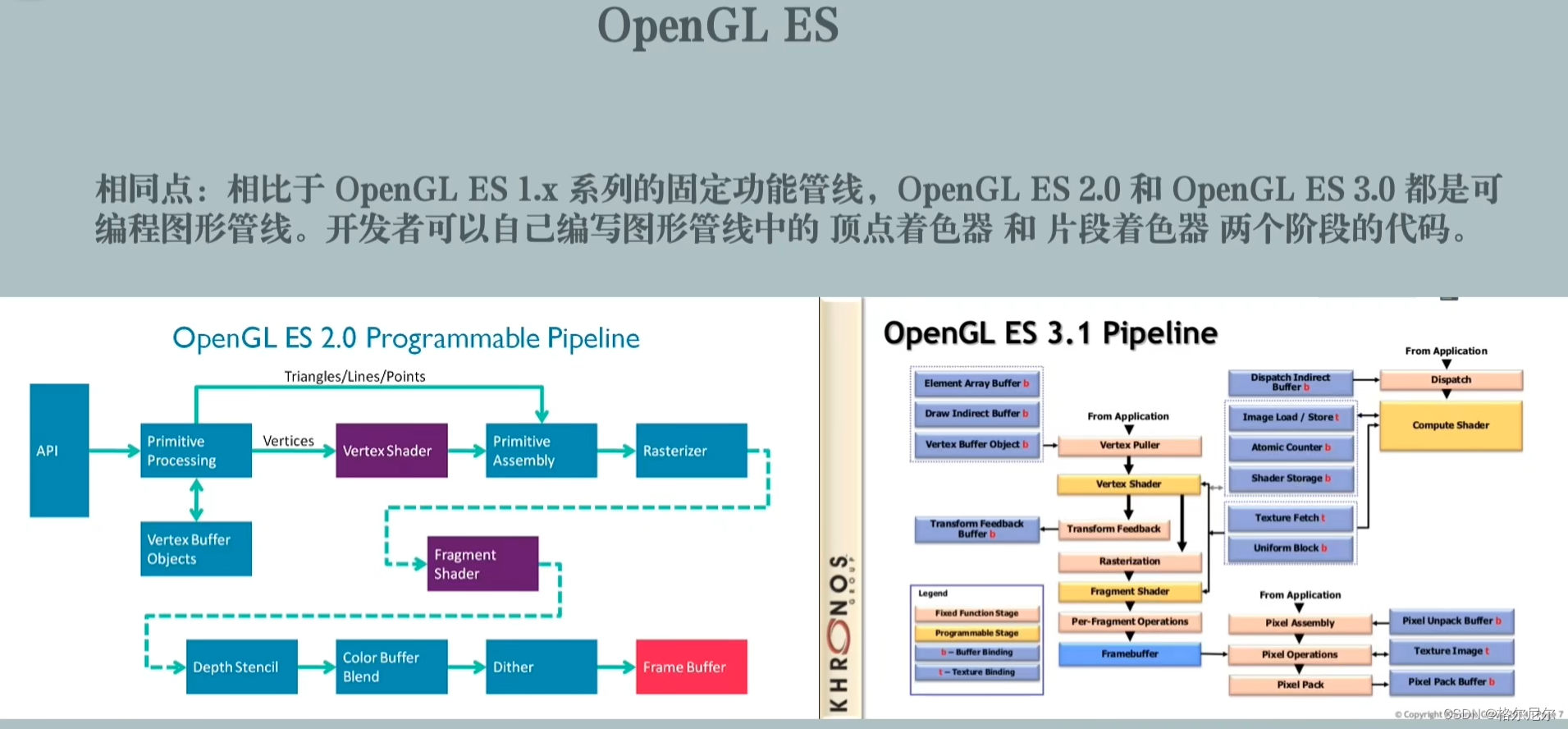
深度学习很难。 虽然通用逼近定理表明足够复杂的神经网络原则上可以逼近“任何东西”,但不能保证我们可以找到好的模型。
尽管如此,通过明智地选择模型架构,深度学习取得了巨大进步。 这些模型架构对归纳偏差进行编码,为模型提供帮助。 最强大的归纳偏差之一是利用几何概念,从而产生了几何深度学习领域。
几何深度学习(geometric deep learning)这个术语最早是由该领域的先驱 Michael Bronstein 创造的(有关许多最新深度学习研究的有趣见解以及该领域的广泛概述,请参阅他的帖子)。 在这篇文章中,我们没有深入技术细节,而是对几何深度学习进行了非常简短的介绍。 我们主要遵循 Bronstein 及其同事最近出版的优秀著作 ,但提供了我们自己的独特见解,并专注于高级概念而不是技术细节。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、几何先验
从根本上说,几何深度学习涉及将对数据的几何理解编码为深度学习模型中的归纳偏差,以助其一臂之力。
我们对世界的几何理解通常通过三种类型的几何先验进行编码:
- 对称性和不变性
- 稳定
- 多尺度表示
最常见的几何先验之一是将对称性和不变性编码为不同类型的变换。 在物理学中,对称性通常由物理系统在变换下的不变性来表示。 如果我们知道现实世界表现出某些对称性,那么将这些对称性直接编码到我们的深度学习模型中是有意义的。 这样我们就可以给模型一个很大的帮助,这样就不必学习对称性,但在某种意义上已经知道了。 在我们之前的文章What Einstein Can Teach Us About Machine Learning中进一步阐述了在深度学习中利用对称性。
