文章目录
- 添加spark的jar包
- main传参调试
- 打包成jar包
- 发送到Hadoop运行
- 使用脚本运行
- 参考
添加spark的jar包
点击Project Structure
Global Libararies中
点击+
选择java
然后选择spark文件里的jars下所有的jar包
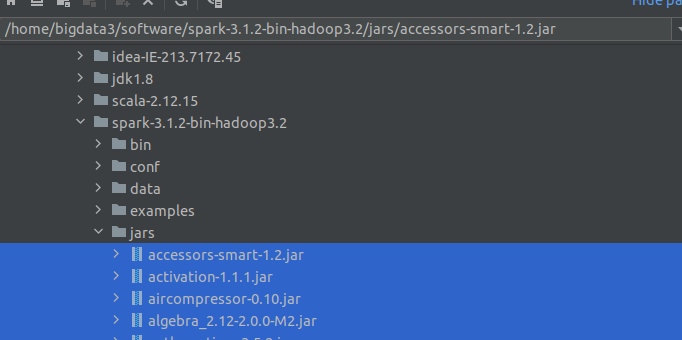
然后点击ok即可。
main传参调试
首先给出词频统计代码
//包
import org.apache.spark.{SparkContext, SparkConf}
object testMainInput {
def main(args: Array[String]): Unit = {
if(args.length < 2){println(args.length);println("Please input 2 args, return"); return}
val conf = new SparkConf().setAppName("spark1").setAppName("icy hunter").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile(args(0), 4)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.saveAsTextFile(args(1))
sc.stop()
}
}
此时可以测试一下传参效果。
idea调试时,main参数输入:菜单->run->Edit Configurations:
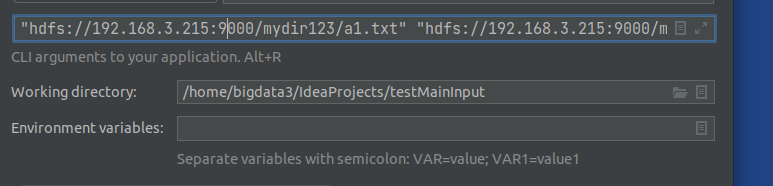
这就是传入的两个参数。
可以调试的时候试试。
打包成jar包
首先需要修改代码,将setMaster(“local[*]”)删了
