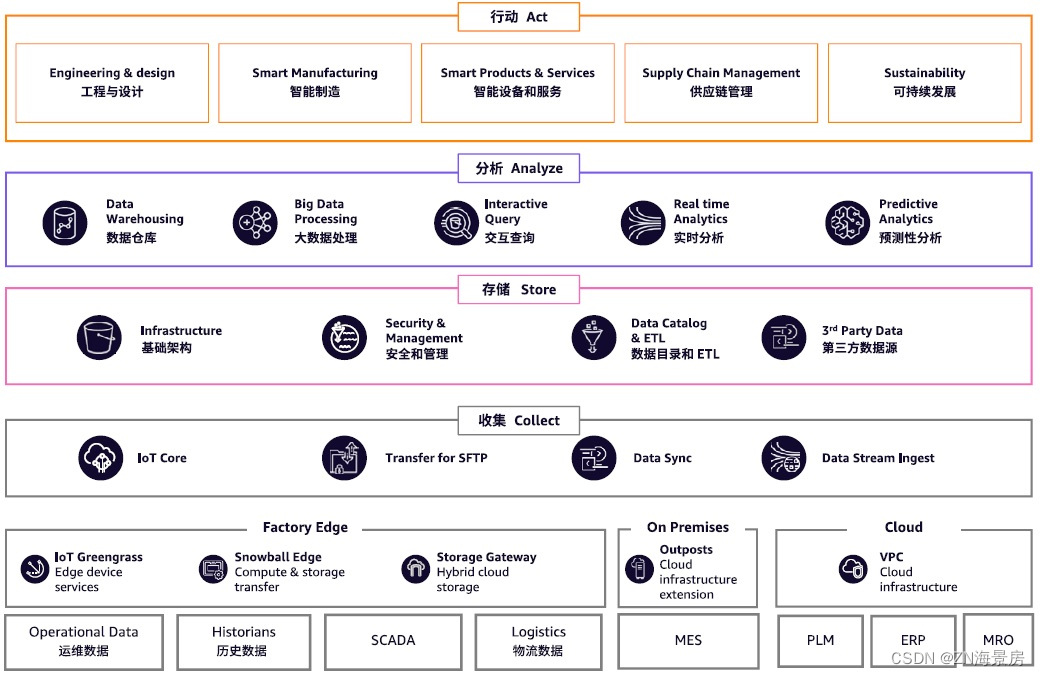
文章目录
为什么发生哈希冲突(哈希碰撞) 能否完全避免哈希冲突 常用处理哈希冲突的方法 1.开放地址法 1.1线性探测再散列
1.2二次探测再散列 1.3伪随机探测再散列 2.再哈希地址法 3.链地址法 4.建立公共溢出区
当向hash表中存放数据时,会使用hash函数计算出对应的hash函数值,即哈希地址,所以会出现不同关键字具有相同hash函数值,即不同数据具有同一hash地址的情况,这个时候就发生了哈希冲突。
虽然可以选择不同的哈希函数去避免冲突的产生,但是数据量增长,始终会产生哈希冲突,因此只能尽量减少。
开放地址法 再哈希地址法 链地址法 建立公共溢出区 当产生哈希冲突时,就在哈希表中寻找另一个空的位置存放关键字。如何寻找另一个空的位置,也有不同的规则。
线性探测再散列 二次探测再散列 伪随机探测再散列 当发生哈希冲突时,即某一位置已放了关键字,会查询下一个位置上是否是空的,空的便放入,否则再下一个位置尝试放入直到解决冲突。每次查询下一个未冲突的位置的增量d为1、2、3、4…(不断自增),即不断加上增量d,从而寻找下一个空的位置。
35关键字放在0位置 74关键字放在4位置 02关键字放在2位置 31关键字放在3位置 39关键字应放在(39/7 = 5…4)4位置,但4位置已有关键字,则根据线性探测,下一个空的位置为5,则将39关键字放在5位置 类似的情况,98关键字由于0位置已被占用,顺延一位至1位置 99关键字应放入1位置,但由于前面位置均已被占用,跳过已占有的所有位置,找到最近的空位,被放入6位置 100关键字同理 0 1 2 3 4 5 6 7 8 9 35 98 02 31 74 39 99 100
发现当表中i、i+1、i+2位置上已经填有记录时,下一个哈希地址为i、i+1、i+2、i+3的关键字,都将先填入i+3位置,这种解决哈希冲突过程中,发生的两个第一哈希地址不同的记录,争夺同一个后继哈希地址的现象称之为 二次聚集 ,显然数据量大了后,后续探测距离会特别长,线性探测会造成二次聚集,这对查找不利,但是这也可以保证只要哈希表未填满,总能找到一个不发生哈希冲突的地址。
