▐ 摘要
CTR(Click-through rate)预估一直是推荐/广告领域重要技术之一。近年来,通过统一模型来服务多个场景的预估建模已被证明是一种有效的手段。当前多场景预估技术面临的挑战主要来自两方面:1)跨场景泛化能力:尤其对稀疏场景;2)计算复杂度:在线计算和存储资源有限情况下如何实现多场景模型构建。针对这两个挑战,本文提出AdaSparse,一种通过自适应学习稀疏网络的方法来实现多场景CTR预估建模。该方法为每个场景学习一个子网络结构,在计算成本增加有限的条件下,自适应平衡场景间的共性和特性,提升了模型跨场景的泛化能力。我们设计了一个辅助网络来衡量主网络每一层神经元对每个场景的重要度,并通过网络裁剪技术对不重要/冗余的神经元进行裁剪,最终为每个场景生成一个专属的子网络进行预估。此外,我们提供了一种灵活的稀疏正则方法来更好的控制网络稀疏程度,使模型在应用上更具有灵活性。AdaSparse已在阿里妈妈外投广告系统上线,支撑了多个投放业务的CTR预估,整体取得了CTR+4.63%,CPC-3.82%的效果(CPC:点击成本,越低越好) 。该工作核心部分已收录于 CIKM2022,本文将对该方法的背景及实现进行详细介绍,欢迎阅读交流。
论 文:AdaSparse: Learning Adaptively Sparse Structures for Multi-Domain Click-Through Rate Prediction
下 载:https://dl.acm.org/doi/abs/10.1145/3511808.3557541
1. 背景
传统的CTR预估模型往往是单场景的,即假设训练样本服从同一分布。但在工业应用中,这是个很强的假设。一方面,现实中往往面临多个业务需要同时预估的工作。例如在阿里妈妈外投平台,存在多个业务方如天猫/饿了么/蚂蚁等同时进行广告投放,各业务的投放数据分布往往不同。如图1(a)所示,不同的业务方(如B5/B2)其用户和CTR效果差异较大,若合在一起训练模型可能被B1和B5两个业务主导,从而导致其他业务效果较差。另一方面,除了不同的业务可以场景划分依据,相同业务下某些特征也可以作为场景划分依据,例如“不同的广告位,用户行为差异较大”、“相同业务不同用户画像,用户行为差异也可能较大”。如图1(b)所示,不同广告位下用户和CTR分布也有类似的差异现象。为此,我们这里定义一种“广义”的多场景:目标行为差异较大的特征,都可以作为一种多场景划分的依据。这也促使我们不断探索多场景预估技术,以通过捕捉用户在不同场景下的不同偏好来提升模型整体的效果。

图1(c)显示了多场景预估建模的抽象范式,主要面临两个挑战:1)跨场景泛化能力,为了获得更好的效果,模型需要具备建模场景共性知识和捕捉场景个性知识的能力,同时还需要在稀疏场景有一定的泛化能力。2)计算成本可控,实现多场景预估技术往往需要更多参数,但在工业级应用中,计算资源有限,模型需要兼顾效率和效果。因此,我们需要寻找一种多场景预估技术:统一的模型,具备优异的场景迁移能力,且在线性能可控。
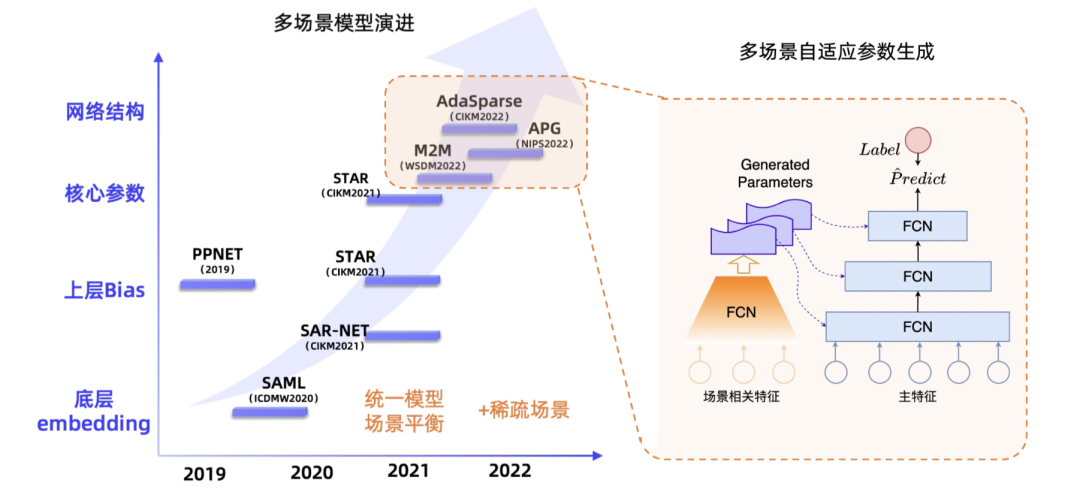