//包
import org.apache.spark.{SparkContext, SparkConf}
object testMainInput {
def main(args: Array[String]): Unit = {
if(args.length < 2){println(args.length);println("Please input 2 args, return"); return}
val conf = new SparkConf().setAppName("spark1").setAppName("icy hunter")
val sc = new SparkContext(conf)
sc.textFile(args(0), 4)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.saveAsTextFile(args(1))
sc.stop()
}
}
project structure中如下选项
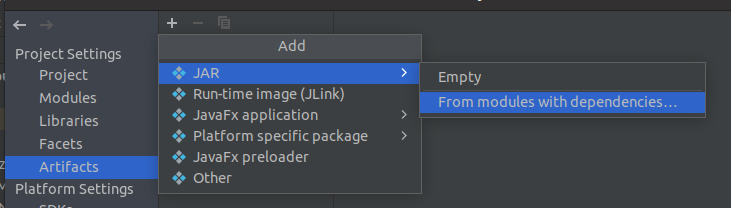
进入
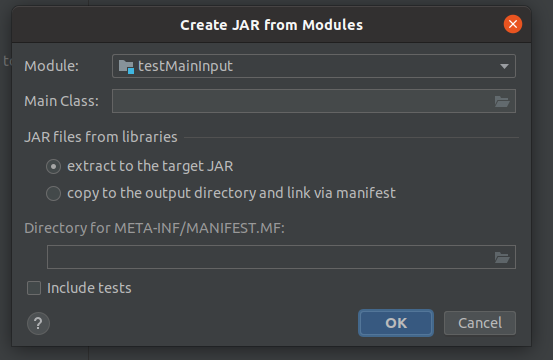
Main Class点击文件夹标志选择
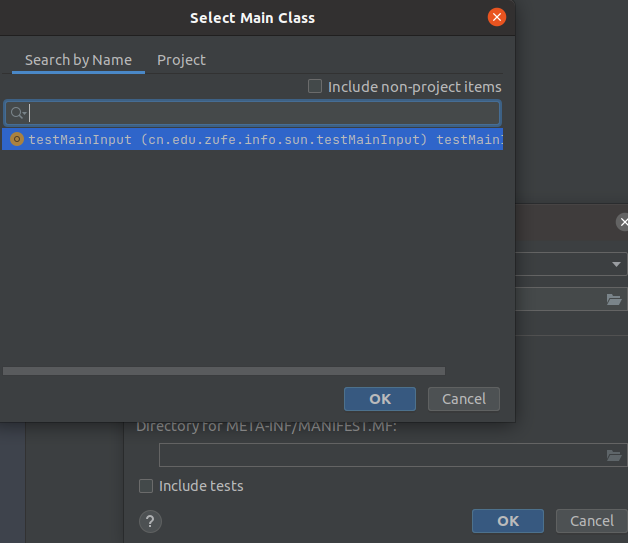
点击ok
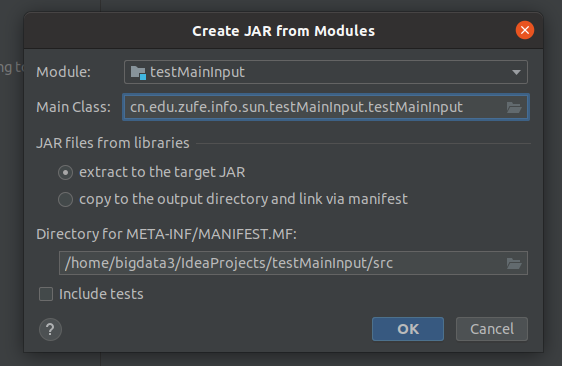
点击ok
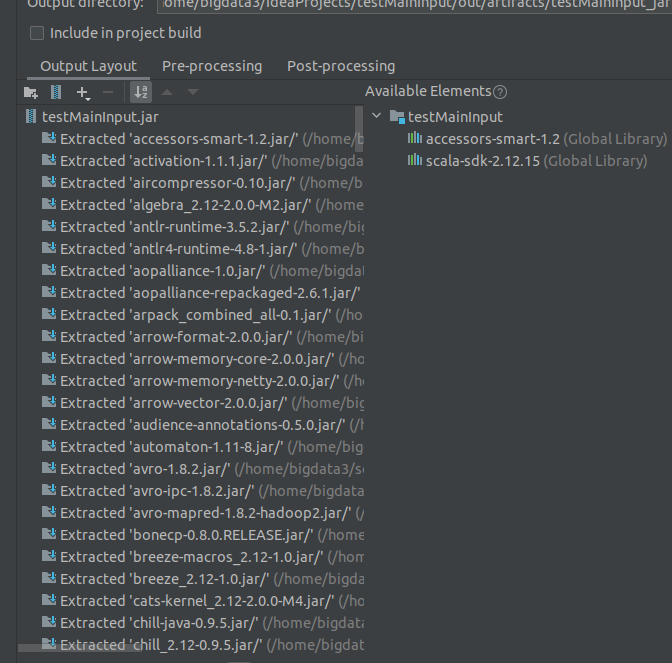
然后需要进行瘦身,把不需要的包删了,这样打包出来就比较小了。
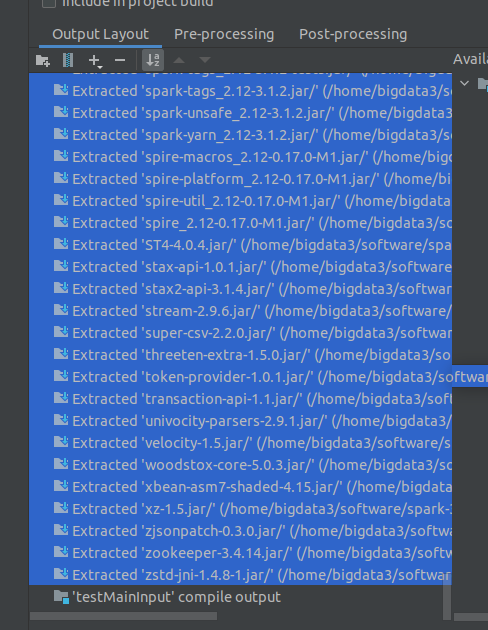
点击-号,这些全删了,留最后一个compile output即可。