二次探测再散列也是类似的思路,一旦将填入的位置已有关键字,便会根据规则寻找下一个未被占用的位置,即不断加上增量d,从而寻找下一个空的位置。但规则区分于自增的线性探测,增量d为12 、-12 、22 、-22 、32 、-32 …
39关键字应放在4位置,但4位置已有关键字,则根据增量d=12 ,放在4+1=5,5位置上 98关键字由于0位置已被占用,根据增量d=12 =1,放在1位置 99关键字应放入1位置,但1已被占用,根据增量d=12 =1,放入(1+1)2位置,但2已占用,继续下一个增量d=-12 ,放入(1-1)0位置,但0已占用。d= 22 = 4,放入(1+4)5位置,但5已占用,继续下一个增量。d= -22 已越界,继续下一个增量d= 32 = 9,放入(1+9)10位置 0 1 2 3 4 5 6 7 8 9 10 35 98 02 31 74 39 99
100关键字,尝试放入位置为2、(+1)3、(-1)1、(+4)6 0 1 2 3 4 5 6 7 8 9 10 35 98 02 31 74 39 100 99
二次探测再散列使用并不多,因为当增量d非常大时,每一个跨度都非常大,需要跨过很多空地址。
取决于伪随机数列
当产生哈希地址冲突时,使用另一个不同的哈希函数计算哈希函数地址直到冲突不再产生。这不容易产生聚集,但会有计算时间的额外开销。
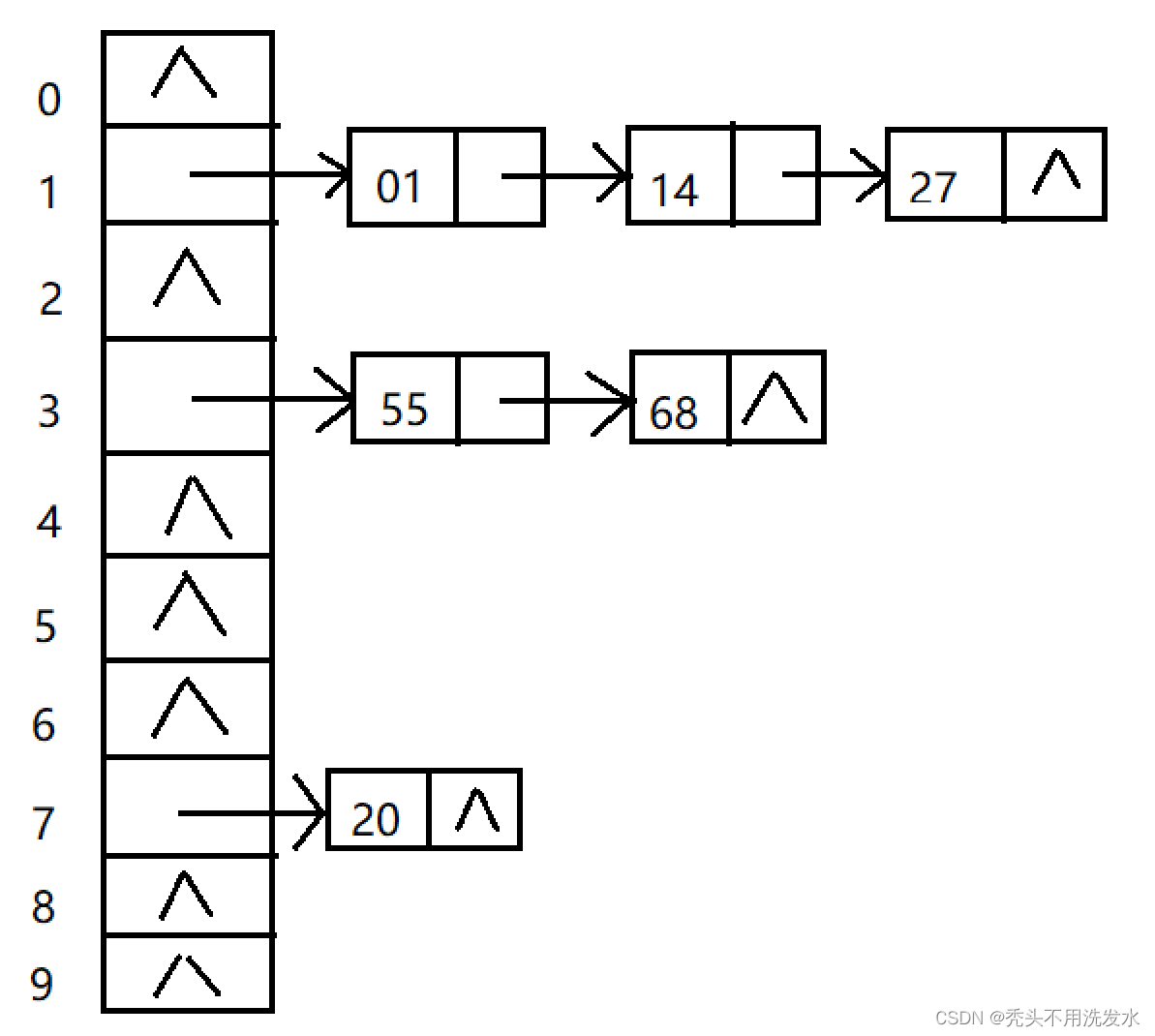
建立一个单链表(同一线性链表),链表上的数据均为相同的哈希地址x,该链表中的数据插入位置可以在头尾或中间,保持同意立案表中按关键字有序,将同一链表的头指针放在哈希表中x的位置。
建立溢出表和基本表,出现与基本表有冲突的数据,无论哈希函数计算得到的哈希地址是什么,一旦发生冲突,都填入溢出表。会有额外的空间开销。