Hash碰撞
什么是Hash碰撞
Hash碰撞是指两个不同的输入值,经过哈希函数的处理后,得到相同的输出值,这种情况被称之为哈希碰撞。
- 例如:两个不同的对象(object1和object2的值)经过Hash函数计算后的,得到的hash值相同,object2应放到object1的位置,但是存储桶中的位置已经被object1占用了,导致冲突
哈希函数是
为什么会发生Hash碰撞
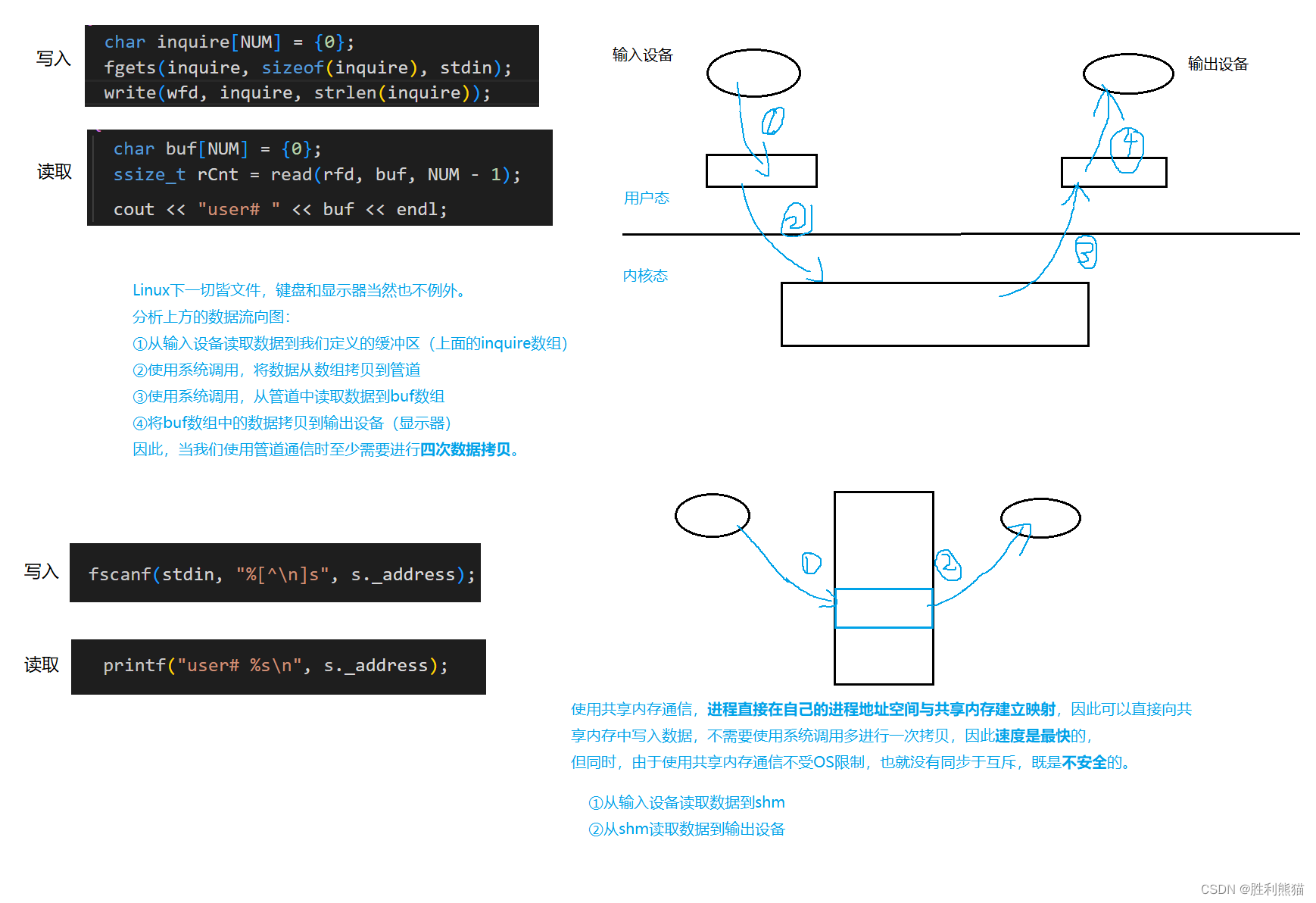
哈希表是一种数据结构,它使用哈希函数将键映射到存储桶中。哈希函数将键转换为索引,这个索引指向哈希表中的一个桶。哈希表的目的是提供一种快速的查找方法,它可以在较快的时间内查找一个键。
当然,这需要一个好的哈希函数,它可以将键均匀地分布在哈希表中。如果哈希函数不好,就会出现哈希碰撞,这会导致性能下降。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fULBcw7u-1683776857310)(E:\Java笔记\Java优化\Hash\Hash碰撞\Hash碰撞.assets\image-20230511110034878.png)]](https://img-blog.csdnimg.cn/18edc2be413e4b4c8d97199a43b589d3.png)
解决Hash碰撞
在这种情况下,我们可以使用链式哈希表来解决哈希碰撞的问题。链式哈希表是一种将哈希值相同的元素存储在同一个链表中的哈希表。当发生哈希碰撞时,我们只需要将新元素添加到对应的链表中即可。这样可以保证哈希表的性能和正确性。
package com.sin.demo;
import java.util.LinkedList;
/**
* @CreateName SIN
* @CreateDate 2023/05/11 11:04
* @description 链式哈希表,用来解决hash碰撞的问题。
* 具体实现:将hash值相同的元素存储在同一个链表中,当发生hash碰撞时,
* 只需要将新的元素添加到对应的链表中即可,这样可以保证hash表的新能和正确性
*/
public class ChainedHashTable<K, V> {
//声明一个链表数组
private LinkedList<Entry<K, V>>[] table;
//记录长度
private int size;
/**
* 构造方法
* @param capacity 传入hash表容量
*/
public ChainedHashTable(int capacity) {
//初始化链表数组长度
table = new LinkedList[capacity];
//初始长度为0
size = 0;
}
/**
* 添加元素
* @param key 键
* @param value 值
*/
public void put(K key, V value) {
//计算哈希值
int index = hash(key);
//如果当前索引位置为null
if (table[index] == null) {
//创建一个新的链表在当前索引
table[index] = new LinkedList<>();
}
// 遍历当前索引的链表
for (Entry<K, V> entry : table[index]) {
//判断链表中是否有这个key键,
if (entry.getKey().equals(key)) {
//如果有则更新对应的value值
entry.setValue(value);
//直接返回
return;
}
}
//如果不存在将新的元素(键值对)添加到链表中
table[index].add(new Entry<>(key, value));
//增加长度
size++;
}
/**
* 获取元素
* @param key 键
* @return 返回对应的值
*/
public V get(K key) {
//计算hash值
int index = hash(key);
//如果当前值为null
if (table[index] == null) {
//返回null
return null;
}
//遍历该位置的链表
for (Entry<K, V> entry : table[index]) {
//判断链表中是否有这个key键,
