Acceptance-Rejection Sampling
文章目录
- Acceptance-Rejection Sampling
- @[toc]
- 1 接受拒绝采样
- 2 Acceptance-Rejection 采样实现
文章目录
- Acceptance-Rejection Sampling
- @[toc]
- 1 接受拒绝采样
- 2 Acceptance-Rejection 采样实现
1 接受拒绝采样
给定随机变量
X
X
X服从pdf为
f
(
x
)
f(x)
f(x)的分布,例如
f
(
x
)
f(x)
f(x)为正态概率密度函数,我们可以通过相关统计软件自动生成满足特定分布的样本数据。假如
f
(
x
)
f(x)
f(x)不服从正态分布,而是服从如下这种比较复杂的分布该如何进行观测采样呢?
X
∼
f
(
x
)
=
s
i
n
(
x
2
)
+
c
o
s
(
x
)
+
2
∫
a
b
s
i
n
(
x
2
)
+
c
o
s
(
x
)
+
2
d
x
,
x
∈
[
a
,
b
]
X\sim f(x) = \dfrac{sin(x^2)+cos(x)+2}{\int_{a}^{b}sin(x^2)+cos(x)+2 dx},x\in[a,b]
X∼f(x)=∫absin(x2)+cos(x)+2dxsin(x2)+cos(x)+2,x∈[a,b]
此外,我们还要基于所采样的样本计算相关统计量,例如一阶矩、二阶矩等,这需要计算更为复杂的函数积分,又该如何计算?针对上述一系列问题,数学中衍生出接受拒绝采样(Acceptance-Rejection Sampling),该方法采用了Monte Carlo思想。
已知存在如下概率密度函数
f
(
x
)
f(x)
f(x),随机变量
X
∼
f
(
x
)
X\sim f(x)
X∼f(x),
x
∈
[
a
,
b
]
x\in[a,b]
x∈[a,b]

为了获得服从 f ( x ) f(x) f(x)的随机样本,引入一个均匀分布,随机变量 Y ∼ U ( a , b ) Y\sim U(a,b) Y∼U(a,b),对应的概率密度函数为 g ( y ) = 1 b − a g(y) = \dfrac{1}{b-a} g(y)=b−a1

将概率密度曲线
g
(
y
)
g(y)
g(y)向上平移,直至存在最小的常数
c
c
c,使得对于任意来源于
g
(
x
)
g(x)
g(x)的样本值
x
x
x都有
c
g
(
x
)
=
c
b
−
a
≥
f
(
x
)
cg(x) = \dfrac{c}{b-a}\ge f(x)
cg(x)=b−ac≥f(x)

现在假设已经获得来源于
g
(
x
)
g(x)
g(x)的一个样本值
x
∗
x^*
x∗,构建如下比例
z
=
f
(
x
∗
)
c
g
(
x
∗
)
∈
[
0
,
1
]
z = \dfrac{f(x^*)}{cg(x^*)}\in[0,1]
z=cg(x∗)f(x∗)∈[0,1]