作为编码对称性和不变性的一个例子,传统的卷积神经网络 (CNN) 表现出所谓的平移等变性,如下图猫脸所示。 考虑模型的特征空间(右侧)。 如果相机或猫移动,即在图像中平移,则特征空间中的内容应该更相似,即也平移。 此属性称为平移等变性,在某种意义上确保只需要学习一次模式(猫的脸)。 不必在所有可能的位置学习模式,通过在模型本身中编码平移等方差,我们确保可以在所有位置识别模式。
上图给出平移等方差的说明。 给定一张图像(左上),计算特征图(通过𝒜)(右上)然后平移(𝒯)特征图(右下)相当于先平移图像(左下)然后计算特征图 (右下角)。

另一个常见的几何先验是保证表示空间的稳定性。 我们可以将数据实例之间的差异视为由于将一个数据实例映射到另一个数据实例的某种失真。 例如,对于分类问题,较小的失真是导致类内变化的原因,而较大的失真可以将数据实例从一个类映射到另一个类。 两个数据实例之间的失真大小然后捕获一个数据实例与另一个数据实例的“接近”或相似程度。 为了使表示空间表现良好并支持有效的深度学习,我们应该保留数据实例之间的相似性度量。 为了保持表示空间中的相似性,特征映射必须表现出稳定性。
作为一个代表性的例子,考虑手写数字的分类。 原始图像空间及其表示空间如下图所示。 小的扭曲将一个 6 映射到另一个,捕获手绘 6 的不同实例之间的类内变化。在代表性空间中,这些数据实例应该保持接近。 然而,较大的失真可以将 6 映射为 8,从而捕获类间变化。 同样,在表示空间中应该保留相似性度量,因此表示空间中的 6s 和 8s 之间应该有更大的分离。 需要特征映射的稳定性以确保保留此类距离以促进有效学习。
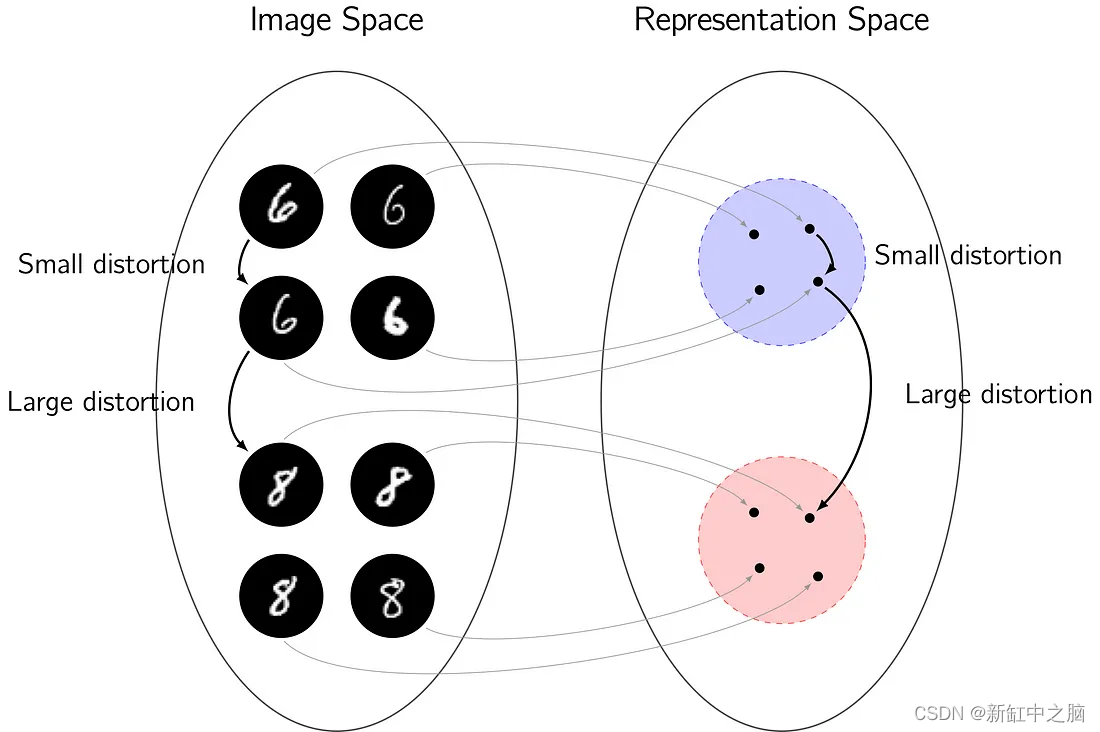
