也有可能不是。那么,该如何识别网页上的数据是不是动态渲染的呢?方法很简单,通过右键点击网页空白处,选择【查看网页源代码】,将页面上的数据复制后去源代码里搜索,如果搜索不到则可以判定是动态渲染的!应对这种反爬策略,我们仍可以选择使用 Selenium 模拟浏览器操作获取数据。
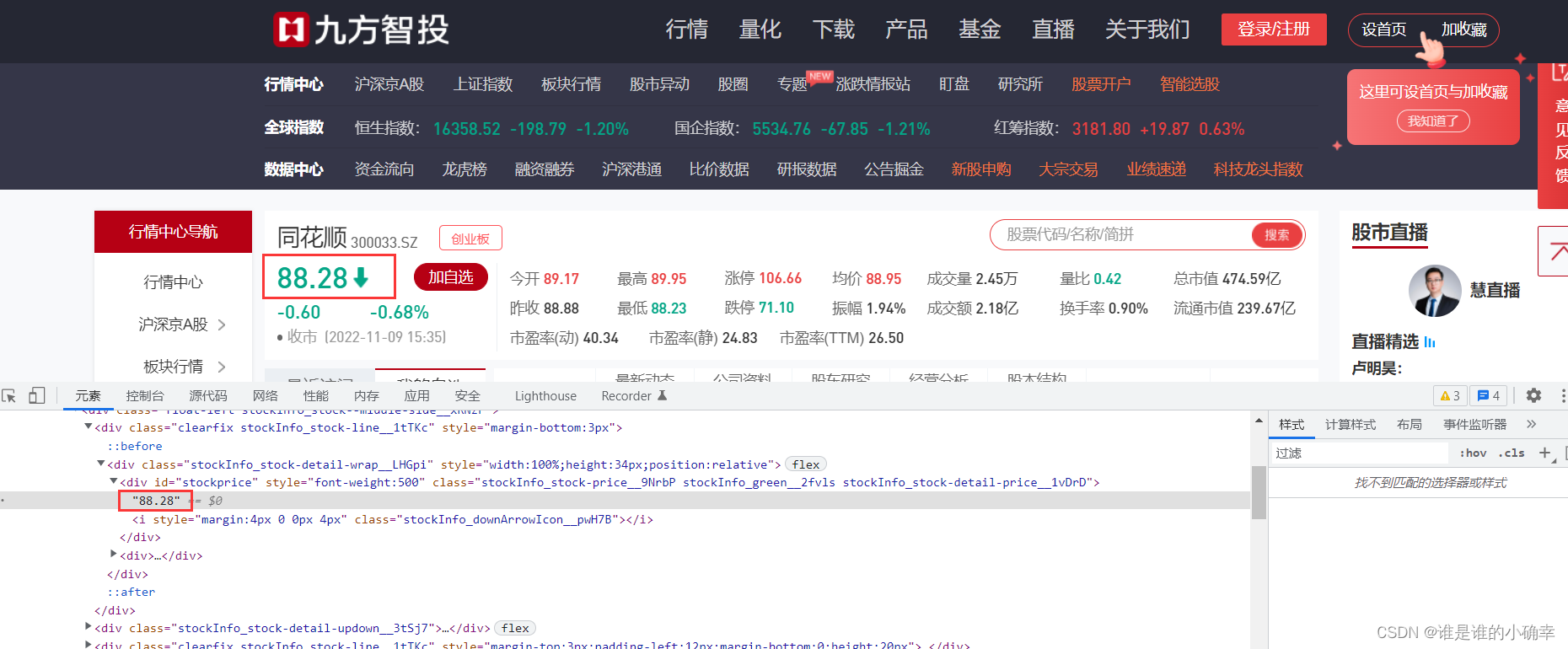
我们随便搜索一个财经网站测试下,通过【开发者工具】能看到 88.28 指数是存在的,如下:
去【查看网页源代码】搜索 88.28 ,显示这个指数不存在:
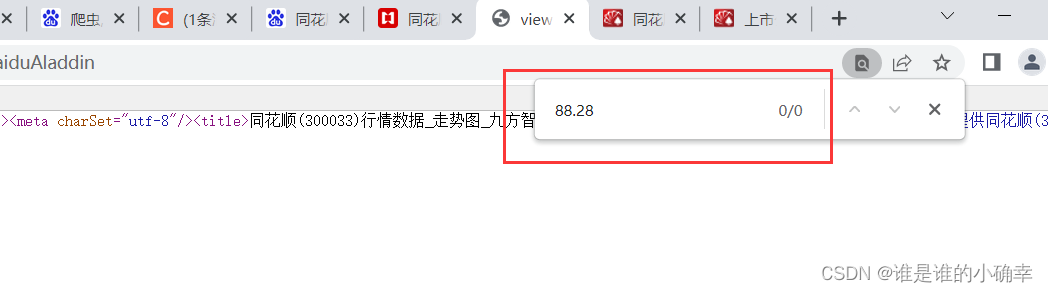
说明当前网页是动态渲染的,可以考虑使用 Selenium 模块去爬取。
1.8 数据API加密
爬虫和反爬虫本质上是一种攻防关系,如果网站真心不让你爬取自己的页面数据,则会使用难度更大,破解更复杂的反爬策略。
比如,前端 JS 加密。网站花了一番心思的加密操作,相对于爬取方来说,也是需要一定时间和分析能力才能进行解密,极大的增加了爬取的难度。
又比如,网站使用多个不同的字体文件加密,只有使用约定的字体文件方式才能解密。网站服务端根据字体映射文件,先将客户端查询的数据进行转换再传给前端,前端根据字体文件进行逆向解密,映射方式可以自由选择,比如数字乱序显示等。这样爬虫可以正常爬取,但得到的数据却是错误的!
