什么是MVCC
MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
一般情况下我们使用mysql数据库的时候使用的是Innodb存储引擎,Innodb存储引擎是支持事务的,那么当多线程同时执行事务的时候,可能会出现并发问题。这个时候需要一个能够控制并发的方法,MVCC就起到了这个作用。
Mysq的锁和事务隔离级别
在理解MVCC机制的原理之前,需要先理解Mysql的锁机制和事务的隔离级别,抛开MyISAM存储引擎不谈,就Innodb存储引擎来说,分别有行锁和表锁两种锁,表锁就是一次操作锁住整张表,这样锁的粒度最大,但是性能也最低,不会出现死锁。行锁就是一次操作锁住一行,这样锁的粒度小,并发度高,但是会出现死锁。
Innodb的行锁又分为共享锁(读锁)和排它锁(写锁),当一个事务对某一行加了读锁时,允许其他事务对这一行进行读操作,但是不允许进行写操作,也不允许其他事务对这一行执行加写锁,但是可以加读锁。
当一个事务对某一行加了写锁时,不允许其他事务对这一行进行写操作,但是可以读,同时不允许其他事务对这一行加读写锁。
下面来看一下Mysql的事务隔离级别,分为以下四种:
-
读未提交:一个事务可以读到其他事务还没有提交的数据,会出现脏读。举个例子,有一张工资表,事务A先开启,然后执行查询id为1的员工的工资,假设此时的工资为1000,此时,事务B也开启,执行了更新操作,将id为1的员工工资减少了100,但是并未提交事务。此时再执行事务A的查询操作,可以读到事务B已经更新的数据,如果此时事务B发生回滚,事务A读到的就是“脏”数据。当事务A执行更新操作的话还可能产生幻读的情况。
-
读已提交:一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值。还是同样的例子,这次的事务隔离级别为读已提交的情况下,事务B不提交事务的情况下,事务A无法读到事务B更新后的数据,也就避免了脏数据产生。但是,当事务B提交之后,事务A再执行相同的数据,会发现数据变了,这就是所谓的不可重复读,意思就是同一个事务中多次执行相同的查询得到的结果不一致,同时,幻读的情况还是存在。
-
可重复读:一个事务第一次读过某条记录后,即使其他事务修改了该记录的值并且提交,该事务之后再读该条记录时,读到的仍是第一次读到的值,而不是每次都读到不同的数据,这就是可重复读,这种隔离级别解决了不可重复,但是还是会出现幻读。
-
串行化:这种隔离级别因为对同一条记录的操作都是串行的,所以不会出现脏读、幻读等现象,但是这也就不是并发事务了。
Mysq的undo log
MVCC底层依赖Mysql的undo log,undo log记录了数据库的操作,因为undo log是逻辑日志,可以理解为delete一条记录的时候,undo log会记录一条对应的insert记录,update一条记录的时候,undo log会记录一条相反的update记录,当事务失败需要回滚操作时,就可以通过读取undo log中相应的内容进行回滚,MVCC就利用到了undo log。
MVCC的实现原理
MVCC的实现,利用到了数据库的隐式字段,undo log和ReadView。首先来看隐式字段,其实mysql在表中的每行记录的后面,都隐式的记录了DB_TRX_ID(最近修改(修改/插入)事务ID),DB_ROLL_PTR(回滚指针,指向这条记录的上一个版本),DB_ROW_ID(自增ID,如果数据表没有主键,则默认以此ID简历聚簇索引)这几个隐藏的字段。
undo log分为两种,分别为insert undo log,在insert新记录时产生的undo log, 只在事务回滚时需要,并且在事务提交后可以被立即丢弃,还有update undo log,事务在进行update或delete时产生的undo log; 不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除。MVCC利用到的是update undo log。
实际上undo log记录的是一个版本链,假设数据库中有一条记录如下:
现在有一个事务A修改了这条记录,把name改为tom,这个时候的操作流程为:
-
事务A首先对该行记录加上行锁
-
然后将该行记录拷贝到undo log中,作为一个旧的版本
-
拷贝完之后将该行name修改为tom,然后将该行的DB_TRX_ID的值改为事务A的id,此时假设事务A的id为1,将该行的DB_POLL_PTR指向拷贝到undo log的那条记录
-
事务提交后,释放锁
此时的情况如下:

此时又有一个事务B来修改这条记录,把age改为28,这时候的操作流程为:
-
事务B对改行记录加上行锁
-
将该行记录拷贝到undo log中,作为一个旧的版本,此时发现undo log已经有记录了,那么新的一条undo log作为链表的表头插入到该行记录的undo log的最前面
-
拷贝完后将该行的age改为28,然后将该行的DB_TRX_ID的值改为事务B的id,此时假设事务B的id为2,将该行的DB_POLL_PTR指向拷贝到undo log的那条记录
-
事务提交后释放锁
此时的情况如下:
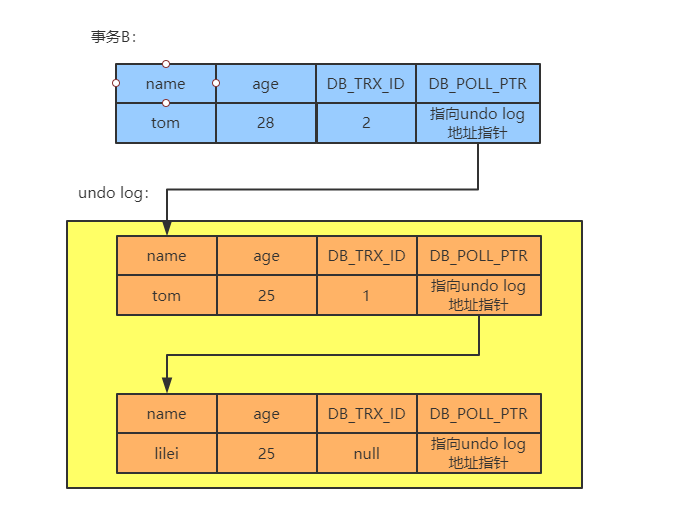
从上面我们可以看到,不同的事务或者相同的事务对同一行记录进行的修改,会使得该行记录的undo log形成一个版本链,undo log的链首就是最近一次的旧记录,而链尾就是最早一次的旧记录。
现在我们来假设一种情况,先假设事务A和事务B都没有提交,这时候有一个事务C,修改了name为tom的记录,把age改成了30,然后把事务提交,事务C的id为3,同样的,会插入一条记录到undo log中,此时的undo log版本链链首记录的DB_TRX_ID为3。
现在有一个事务D,查询name为tom的记录,此时将会启用快照读,快照是事务开始由查询操作触发的一个数据快照,不加锁的读在可重复读隔离级别下默认就是快照读,相对于快照读还有一个叫做当前读,更新操作都是当前读。在快照读时会产生一个读视图(Read view),在该事务执行快照读的那一刻,会生成数据库当前的一个快照,记录并且维护当前活跃的事务的ID,因为事务的ID都是自增的,所以越新的事务ID越大。读视图遵循可见性算法,而是否可见则需要做一些判断,读视图中除了记录当前活跃的事务ID以外,还记录了当前创建的最大事务ID,快照读时需要和Read view做比较来获得可见性结果。
Read view主要是把当前事务的ID,和系统中的活跃事务的ID作比较,比较的规则如下:
首先,Read view中会有一个Read view生成时刻系统中活跃的事务ID的数组,暂称为id_list
然后Read view中会记录一个id_list中最小的事务ID,暂称为low_id
最后Read view中还会记录一个Read view生成时刻系统中尚未分配的事务ID,也就是当前最大的事务ID+1,暂称为high_id
-
当前事务ID如果小于low_id,则当前事务可见
-
当前事务ID如果大于high_id,则当前事务不可见
-
当前事务大于low_id小于high_id,再判断是否在id_list中,如果在,说明活跃的事务还没提交,当前事务不可见,但是对于活跃的事务本身可见,如果不在id_list中,则当前事务可见
如果可见性结果为不可见的话,需要通过DB_ROLL_PTR到undo log中取出该记录的DB_TRX_ID进行比较,通过遍历版本链,直到找到满足特定条件的DB_TRX_ID, 那么这个DB_TRX_ID所在的旧记录就是当前事务能看见的最新老版本。
详细请看Mysql系列

![[附源码]计算机毕业设计springboot求职招聘网站](https://img-blog.csdnimg.cn/b582d5a6360a4cea8e423bbaed788690.png)


![[附源码]JAVA毕业设计个人饮食营养管理信息系统(系统+LW)](https://img-blog.csdnimg.cn/7f909163276a4fa7a22c434633888c8c.png)