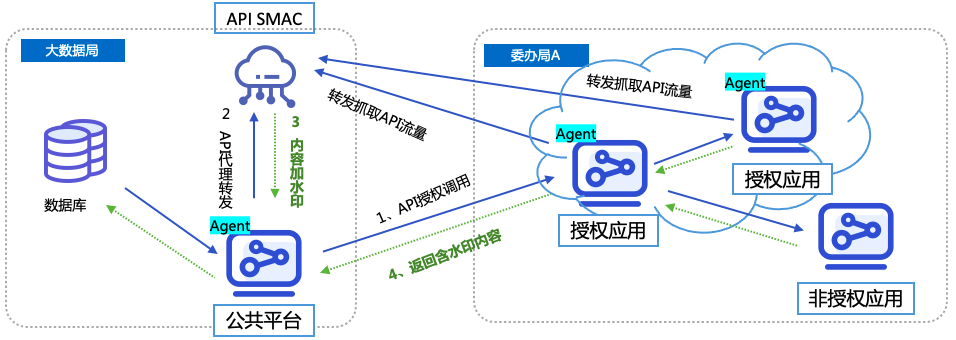
前言
上一篇介绍了 MySQL 的表分区和分库分表,这一篇将介绍主从架构相关的内容。
主从架构
常见的主从架构模式有四种:
- 一主多从架构:适用于读大于写的场景,采用多个从库来分担数据库系统的读压力。
- 多主架构:适用于读写参半的场景,采用多个主库来承载数据库系统整体的读写压力。
- 多主一从架构:适用于写大于读的场景,采用多个主库分担写压力,单个从库承载读压力。
- 级联复制架构:适用于读大于写的场景,采用单个从节点来分担从库对主库造成的 I/O 压力。
接下来的讨论都是针对最常见的一主多从架构。
主从架构中必须有一个主节点,以及一个或多个从节点,所有的数据都会先写入到主,接着其他从节点会复制主节点上的增量数据,从而保证数据的最终一致性,使用主从复制方案,可以进一步提升数据库的可用性和性能:
- 在主节点宕机或故障的情况下,从节点能自动切换成主节点的身份,从而继续对外提供服务。
- 提供数据备份的功能,当主节点的数据发生损坏时,从节点中依旧保存着完整数据。
- 可以基于主从实现读写分离,主节点负责处理写请求,从节点处理读请求,进一步提升性能。
但无论任何技术栈的主从架构,都会存在致命硬伤,同时也会存在些许问题需要解决:
- 硬伤:木桶效应,一个主从集群中所有节点的容量,受限于存储容量最低的哪台服务器。
- 数据一致性问题:由于同步复制数据的过程是基于网络传输完成的,所以存储延迟性。
- 脑裂问题:从节点会通过心跳机制,发送网络包来判断主机是否存活,网络故障情况下会产生多主。
主从复制
MySQL 集群的主从复制过程梳理成 3 个阶段:
- 写入 Binlog:主库更新本地存储数据,并写 binlog 日志,然后提交事务。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog:回放 binlog,并更新存储引擎中的数据。

具体详细过程如下:
- MySQL 主库在收到客户端提交事务的请求之后,会先更新数据;
- 数据写入完成后,再去写入 binlog,然后提交事务,返回客户端“操作成功”的响应;
- 主节点上有一条专门监听 binlog 的 log dump 线程;
- 当 log dump 线程监听到日志发生变更时,会通知从节点来拉取数据;
- 从节点有专门的 I/O 线程(io_thread)用于等待主节点的通知,当收到通知时会去请求一定范围的数据;
- 当从节点在主节点上请求到数据后,会将得到的数据写入到 relay-log 中继日志,然后返回给主库“复制成功”的响应;
- 从节点上有专门负责监听 relay-log 变更的线程(sql_thread),当日志出现变更时会开始工作;
- 中继日志出现变更后,会从中读取日志记录,然后回放 binlog 更新数据,实现主从数据一致性。
复制模式
同步复制
MySQL 主库提交事务的线程要等待所有从库的复制成功响应,才返回客户端结果。这种方式在实际项目中,基本上没法用,原因有两个:一是性能很差,因为要复制到所有节点才返回响应;二是可用性也很差,主库和所有从库任何一个数据库出问题,都会影响业务。
异步复制
是 MySQL 默认使用的复制模式,MySQL 主库提交事务的线程并不会等待 binlog 同步到各从库,就返回客户端结果。这种模式一旦主库宕机,数据就会发生丢失。
半同步复制
MySQL 5.7 版本之后增加的一种复制方式,介于两者之间,事务线程不用等待所有的从库复制成功响应,只要一部分复制成功响应回来就行,比如一主二从的集群,只要数据成功复制到任意一个从库上,主库的事务线程就可以返回给客户端。这种半同步复制的方式,兼顾了异步复制和同步复制的优点,即使出现主库宕机,至少还有一个从库有最新的数据,不存在数据丢失的风险。
增强式半同步复制
也被称为无损复制,也是 MySQL5.7 引入的。和之前传统的半同步复制区别在于:从 after-commit 变成了 after-sync ,如果将复制模式配置成半同步时,默认就会选用无损复制模式。
- after-commit:主库在未收到从库的 ACK 之前,虽然不会给客户端返回写入成功,但本质上会提交事务,也就是主库中的其他事务是可以看见对应数据的,当此时出现宕机时,就会导致旧主上能查询出的数据,在新主上无法查询出来了。
- after-sync:当主库未收到从库的 ACK 之前,也不会在主库上提交事务,也就是保证了主从节点的数据强一致性,解决了 after-commit 中存在的问题。但是相较于 after-commit,可能导致事务迟迟不提交,从而导致锁资源不释放和阻塞等待等性能问题。
延迟复制