所谓的道高一尺,魔高一丈,恐怕不过如此吧,哈哈哈~
2、Selenium模块
2.1 选择 Requests 还是 Selenium ?
从上面介绍的反爬应对策略不难发现,当 Requests 模块解决不了的爬取问题,使用 Selenium 模块基本可以解决。到这里可能会产生疑问:这两个模块都是爬虫的核心库,为什么不直接使用 Selenium 替代 Requests 做所有的爬虫操作呢?
这是因为 Requests 模块是直接访问网页,爬取速度非常快,而 Selenium 模块要先打开模拟浏览器再访问网页,爬取速度相对较慢。实际使用中,肯定会优先考虑使用 Requests 模块,而 Requests 模块解决不了的话再使用 Selenium 模块。
如果说 Requests 模块可以爬取50%的网站,那么 Selenium 模块可以爬取95%的网站,大部分爬取难度较高的网站都可以用它爬取。
2.2 Selenium 该怎么用?
Selenium 是一个用于 Web 应用程序测试的工具,它能够驱动浏览器模拟用户的操作,比如鼠标点击、键盘输入等行为,支持的浏览器包括 IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge 等。通过 Selenium 模块能比较容易地获取网页源代码,还能自动下载网络资源。
首先,需要下载 Selenium 模块,如下:
pip install selenium接着,下载和安装浏览器驱动程序,不同的浏览器驱动下载地址,参考如下(按需选择):
- Edge:Microsoft Edge WebDriver - Microsoft Edge Developer
- Chrome:https://chromedriver.storage.googleapis.com/index.html
- Firefox:Releases · mozilla/geckodriver · GitHub
- Safari:WebDriver Support in Safari 10 | WebKit
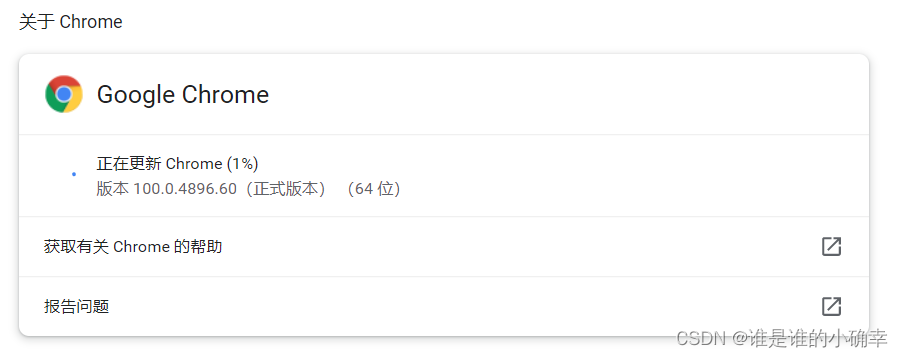
下载的浏览器驱动需要与当前使用的浏览器版本保持一致,我用的是 Google 浏览器,通过【设置】--【关于 Chrome】,可以查看版本号:
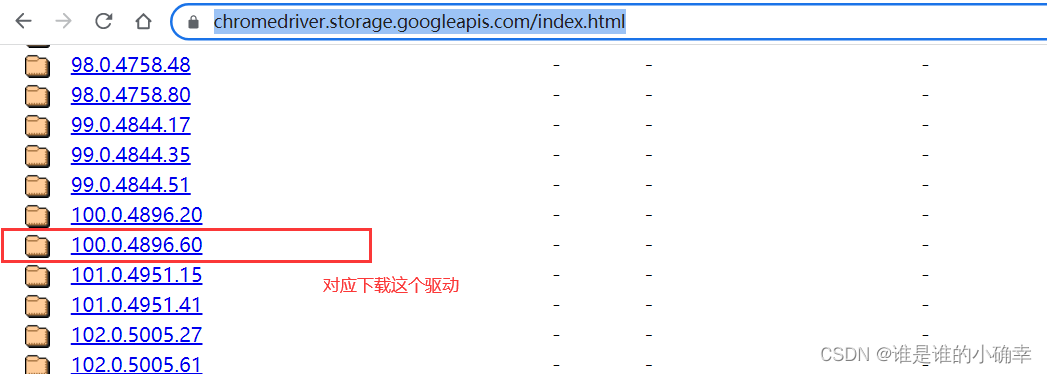
找到自己需要的驱动路径,下载:
下载完成后,解压 zip 包会得到一个 chromedriver.exe,将这个可执行文件放到 Python 的 Scripts 目录下就完成了安装。验证是否成功安装驱动,可以打开 CMD,输入命令,验证如下:

到此,万事俱备,就可以小试牛刀了。
打开 Google 浏览器,并访问百度的首页,在获取网页源代码后,等待30s,最后关闭浏览器。以这个操作流程为例,测试代码如下:
from selenium import webdriver
def test_open_browser(url):
# 打开 Google 浏览器
browser = webdriver.Chrome()
# 访问目标网址
browser.get(url)
# 获取网页源代码
data = browser.page_source
# 休眠30s(智能等待)
browser.implicitly_wait(30)