近年来涌现了不少多场景预估工作,通过对特征或网络做一些先验设计让场景相关特征在预估中发挥更大的作用。如图2所示,我们挑选了其中几个具代表性的工作,基于场景相关特征作用点的不同,归纳出了一条优化路线:场景相关特征作用从底层embedding到上层bias,再到模型核心参数,再到网络结构。其复杂度越来越高,作用力也越来越强。具体地,如图2所示,SAML[12]最开始对底层特征embedding做两套,一套用于场景共享,一套是场景特有;SAR-NET[13]则对模型中间层的表征做场景共性和特性的平衡操作。这类方法对场景信息的使用是偏底层的,但随着网络层数增加,加之与其他特征的相互作用,最终场景特征对预估产生多少影响是无法确定的。
因此,为了让场景相关特征发挥更大作用,出现了两个方向的思路:a) 信息离目标越近可能作用越强:将场景相关特征也作用在网络上层,诞生如BiasNet,PPNET的工作;b) 直接作用于网络中的核心参数上,如参数矩阵、Normlization的参数等。在实际应用中,有时会将两个方向的方法做结合,比如STAR[5],既有上层Bias也有核心参数上做场景共性和特性的平衡。这些方法一定程度上解决了场景共性和特性的平衡,但针对稀疏场景的解决可能不足,尤其通过特征划分的广义场景很容易达到成千上万量级,稀疏场景会较多。于是后面出现了一些基于核心参数场景自适应生成的方法(如M2M[11]、APG[8]),我们的方法主要聚焦这一类,并作用于网络结构。图2(右)展示了多场景自适应参数生成方法的常见建模范式,这类方法通过设计辅助网络以场景相关特征作为输入,输出场景相关的参数作用于主模型。这类方法容易实现跨场景知识的迁移,同时因对主网络每一层都有作用,场景相关特征对预估的影响也较强,随之而来的挑战是参数爆炸问题,这给模型收敛和存储都带来了困难。因此,我们需要寻找一种方法既可以保持准确度,又能减少参数量。
我们借鉴了网络压缩的技术来实现上述目标。网络压缩技术包括网络裁剪、矩阵低秩分解、知识蒸馏等方法,我们主要采用网络裁剪技术(Network Pruning)[3,4,10]。网络裁剪技术认为神经网络中参数往往是冗余的,从原大模型中能够找到一个准确度不弱于原模型的子网络,通过合理的裁剪便可以得到这个子网络。AdaSparse则是将网络裁剪技术和多场景参数生成技术结合,为每个场景寻找一个子网络,各子网络重叠和不重叠部分可视为学习场景的共性和特性。
为兼顾参数量和效果,AdaSparse将裁剪粒度定为神经元级,为此我们提供了一种场景相关的神经元级的权重因子方法:辅助网络以场景相关特征做输入,为主网络每一层神经元输出权重因子来衡量该神经元在该场景中的重要度。通过裁剪冗余/不重要的神经元,最终为每个场景学习到一个专属的子网络。由于神经元的数量远远小于模型参数(连接边),AdaSparse确保了较低的计算复杂度。
2. AdaSparse
设训练数据集为 ,其中和 分别代表第 个样本的特征和点击label。我们基于场景相关特征将数据集划分为多个场景,场景相关的数据集可表示为,这里我们将特征拆解为场景相关特征集和场景无关的特征集。以图1(b)为例,如果仅用广告位划分,我们得到18个场景,如果加入更多场景划分的特征如业务、广告位、人群、广告样式等等,这将得到成千上万的场景。多场景CTR预估的目的便是通过学习一个模型在所有场景上预估效果都较好。
2.1 模型概览
我们以层全连接DNN[1]作为主网络结构来详细介绍我们的方法。我们方法作用于神经元上,因此很容易扩展到其他网络结构例如DCNv2[6]。所有特征embedding后,我们将场景相关和无关的特征拼接,记为,作为主网络的输入。记为第层网络要学习的参数矩阵,即有,这里为第层隐藏层(神经元)。模型loss用常见的交叉熵loss。最终定义模型优化目标为:
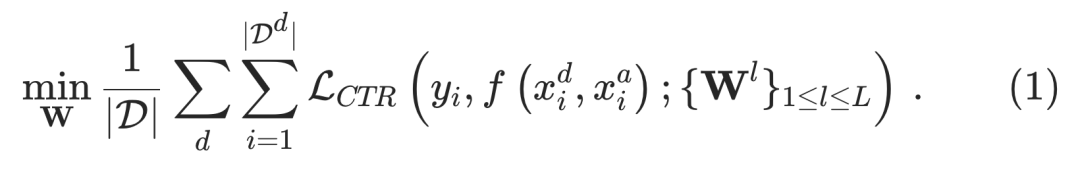
AdaSparse整体的模型流程如下图3所示,在主模型每相邻两层网络上做场景自适应。图3右侧以相邻两层网络为例详细展示了自适应裁剪的过程,核心在于中间这个场景自适应Pruner模块(domain-aware pruner),该模块是一个轻量级MLP,以该层隐藏层拼接场景特征embedding(即)作为输入,输出场景相关的神经元维度的权重因子向量(记为 ,代表场景相关的权重因子向量),并作用在原网络的这一隐藏层。基于权重因子的不同生成方式,我们进一步细分为三种方法,分别是二值法(Bianarization)、缩放法(Scaling)、二者混合(Fusion)的方法,后续我们将详细介绍这三种方法。此外,AdaSparse对于每一层的常数项走单独的场景BiasNet来生成,因为不想限制常量bias的取值范围。同时,为了加速收敛,Pruner模块梯度反向传播时停止对场景相关特征的更新,即场景相关特征的参数更新还是来源于主网络。
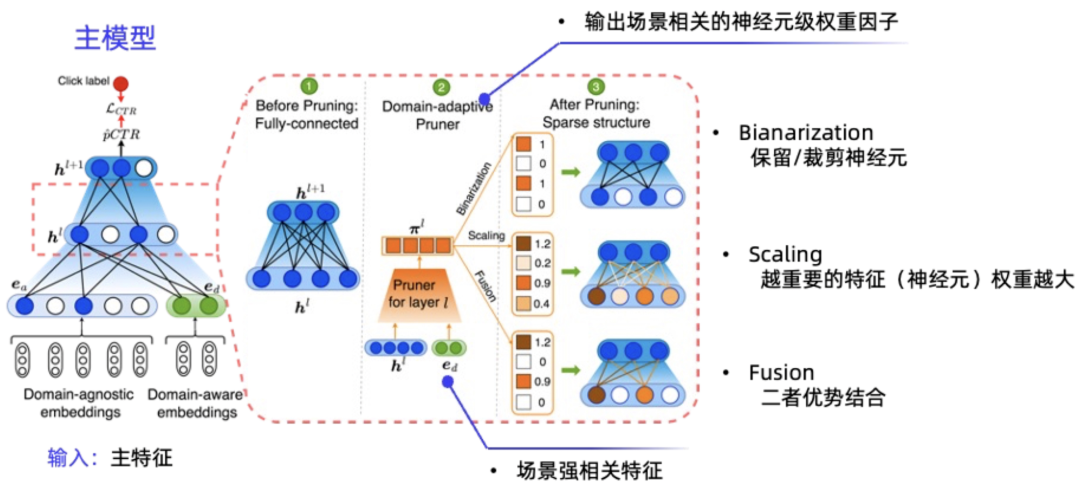
2.2 场景自适应Pruner
如图4所示,Pruner是一个轻量级网络,以作为输入,通过MLP最上层连接sigmoid激活函数和一个软阈值操作函数,最终得到场景的权重因子,然后和原始的隐藏向量做element-wise相乘:
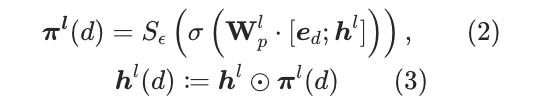
这里软阈值操作函数对输出结果小于阈值的值强制变为0,从而实现对神经元的裁剪。根据和 的不同,我们介绍三种权重因子生成的方法:
二值法(Binarization)。我们希望权重因子为0-1值,动机是为场景直接剔除冗余/噪音信息,保留重要信息会带有效果有益。为避免模型欠拟合初期有裁剪错误的风险,我们希望在训练过程中逐步获得0-1值的向量,但激活函数其值域是(0,1),要得到0-1值其实并不容易,需要值较大,但模型的正则约束又会使不会太大。若我们直接按照阈值来获取0-1,例如,但这种方式过于直接,存在很大误裁剪的风险。为此,我们从两个方面优化:1)增加个自适应参数, 激活函数设计为, 当较大时,sigmoid越“陡峭”,越容易得到0-1值。由于我们是End2End的训练方式,我们希望模型在训练的欠拟合初期不裁剪,初始化较小,随着训练增加而增大;2)Pruner网络初始化设置大一些,这样容易获得输出绝对值较大。
缩放法(Scaling)。该方法动机为相同的特征对不同的场景有不同的作用,我们希望作用越大的信息权重越大。Scaling方法不做神经元裁剪,而是用一种“软裁剪”方式让冗余/噪音信息对预估结果影响较小。这里我们设置超参对权重幅度进行约束。
混合法(Fusion)为上述二种方法的优势结合。
值得注意的是,这里用到的阈值函数其是一种符号函数,符号函数的特点是在断点处不可导,其他地方导数为0,这个不适合模型反向传播做梯度更新。事实上,对于符号函数求导问题业界解决也比较成熟,这里推荐三种方法:a) stop gradient方法(我们线上用的该方法):前向传播正常计算,反向传播把这个函数屏蔽掉,保证权重正常求导;b)或:这是一种妥协的方法,反向传播时把符号函数替换为这个函数, 该函数在x属于一定范围是能保证梯度;c) 借鉴L0正则的松弛技术:一些方法中通过L0正则产生稀疏网络,并提供了解决L0正则不可导的一种松弛技术,具体可参考文献[14]。