当从库上的 I/O 线程,将主库的 binlog 请求回来后,从节点的 SQL 线程并不会立刻解析日志执行,而是等待一段时间后再解析日志执行,这个等待的时间可以配置。
延迟复制的好处是可以防止误删操作。缺点是会有很长一段时间的数据不一致,可能导致数据的丢失。一般用于仅作为备库的节点使用,不能进行读写分离。
并行复制
GTID复制
GTID,Global Transaction Identifier,用于唯一地标识一个事务。
GTID 由节点 UUID + 事务 ID 两部分组成,MySQL 在第一次启动时都会利用 UUID 随机生成一个 server_id,还会对每一个写事务都分配一个顺序递增的值作为事务 ID,GTID 的格式为 server_uuid:trx_id。
基于 GTID 的复制过程:
-
master 在更新数据时,会为每一个写事务分配一个全局的 GTID,并记录到 binlog 中。
-
slave 节点的 I/O 线程拉取数据时,会将读到的记录写到 relay-log 中,并设置 gtid_next 值。
-
slave 节点的 SQL 线程执行前,会读取 gtid_next 值得知接下来该解析哪条日志并执行。
-
slave 节点的 SQL 线程在执行时,会先比对自身的 binlog 日志中是否有对应的 GTID:
-
有:意味着该 GTID 对应的事务已经执行过了,slave 会自动忽略掉这条记录。
-
没有:SQL 解析该 GTID 对应的 relay-log 记录并执行,再将 GTID 记录到 binlog。
-
基于 GTID 的自动同步:发生主从切换时可以执行 change master to master_auto_position=1,会自动去新主库上寻找数据的同步点。
GTID 是基于事务来实现的,也就代表不支持事务的存储引擎无法使用这种机制。
组复制
GTID 复制是组复制得基础。组复制是指将一组并行执行的事务,全部放入到一个 GTID 中记录,后续从节点同步数据时,会一次性读取这一组事务解析并执行,即组提交。
组复制的 GTID 通过逗号分隔。
并行复制
并行复制是在组复制的基础上实现的。因为能够在同一时间内提交的事务,绝对是不存在锁冲突的,所以可以开启多条线程同时执行一个组中不同的事务。
并行复制能够在很大程度上提升从库复制数据的速度,也就是能够让从库的数据实时性提升。
在 MySQL5.7 中官方为这种机制命名为 enhanced multi-threaded slave,简称 MTS 机制,同时为了兼容 5.6 版本中的并行复制,又多加入了一个 slave-parallel-type 参数:
- DATABASE:默认的并行复制模式,表示基于库级别来完成并行复制。
- LOGICAL_CLOCK:表示基于组提交的方式来完成并行复制。
虽然 5.7 中的并行复制,在一定程度上解决了原有的从库延迟问题,但如果一个新的从节点加入集群时,因为要从头开始同步数据,这种并行复制的模式依旧存在效率问题,而到了 MySQL8.0 对于并行复制技术提出了真正的解决之道,也就是基于 writeset 的 MTS 技术。即多个事务之间,只要变更的数据记录没有重叠,也就是操作的数据没有冲突,无需在一个事务组内,也可以支持并发执行。
两阶段提交
2PC,two-phase commit protocol。
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致。
- 如果在将 redo log 刷入到磁盘之后, MySQL 突然宕机了,而 binlog 还没有来得及写入。MySQL 重启后,通过 redo log 能将 Buffer Pool 中的相应数据恢复到新值,但是 binlog 里面没有记录这条更新语句,在主从架构中,binlog 会被复制到从库,由于 binlog 丢失了这条更新语句,从库的数据是旧值;
- 如果在将 binlog 刷入到磁盘之后, MySQL 突然宕机了,而 redo log 还没有来得及写入。由于 redo log 还没写,崩溃恢复以后这个事务无效,所以数据还是旧值;而 binlog 里面记录了这条更新语句,数据是新值;
在持久化 redo log 和 binlog 这两份日志的时候,如果出现半成功的状态,就会造成主从环境的数据不一致性。因为 redo log 影响主库的数据,binlog 影响从库的数据,所以 redo log 和 binlog 必须保持一致才能保证主从数据一致。
MySQL 为了避免出现两份日志之间的逻辑不一致的问题,使用了「两阶段提交」来解决,两阶段提交其实是分布式事务一致性协议,它可以保证多个逻辑操作要不全部成功,要不全部失败,不会出现半成功的状态。