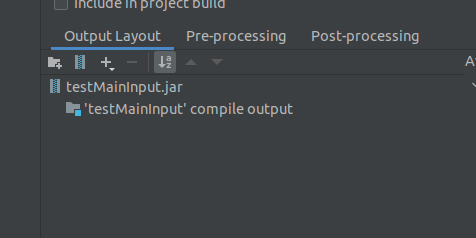
然后ok了。

同时点击一下,我们也可以看到打包后存放的路径
接下来开始打包:
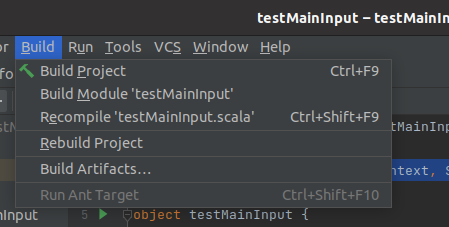
点击build Artifacts
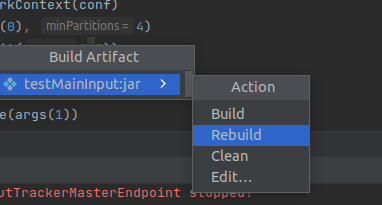
跳出这个,点击rebuild即可。
这样就打包完成了。
发送到Hadoop运行
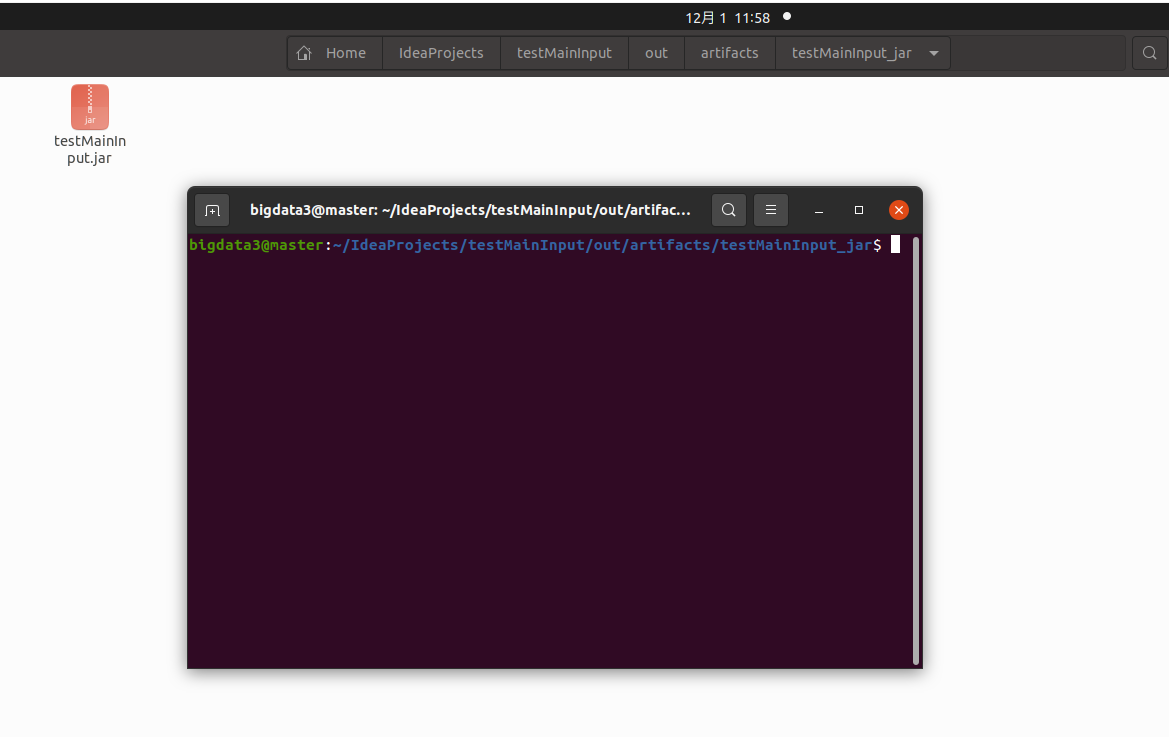
首先找到jar包位置
打开终端
spark-submit --master yarn --deploy-mode cluster testMainInput.jar "hdfs://192.168.3.215:9000/mydir123/a1.txt" "hdfs://192.168.3.215:9000/mydir123/out3"
其中路径得你自己集群的文件路径才能运行成功。
使用脚本运行
创建一个脚本文件
vim show.sh
然后输入:
echo Start spark-submit:
spark-submit --master yarn --deploy-mode cluster /home/bigdata3/IdeaProjects/testMainInput/out/artifacts/testMainInput_jar/testMainInput.jar "hdfs://192.168.3.215:9000/mydir123/a1.txt" "hdfs://192.168.3.215:9000/mydir123/out4"
注意jar包的路径得全路径了。
然后可以
bash show.sh
直接运行
也可以
chmod +x show.sh
给予可执行权限
然后
./show.sh
进行运行
参考
上课笔记