2.3 稀疏度正则
稀疏网络产生过程中一个重要问题是:对于不同场景,稀疏度多少才合适?我们希望模型自动为每个场景学习到最优的稀疏度,但我们也担心自动学习的稀疏度过于异常。为此,我们提供一种灵活的稀疏正则方法,对稀疏度设置个范围,在该范围内各场景模型自动收敛到各自的最优稀疏度。设稀疏度表示为,这里为L1正则,为层隐藏向量长度。定义稀疏度控制范围为,稀疏正则公式设计如下:

这里参数有三个目的:a) 如果稀疏度已经在预设范围,则稀疏正则不生效;2)自适应:在训练初期让模型专注拟合label,稀疏正则作用小一些,后期再增强稀疏控制;3)合理的设置统一与主loss的量纲。
3. 实验及效果
我们分别在公开数据集IAAC[8](千万训练样本,300个场景)和 产生数据集Production(22亿训练样本,5000+个场景)上分别进行实验。主网络结构分别为DNN[1] 和 DCNv2[6],AdaSparse 默认参数为初始化为0.1,上限为5.0,其他参数可参考论文。Baselines包括:MAML[9],STAR[5],APG[8]。
3.1 离线实验
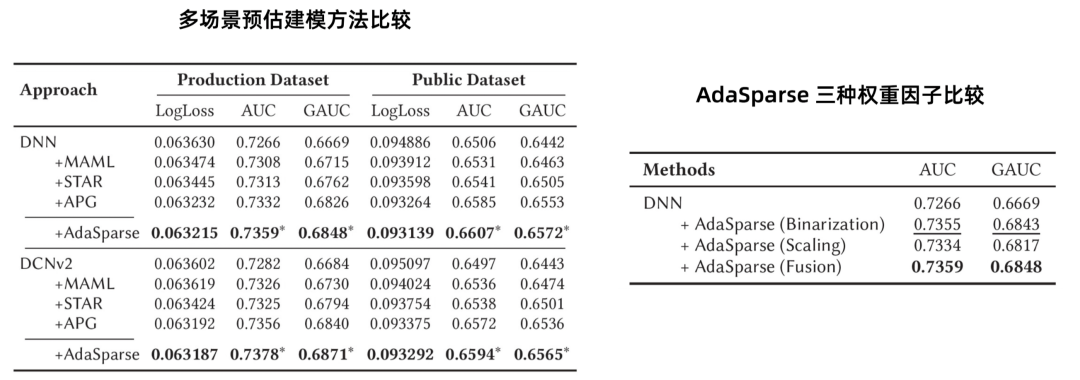
从表1(左)可知,“广义”多场景建模可以有效提升预估结果。由于公开数据集偏少,可以看到DCNv2效果整体弱于DNN,并且实验中发现模型不易收敛,可以尝试减少参数量。得益于场景相关特征对预估的增强和场景的冗余/噪音信息裁剪,AdaSparse取得了不错的结果。表1(右)的消融实验也可以看到,将场景的冗余/噪音信息进行个性化裁剪或权重缩放,都能取正向效果,并且二者融合有一定的效果叠加。
3.2 进一步分析
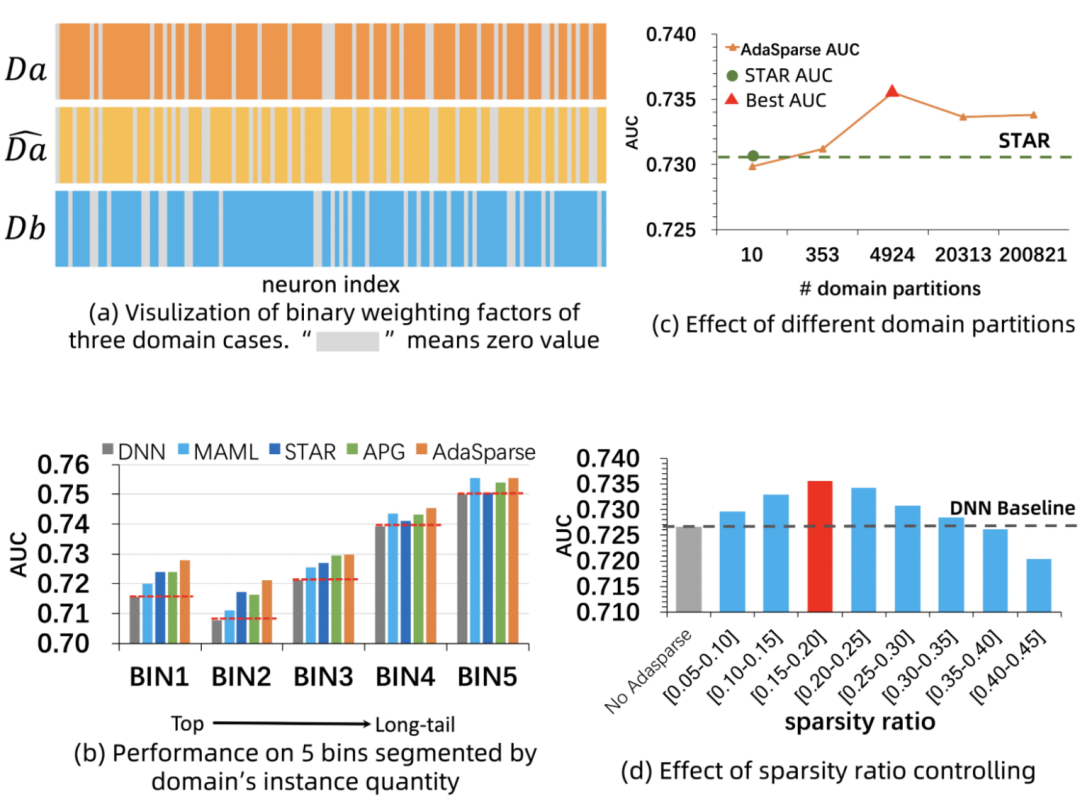
a) 跨场景泛化可视分析: 我们通过case study来分析模型跨场景泛化能力。具体的,找一个相似domain(和相似)和一个不相似domain (和不相似)(相似定义:domain划分的特征值重合程度),取最后一层layer看0-1分布。结果如图5(a)所示,可以看到相似domain其网络结构有更多的重叠,即共性学得更多,因此AdaSparse能够自动学习场景的共性和特性,实现跨场景迁移。
b) 对稀疏场景的泛化: 我们对场景按照曝光数进行等频分桶(5个),桶BIN1代表头部场景,其训练样本较丰富,BIN5代表长尾场景,其样本较稀疏。图5(b)显示所有的方法在头部domain上提效都更显著,但在长尾domains上AdaSparse有一定的优势,显示了AdaSparse对稀疏场景有不错的泛化能力。
c) 场景数与效果: 我们通过逐步增加场景划分的特征,看场景数与模型效果的关系,如图5(c)显示效果随着domain数量增加呈现先增加后降低的现象。该实验说明并非场景划分越多越好,需要一定经验来来设置合理的场景划分。
d) 稀疏度与效果: 图5(d)显示了不同稀疏度控制下效果的变化,可以看到效果随着稀疏度增加先提升后减少。注意到稀疏度为[0.35,0.4]时效果和Base DNN差不多,这也间接证明模型确实有冗余信息,裁剪冗余信息有潜在的提效空间。
3.3 在线实验
我们最终采用Fusion版本在线实验,评价指标包括 CTR、CPC(点击成本,越低越好),同时我们想评估对各场景的提效情况,评估指标为UPR:,UPR表示有效提效的场景占比多少。最终AdaSparse取得了CTR +4.63%,CPC -3.82%的正向提升,同时UPR取得超过90% 的效果。