上图为映射到表示空间的稳定性说明。 小的失真是类内变化的原因,而大的失真是类间变化的原因。 需要映射的稳定性来确保数据实例之间的相似性度量,即它们之间的失真大小,保留在表示空间中,以促进有效学习。参考文献 。
第三种常见的几何先验是对数据的多尺度、分层表示进行编码。 在数据实例中,许多数据不是独立的,而是以复杂的方式相互关联。 以图像为例。 每个图像像素不是独立的,而是附近的像素通常是相关的并且非常相似。 根据内容结构,“附近”的不同概念也是可能的。 因此,可以通过捕获大量数据的多尺度、分层性质来构建有效的表示空间。

以标准的二维图像为例,如下图所示的城堡图像。 下图显示了图像的多尺度、分层表示,左上角是原始图像的低分辨率版本,然后是在图表的其他面板中捕获的不同分辨率的剩余图像内容。 这提供了更有效的底层图像表示,事实上,这是支持 JPEG-2000 图像压缩的技术。 可以利用类似的多尺度、分层表示来为学习提供有效的表示空间。
上图为图像的多尺度、分层表示。 原始图像的低分辨率版本显示在左上角,然后在图表的其他面板中捕获不同分辨率的剩余图像内容。 可以利用类似的表示来为学习提供有效的表示空间。
我们已经涵盖了几何深度学习中利用的三种主要类型的几何先验。 虽然这些提供了几何学习的基本概念,但它们可以应用于许多不同的设置。
2、几何深度学习的类别
在 Bronstein 的新书中,几何深度学习被分为四个基本类别,如下图所示。
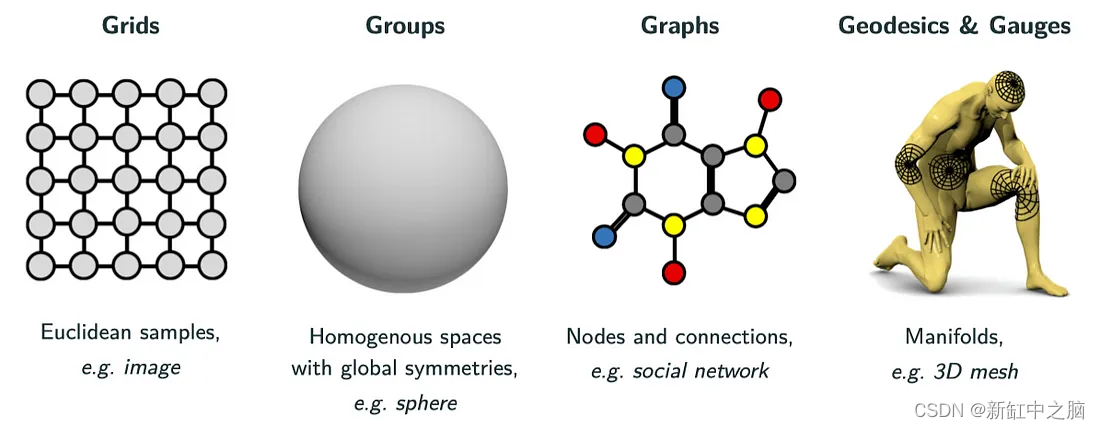
Bronstein 谈到 5G(扩展了 Max Welling [1] 首次引入的 4G 分类):Grid、Group、Graph、Geodesics & Gauges。 由于这最后两个 G 密切相关,我们只考虑四个不同的类别,即 4G。