当客户端执行 commit 语句或者在自动提交的情况下,MySQL 内部开启一个 XA 事务,分两阶段来完成 XA 事务的提交,分别是准备阶段和提交阶段。
- prepare 阶段:将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 持久化到磁盘(innodb_flush_log_at_trx_commit = 1 的作用);
- commit 阶段:把 XID 写入到 binlog,然后将 binlog 持久化到磁盘(sync_binlog = 1 的作用),接着调用引擎的提交事务接口,将 redo log 状态设置为 commit,此时该状态并不需要持久化到磁盘,只需要 write 到文件系统的 page cache 中就够了,因为只要 binlog 写磁盘成功,就算 redo log 的状态还是 prepare 也没有关系,一样会被认为事务已经执行成功;

不管是时刻 A(redo log 已经写入磁盘, binlog 还没写入磁盘),还是时刻 B (redo log 和 binlog 都已经写入磁盘,还没写入 commit 标识)崩溃,此时的 redo log 都处于 prepare 状态。
在 MySQL 重启后会按顺序扫描 redo log 文件,碰到处于 prepare 状态的 redo log,就拿着 redo log 中的 XID 去 binlog 查看是否存在此 XID:
- 如果 binlog 中没有当前内部 XA 事务的 XID,说明 redolog 完成刷盘,但是 binlog 还没有刷盘,则回滚事务。对应时刻 A 崩溃恢复的情况。
- 如果 binlog 中有当前内部 XA 事务的 XID,说明 redolog 和 binlog 都已经完成了刷盘,则提交事务。对应时刻 B 崩溃恢复的情况。
可以看到,对于处于 prepare 阶段的 redo log,即可以提交事务,也可以回滚事务,这取决于是否能在 binlog 中查找到与 redo log 相同的 XID,如果有就提交事务,如果没有就回滚事务。这样就可以保证 redo log 和 binlog 这两份日志的一致性了。
两阶段提交是以 binlog 写成功为事务提交成功的标识。
事务没提交的时候,redo log 也是可能被持久化到磁盘。但是 binlog 必须在事务提交之后,才可以持久化到磁盘。
组提交
两阶段提交虽然保证了两个日志文件的数据一致性,但是性能很差,主要有两个方面的影响:
- 磁盘 I/O 次数高:对于“双1”配置,每个事务提交都会进行两次 fsync(刷盘),一次是 redo log 刷盘,另一次是 binlog 刷盘。
- 锁竞争激烈:两阶段提交虽然能够保证「单事务」两个日志的内容一致,但在「多事务」的情况下,却不能保证两者的提交顺序一致,因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证多事务的情况下,两个日志的提交顺序一致。
MySQL 引入了 binlog 组提交(group commit)机制,当有多个事务提交的时候,会将多个 binlog 刷盘操作合并成一个,从而减少磁盘 I/O 的次数。
MySQL 5.7 开始有 redo log 组提交。
引入了组提交机制后,prepare 阶段不变,只针对 commit 阶段,将 commit 阶段拆分为三个过程:
- flush 阶段:多个事务按进入的顺序将 binlog 从 cache 写入文件(不刷盘);
- sync 阶段:对 binlog 文件做 fsync 操作(多个事务的 binlog 合并一次刷盘);
- commit 阶段:各个事务按顺序做 InnoDB commit 操作;
上面的每个阶段都有一个队列,每个阶段有锁进行保护,因此保证了事务写入的顺序,第一个进入队列的事务会成为 leader,领导所在队列的所有事务,全权负责整队的操作,完成后通知队内其他事务操作结束。
同一时刻只允许一组事务提交。
最后
本文介绍了 MySQL 的主从架构。
至此我的 MySQL 学习笔记就全部更新完毕了。学习和使用 MySQL 陆陆续续也有两三年了,从最开始只关注如何使用,到现在为了应付面试而更多的关注原理和实现,但是很多地方都只是停留在表面,并没有自己深入源码去分析和做实验来验证,只能说希望以后有机会再次学习吧。





![[PyTorch]Onnx模型格式的转换与应用](https://img-blog.csdnimg.cn/3dd78a8428d64038b7bc06d3980df8b5.png)