4.总结与展望
本文分享的多场景CTR预估技术AdaSparse,其结合网络裁剪技术为每个场景自适应学习一个子网络来进行CTR预估,方法简单轻量级,也取得了不错的线上效果。在实践中,我们进一步发现辅助网络倾向于被大场景主导,未来我们将进一步探索更有效的缓解场景稀疏的问题,同时小场景对大场景的辅助也是值得探索的方向。
5. Reference
[1] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems. 191–198.
[2] Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In proceedings of the 25th international conference on world wide web. 507–517.
[3] Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. 2017. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE international conference on computer vision. 2736–2744.
[4] Jian-Hao Luo and Jianxin Wu. 2020. Autopruner: An end-to-end trainable filter pruning method for efficient deep model inference. Pattern Recognition 107 (2020), 107461.
[5] Xiang-Rong Sheng, Liqin Zhao, Guorui Zhou, Xinyao Ding, Binding Dai, Qiang Luo, Siran Yang, Jingshan Lv, Chi Zhang, Hongbo Deng, et al. 2021. One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 4104–4113.
[6] RuoxiWang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. DCN V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the Web Conference 2021. 1785–1797.
[7] Penghui Wei, Weimin Zhang, Zixuan Xu, Shaoguo Liu, Kuang-chih Lee, and Bo Zheng. 2021. AutoHERI: Automated Hierarchical Representation Integration for Post-Click Conversion Rate Estimation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 3528–3532.