Grid分类捕获定期采样或网格化的数据,例如 2D 图像。 这些数据可能通常是经典深度学习的产物。 然而,也可以从几何角度解释许多经典的深度学习模型(例如 CNN 及其平移等方差,如上所述)。
Group分类涵盖具有全局对称性的同质空间。 这个类别的典型例子是球体(在我们之前的文章中有更详细的介绍)。 球形数据出现在 myrad 应用程序中,不仅在直接在球体上获取数据时(例如在地球上空或通过捕捉全景照片和视频的 360° 相机),而且在考虑球形对称性时(例如在分子化学或磁学中 共振成像)。 虽然球体是最常见的组设置,但也可以考虑其他组及其相应的对称性。
Graph分类涵盖可由具有节点和边的计算图表示的数据。 网络非常适合这种表示,因此图深度学习在社交网络的研究中得到了广泛的应用。 几何深度学习的图形方法提供了极大的灵活性,因为很多数据都可以用图形表示。 然而,这种灵活性可能伴随着特异性的丧失和所提供的优势。 例如,Group设置通常可以用图形方法来考虑,但在这种情况下,人们会失去组的基础知识,否则可以利用这些知识。
最后的Geodesics & Gauges分类涉及对更复杂形状的深度学习,例如更通用的流形管和 3D 网格。 这种方法在计算机视觉和图形学中有很大的用处,例如,人们可以在其中使用 3D 模型及其变形进行深度学习。
3、几何深度学习的构建块
如上所述,虽然有许多不同类别的几何深度学习,以及可以利用的不同类型的几何先验,但所有几何深度学习方法本质上都采用以下基本基础构建块的不同化身。

深度学习架构通常由多个层组成,这些层组合在一起形成整体模型架构。 然后经常重复层的组合。 几何深度学习模型通常包括以下类型的层。
- 线性等变层:几何深度学习模型的核心组成部分是线性层,例如卷积,它们与某些对称变换是等变的。 需要为所考虑的几何类别构造线性变换本身,例如 球体和图形上的卷积是困难的,尽管通常有很多类比。