# 关闭浏览器
browser.quit()这样就能轻松获取网页源代码数据了。如果不需要弹出模拟浏览器窗口,就能获取网页源代码,可启用无界面浏览器模式(Chrome Headless),在打开 Google 浏览器的代码之前,新增和修改如下代码:
co = webdriver.ChromeOptions()
co.add_argument('--headless')
browser = webdriver.Chrome(options=co)browser 还有更多 API 可以自行尝试,接下来会进行一些用法总结。
2.3 Selenium 操作模拟浏览器小结
除了访问网页,Selenium 模块还可以进行其他行为操作。该模块 API,常用的属性有:
- browser.window_handles:获取浏览器所有窗口的句柄
- browser.current_window_handle:获取当前浏览器窗口的句柄
- browser.name:获取当前浏览器驱动的名称
- browser.page_source:获取网页源代码
- browser.title:获取当前网页的标题
- browser.current_url:获取当前网页的网址
常用的操作方法有:
- browser.maximize_window():窗口最大化
- browser.minimize_window():窗口最小化
- browser.set_window_size(width, height):设置窗口尺寸
- browser.forword():前进
- browser.back():后退
- browser.
switch_to_frame("f1"):切换到内嵌框架(用法即将废弃) - browser.switch_to.frame("f1"):切换到内嵌框架
- browser.
switch_to_window("w1"):切换到内嵌窗口(用法即将废弃) - browser.switch_to.window("w1"):切换到内嵌窗口(一般与browser.window_handles搭配使用)
- browser.get_cookies():获取当前网页用到的cookies
- browser.refresh():刷新当前网页
- browser.close():关闭浏览器
- browser.find_element_by_xxx("").send_keys():模拟键盘输入
- browser.find_element_by_xxx("").click():点击对象
- browser.find_element_by_xxx("").submit():提交对象的内容
- browser.find_element_by_xxx("").text:获取文本信息
- browser.find_element_by_xxx("").clear():清除对象的内容
find_element_by_xxx() 用于定位网页元素,有很多使用方法,如下:

注意:
如果xxx是xpath的话,格式为:
browser.find_element_by_xpath('XPath表达式')
如果xxx是css_selector的话,格式为:
browser.find_element_by_css_selector('CSS选择器')
实际使用中,二者都常用来定位网页元素,根据需要进行选择。
XPath 如何使用?