[8] Bencheng Yan, Pengjie Wang, Kai Zhang, Feng Li, Jian Xu, and Bo Zheng. 2022. APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction. arXiv preprint arXiv:2203.16218 (2022).
[9] Runsheng Yu, Yu Gong, Xu He, Bo An, Yu Zhu, Qingwen Liu, and Wenwu Ou. 2020. Personalized adaptive meta learning for cold-start user preference prediction. arXiv preprint arXiv:2012.11842 (2020). [10] Michael Zhu and Suyog Gupta. 2017. To prune, or not to prune: exploring the efficacy of pruning for model compression. arXiv preprint arXiv:1710.01878 (2017).
[11] Qianqian Zhang, Xinru Liao, Quan Liu, Jian Xu, and Bo Zheng. 2022. Leaving No One Behind: A Multi-Scenario Multi-Task Meta Learning Approach for Advertiser Modeling. arXiv preprint arXiv:2201.06814 (2022).
[12] Yuting Chen, Yanshi Wang, Yabo Ni, An-Xiang Zeng, and Lanfen Lin. 2020. Scenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce. In 2020 International Conference on Data Mining Workshops (ICDMW). IEEE, 127–135.
[13] Qijie Shen, Wanjie Tao, Jing Zhang, Hong Wen, Zulong Chen, and Quan Lu. 2021. SAR-Net: A Scenario-Aware Ranking Network for Personalized Fair Recommendation in Hundreds of Travel Scenarios. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 4094–4103.
[14] Christos Louizos, Max Welling, and Diederik P Kingma. 2017. Learning sparse neural networks through 𝐿_0 regularization. arXiv preprint arXiv:1712.01312 (2017)
END

也许你还想看
丨1项开源&3篇顶会,漫游阿里妈妈外投广告预估模型优化之路
丨EFLS开源 | 阿里妈妈联邦学习解决方案详解
丨面向 CTR 的外投广告动态创意优化实践
丨CVR 预估去偏:不确定性约束的知识蒸馏模型 UKD
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