ConcurrentHashMap的数据结构是什么?
ConcurrentHashMap仅仅是HashMap的线程安全版本,针对HashMap的线程安全优化,所以HashMap有的特点ConcurrentHashMap同意具有, ConcurrentHashMap的数据结构跟HashMap是一样的。
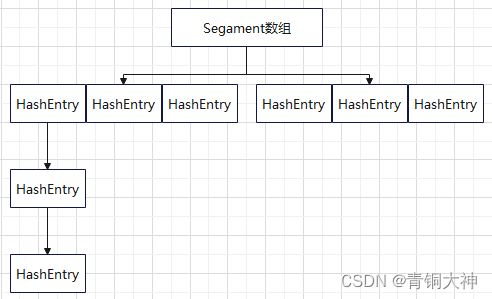
在JDK7版本使用数组+链表的结构。具体来说是使用了Segment数组 + HashEntry数组 + HashEntry链表,看起来就像是Segment数组 + HashMap的结构,线程安全精确到分段数组的每个节点。在保证Map线程安全的前提下,尽量提升吞吐量。
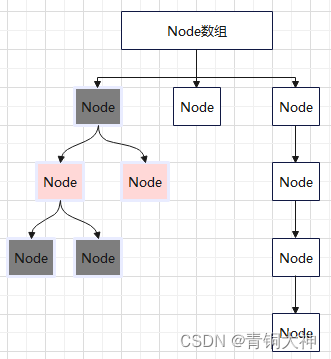
在JDK8版本使用数组+链表/红黑树的结构。放弃了Segment数组和HashEntry数组。
ConcurrentHashMap如何保证线程安全?
JDK7版本是使用Segment将一个table数组分解成多个Segment数组,Segment又是由多个链表构成的。而put方法,会从头到尾再加上锁。
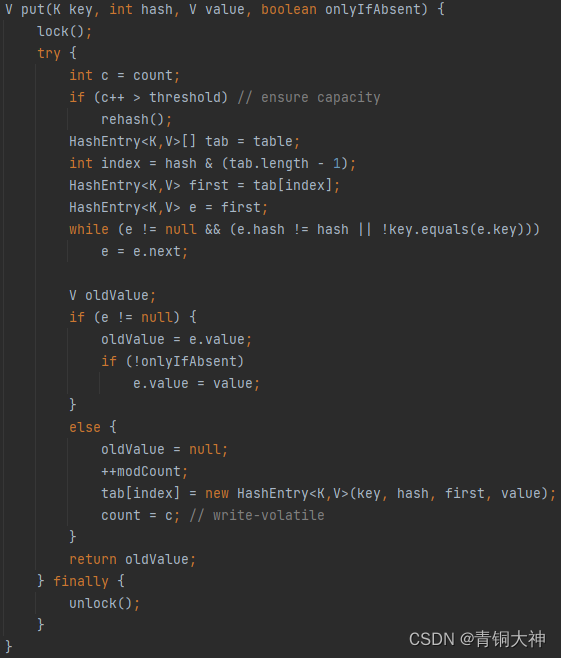
1.8版本是使用synchronized关键字修饰具体执行数据插入的部分,这是跟Hashtable很大的不同,而且这个锁是加在table上的头节点上的,不影响。
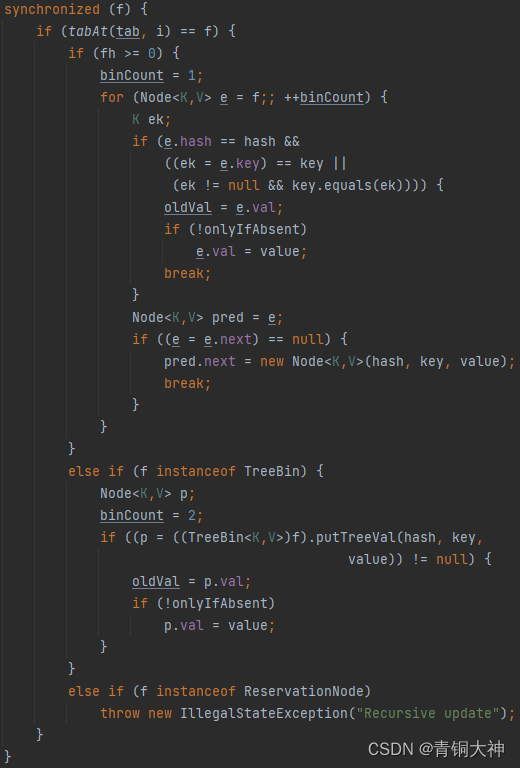
同样是线程安全的HashMap,为什么ConcurrentHashMap要比HashTable效率高?
HashTable的线程安全实现方式较为粗暴,采用了将所有的方法都使用synchronized关键字修饰,而ConcurrentHashMap的线程安全在JDK7版本是采用的分段锁的方式来实现的,在JDK8版本中是采用CAS + synchronized方式实现的。从这段描述中就能看出,HashTable的锁粒度都是方法级的,而ConcurrentHashMap的锁粒度更小。
既然ConcurrentHashMap那么好,为什么还需要HashTable?
ConcurrentHashMap效率高是因为他牺牲了一定的安全性的基础上达到的。在执行扩容时,put会阻塞,而get会去获取老数据,这样就产生了数据不一致的问题。而这种情况HashTable是不会发生的,因为他是全表锁。
ConcurrentHashMap1.8版本的sizeCtl是干什么用的?
sizeCtl的作用是标注数组数组状态:
- 0表明数组未初始化;
- 负数且小于-1,表明此时有|N + 1|个线程正在对数组进行扩容;
- 正数存在两种情况:在数组未初始化时,sizeCtl表明数组的初始容量;在数组已初始化时,sizeCtl表明数组的扩容阈值;
- -1表明数组正在被初始化;

ConcurrentHashMap什么时候用链表,什么时候用红黑树?
默认是用链表存储的。在table的长度大于64且Node链表长度大于等于8的时候会将链表转成红黑树。在红黑树节点数量小于等于6时,将红黑树转成链表。
为什么树化的阈值和链表化的阈值不同呢?
大概是为了避免当节点长度处于7个的时候,增删节点造成反复转换存储结构吧。







![[PyTorch]Onnx模型格式的转换与应用](https://img-blog.csdnimg.cn/3dd78a8428d64038b7bc06d3980df8b5.png)