- 非线性等变层:为确保深度学习模型具有足够的表示能力,它们必须表现出非线性(否则它们只能表示简单的线性映射)。 必须引入非线性层来实现这一点,同时还要保持等方差。 以等变方式引入非线性的规范方法是通过逐点非线性激活函数(例如 ReLU)来实现,尽管有时会考虑专门针对底层几何形状定制的其他形式的非线性 [3]。
- 局部平均:大多数几何深度学习模型还包括一种局部平均形式,例如 CNN 中的最大池化层。 此类操作在某些尺度上施加局部不变性,确保稳定性并通过堆叠多个层块来实现多尺度、分层表示。
- 全局平均:为了在几何深度学习模型中施加全局不变性,通常使用全局平均层,例如 CNN 中的全局池化层。
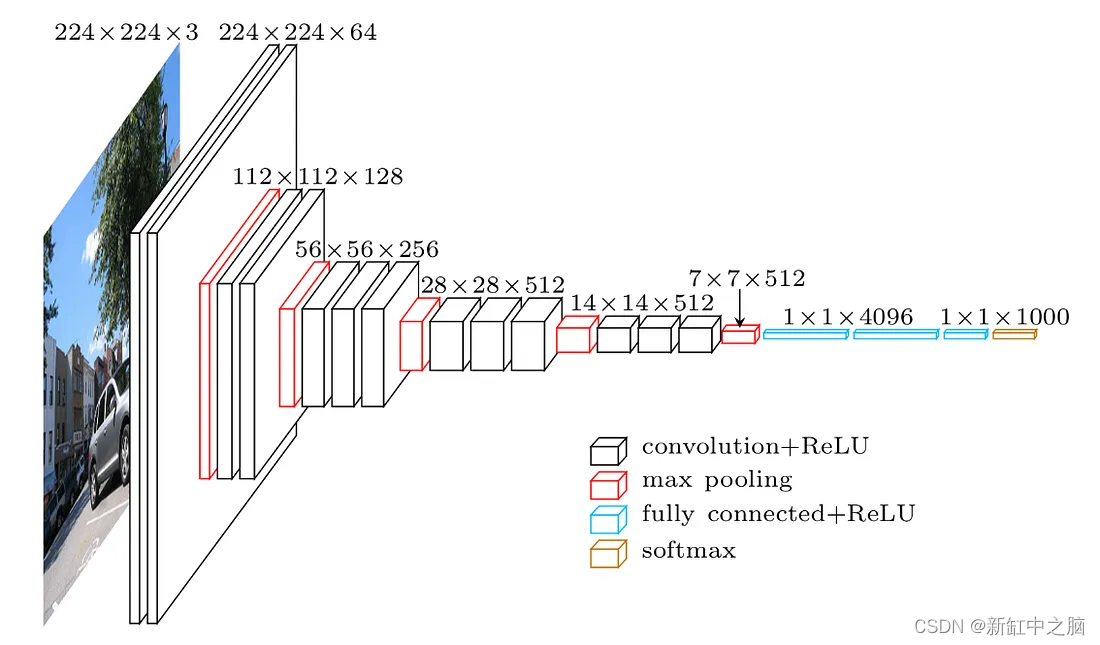
几何深度学习模型的典型示例是用于 2D 平面图像的传统 CNN。 虽然许多人可能认为这是一个经典的深度学习模型,但它可以从几何角度进行解释。 事实上,CNN 如此成功的关键原因之一是其架构中编码的几何特性。 下图概述了一个典型的 CNN 架构VGG-16,其中很明显包含了上面讨论的许多几何深度学习层,层块重复以提供分层的、多尺度的表示空间。
4、未来展望
深度学习现在对于标准类型的数据很常见,例如结构化数据、顺序数据和图像数据。 然而,为了将深度学习的应用扩展到其他更复杂的——几何数据集,这些数据的几何结构必须在深度学习模型中进行编码,从而产生了几何深度学习领域。
几何深度学习是一个热门且发展迅速的领域,已经取得了很大进展。 然而,许多未解决的问题仍然存在,不仅在模型本身,而且在可扩展性和实际应用方面。 我们将在接下来的文章中解决这些问题,展示解决这些问题对于为大量新应用程序释放深度学习的巨大潜力至关重要。
原文链接:几何深度学习 — BimAnt