若 z z z值越大,表明目标分布 f ( x ∗ ) f(x^*) f(x∗)与均匀分布 g ( x ) g(x) g(x)越靠近,此时选择或承认 x ∗ x^* x∗(来源于均匀分布 g ( x ) g(x) g(x))这个样本值作为目标分布 f ( x ) f(x) f(x)的一个采样的概率就越大。如果选择承认 x ∗ x^* x∗是 f ( x ) f(x) f(x)的一个样本采集,那就接受 x ∗ x^* x∗。
那么,给定一个 z z z值,如何判断对应的 x ∗ x^* x∗是否接受呢?再引入随机变量 u ∼ U ( 0 , 1 ) u\sim U(0,1) u∼U(0,1),并从该均匀分布获得一个样本值 u ∈ [ 0 , 1 ] u\in[0,1] u∈[0,1],如果 z z z值较大,那么 z > u z>u z>u的概率也较大。显然,如果 x ∗ x^* x∗越接近0(上图中),那么选择接受 x ∗ x^* x∗附近的观测频率就越高。通过对 g ( x ) g(x) g(x)大量的样本观测采集,将 z z z值与 u u u值进行比较,就可得到目标分布函数的样本近似观测。
上述 g ( x ) g(x) g(x)又称为建议分布(proposal distribution),顾名思义就是从 g ( x ) g(x) g(x)中获得一个样本观测 x ∗ x^* x∗,建议 f ( x ) f(x) f(x)的样本是否采用 x ∗ x^* x∗,如果建议,则接受,反之拒绝。上文说的建议分布 g ( x ) g(x) g(x)服从均匀分布,事实上,可以选择其他分布, g ( x ) g(x) g(x)满足接近 f ( x ) f(x) f(x)且覆盖 f ( x ) f(x) f(x)区域,Acceptance-Rejection Sampling效率越高。
强行总结下,实现Acceptance-Rejection Sampling步骤如下:
1)目的:已知较为复杂的目标分布 f ( x ) f(x) f(x),需要从 f ( x ) f(x) f(x)进行样本采集;
2)构建建议分布G,选择密度函数为均匀分布的 g ( x ) = 1 b − a g(x) =\dfrac{1}{b-a} g(x)=b−a1;
3)寻找最小常数 c c c,使得 c g ( x ) = c b − a ≥ f ( x ) cg(x) = \dfrac{c}{b-a}\ge f(x) cg(x)=b−ac≥f(x);
4)再获得一个随机变量 u ∼ U ( 0 , 1 ) u\sim U(0,1) u∼U(0,1);在计算机模拟中就是获得一个在(0,1)上的随机数;
5)从 g ( x ) g(x) g(x)中获得 x ∗ x^* x∗,并计算 z = f ( x ∗ ) c g ( x ∗ ) z = \dfrac{f(x^*)}{cg(x^*)} z=cg(x∗)f(x∗);
6)if z > u z>u z>u则接受 x ∗ x^* x∗;else 拒绝
7)重复步骤4-6,直至得到预期样本量 n n n
2 Acceptance-Rejection 采样实现
给定如下概率密度函数,对其进行样本采样
f
(
x
)
=
s
i
n
(
x
2
)
+
c
o
s
(
x
)
+
2
∫
a
b
s
i
n
(
x
2
)
+
c
o
s
(
x
)
+
2
d
x
,
x
∈
[
a
,
b
]
f(x) = \dfrac{sin(x^2)+cos(x)+2}{\int_{a}^{b}sin(x^2)+cos(x)+2 dx},x\in[a,b]
f(x)=∫absin(x2)+cos(x)+2dxsin(x2)+cos(x)+2,x∈[a,b]
假设
a
=
−
10
,
b
=
10
a=-10,b=10
a=−10,b=10。对该密度函数可视化,由于分母是常数,只需看分子的图像即可。
g = function(x) sin(x^2)+cos(x)+2
par(mfrow = c(1,1))
curve(g,n=1000,from = -10,to = 10)
# 这里的int即为最小常数c
int = integrate(g,-10,10)$value
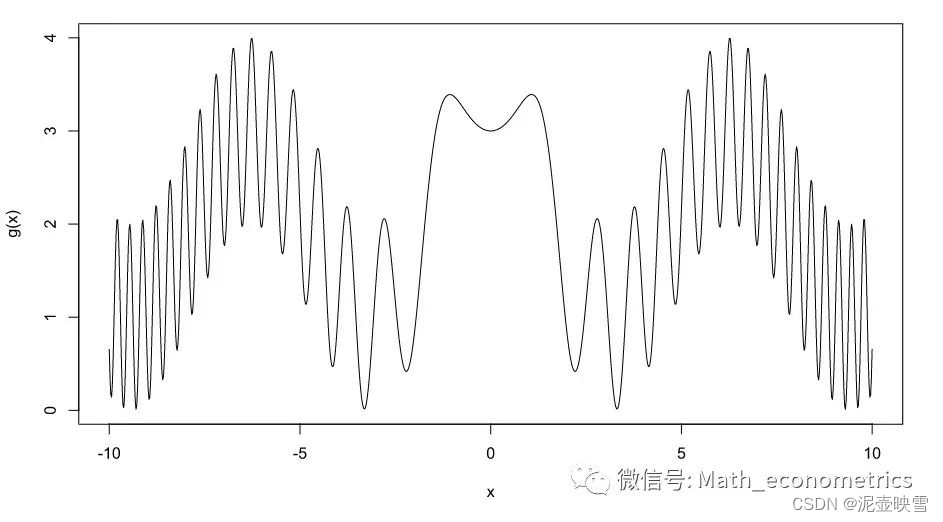
该密度函数是对称函数,具有多峰性。下面分别采集100,1000,10000和20000样本量
n = c(100,1000,10000,20000)
par(mfrow = c(2,2))
for(i in 1:4){
k = 0
x = numeric()
while(k < n[i]){
# 均匀分布
u = runif(1)
# 从建议分布获得x*
y = runif(1,-10,10)
# 判断
if((sin(y^2)+cos(y)+2)/int > u){
cat('Accept',k,'\n')
k = k + 1
x[k] = y
}else{
cat('Reject',k,'\n')
}
cat('=====😁=====',k,'=====😁=====\n')
}
# 绘制直方图
hist(x,prob=T,col = 'red',breaks = seq(-10,10,0.1),
main = paste('n=',n[i]))
X = seq(-10,10,0.01)
# 真实密度曲线
Y = (sin(X^2)+cos(X)+2)/int
lines(X,Y,lwd = 3)
}
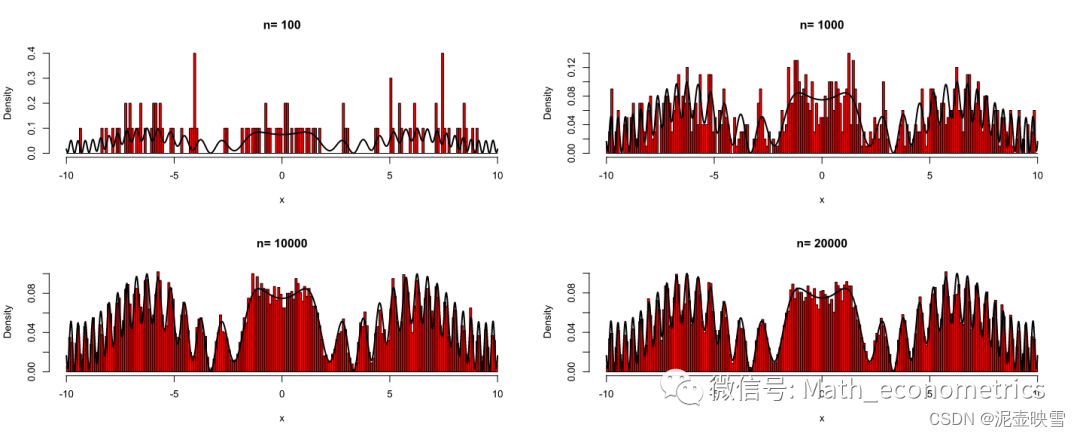
上图可以发现随着样本采集次数越多,对目标分布的近似采集效果越好。