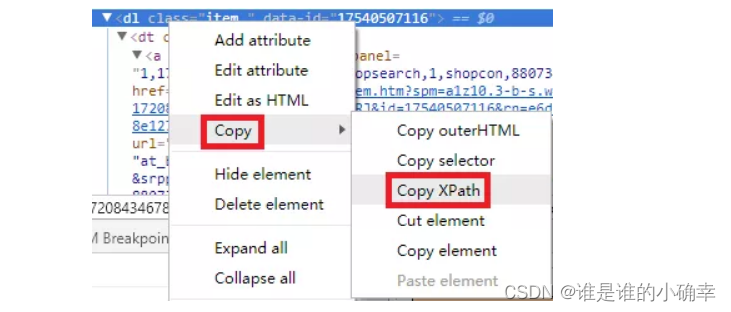
XPath 可理解为网页元素的名字或 ID。find_element_by_xpath() 函数可根据 XPath 表达式定位网页元素,利用开发者工具,可获取网页元素的XPath表达式,如下:
键盘事件:包括键盘tab、回车、ctrl键等
from selenium.webdriver.common.keys import Keys
# Tab 切换到密码框
browser.find_element_by_class_name("username").send_keys(Keys.TAB)
# ENTER 回车登陆
browser.find_element_by_class_name("password").send_keys(Keys.ENTER)
# 全选、复制、剪切等
browser.find_element_by_name("input").send_keys(Keys.CONTROL, 'a')
browser.find_element_by_name("input").send_keys(Keys.CONTROL, 'c')
browser.find_element_by_name("input").send_keys(Keys.CONTROL, 'x')鼠标事件:包括鼠标右键、双击、拖动、移动鼠标到某个元素上等
from selenium.webdriver.common.action_chains import ActionChains
elem = browser.find_element_by_xpath("")
# 鼠标点击行为
ActionChains(browser).click(elem).perform() # 单击,默认左击
ActionChains(browser).double_click(elem).perform() # 双击
ActionChains(browser).context_click(elem).perform() # 右击
ActionChains(browser).click_and_hold(elem).perform() # 单击并停留
# 鼠标拖动
to_elem = browser.find_element_by_xpath("")
ActionChains(browser).drag_and_drop(elem, to_elem).perform()
ActionChains(browser).move_to_element(elem).perform() # 鼠标悬停
ActionChains(browser).move_by_offset(x, y).perform() # 鼠标移动,需要指定x,y轴的偏移量Expected Conditions:期望的条件,可用来判断浏览器的动态页面元素出现和消失情况,经常与 WebDriverWait 搭配使用,通过以下方式引入:
from selenium.webdriver.support import expected_conditions as EC常用 API 有:
title_is:判断当前页面的 title 是否精确等于预期;title_contains:判断当前页面的 title 是否包含预期字符串;presence_of_element_located:判断某个元素是否被加到了 dom 树里,并不代表该元素一定可见;visibility_of_element_located:判断某个元素是否可见.可见代表元素非隐藏,并且元素的宽和高都不等于0;visibility_of:跟上面的方法做一样的事情,只是上面的方法要传入 locator,这个方法直接传定位到的 element 就好了;presence_of_all_elements_located:判断是否至少有1个元素存在于 dom 树中。举个例子,如果页面上有n个元素的 class 都是 'column-md-3',那么只要有1个元素存在,这个方法就返回 True;text_to_be_present_in_element:判断某个元素中的 text 是否包含了预期的字符串;text_to_be_present_in_element_value:判断某个元素中的 value 属性是否包含了预期的字符串;frame_to_be_available_and_switch_to_it:判断该 frame 是否可以 switch 进去,如果可以的话,返回 True 并且 switch 进去,否则返回 False;invisibility_of_element_located:判断某个元素中是否不存在于 dom 树或不可见;element_to_be_clickable:判断某个元素中是否可见并且是 enable 的,这样的话才叫 clickable;staleness_of:等某个元素从 dom 树中移除,注意,这个方法也是返回 True 或 False;element_to_be_selected:判断某个元素是否被选中,一般用在下拉列表;element_selection_state_to_be:判断某个元素选中状态是否符合预期;element_located_selection_state_to_be:跟上面的方法作用一样,只是上面的方法传入定位到的 element,而这个方法传入 locator;alert_is_present:判断页面上是否存在 alert。
最后
至此,爬虫入门的知识点也介绍完了,有了这些基础知识后,便可以进一步的进行爬虫实战了。后面将通过爬虫实战,演示如何灵活的爬取不同网站并解析出目标数据,并记录下爬取和解析过程中遇到的一些问题,一起期待吧~