if (entry.getKey().equals(key)) {
//存在则返回元素的值
return entry.getValue();
}
}
//否则返回null
return null;
}
/**
* 删除元素
* @param key 所需要删除的key
* @return false:删除失败,true:删除成功
*/
public boolean remove(K key) {
//计算hash值
int index = hash(key);
//如果当前位置为null
if (table[index] == null) {
//返回false
return false;
}
//遍历该位置的链表
for (Entry<K, V> entry : table[index]) {
//判断链表中是否有这个key键,
if (entry.getKey().equals(key)) {
//从链表中删除该元素
table[index].remove(entry);
//减小长度
size--;
//返回true
return true;
}
}
//返回false
return false;
}
/**
* 获取长度
* @return 返回长度
*/
public int size() {
return size;
}
/**
* 计算hash值
* @param key 键
* @return 返回自定义的hash值(可按照自己的规则编写)
*/
private int hash(K key) {
//绝对值并取模
return Math.abs(key.hashCode()) % table.length;
}
/**
* 静态内部类
* @param <K>
* @param <V>
*/
private static class Entry<K, V> {
//key,键
private K key;
//value,值
private V value;
/**
* 构造方法
* @param key 传入的key
* @param value 传入的值
*/
public Entry(K key, V value) {
//初始化键和值
this.key = key;
this.value = value;
}
// 获取键
public K getKey() {
// 返回键
return key;
}
// 获取值
public V getValue() {
// 返回值
return value;
}
// 设置值
public void setValue(V value) {
// 更新值
this.value = value;
}
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XdBDF8ea-1683776857311)(E:\Java笔记\Java优化\Hash\Hash碰撞\Hash碰撞.assets\image-20230511113659169.png)]](https://img-blog.csdnimg.cn/9ae929fbcaf6476899e6b0126578ae18.png)
解析:
| 方法 | 返回值 | 说明 |
|---|---|---|
| ChainedHashTable | 构造方法,创建对象时需要传入具体的长度 | |
| put | void | 添加元素,先计算key的hash值,判断是否有这个key,没有新建一个l链表并添加到数组元素的末尾。有则更新对应的value |
| get | V | 获取元素,先计算key的hash值,判断是否有这个key,没有则返回null,然后遍历链表,有则返回对应的value,没有返回null |
| remove | boolean | 删除元素,先计算key的hash值,判断是否有这个key,没有则返回false,然后遍历链表,有则删除对应的value,没有返回false |
| size | int | 获取长度 |
| hash | int | 计算hash值 |
代码持续开发中:不合理之处,可指导指导!!!







![[学习笔记] [机器学习] 4. [下]线性回归(正规方程、梯度下降、岭回归)](https://img-blog.csdnimg.cn/bc773cd7b94f4a9f93a484e5e7c7ce0c.png#pic_center)