期刊: Briefings in Bioinformatics
出版日期 2022-11-22
websever:https://iasri-sg.icar.gov.in/pldbpred/
网址: PlDBPred: a novel computational model for discovery of DNA binding proteins in plants | Briefings in Bioinformatics | Oxford Academic
摘要
DNA结合蛋白(DBPs)在许多细胞过程中发挥着至关重要的作用,包括核苷酸识别、转录控制和基因表达调控。大多数现有的用于识别DBP的计算技术主要适用于人类和小鼠数据集。尽管一些模型已经在拟南芥上进行了测试,但当应用于其他植物物种时,它们的准确性很差。因此,开发一种有效的计算模型来预测植物DBP是当务之急。在这项研究中,我们开发了一个用于植物特定DBP识别的综合计算模型。五个浅层学习和六个深度学习模型最初用于预测,其中浅层学习方法优于深度学习算法。特别是,支持向量机实现了最高的重复5倍交叉验证准确率,受试者工作特征曲线下面积(AUC-ROC)为94.0%,精密度-召回曲线下面积为93.5%。在独立数据集的情况下,所开发的方法获得了93.8%的AUC-ROC和94.6%的AUC-PR。与现有技术中使用独立数据集的工具相比,所提出的模型实现了更高的精度。总体结果表明,与现有的植物DBP预测模型相比,所开发的计算模型更有效、更可靠。为了方便大多数实验科学家,开发的预测服务器PlDBPred可在https://iasri-sg.icar.gov.in/pldbpred/.The还提供了源代码https://iasri-sg.icar.gov.in/pldbpred/source_code.php用于使用大型数据集进行预测
数据集
UniProt数据库[29](于21年6月14日访问)用于编译当前研究的植物DBP(阳性数据集)和非DBP(阴性数据集)序列。用GO术语“DNA结合”(GO:00033677)注释的蛋白质序列被视为DBP序列,而没有注释的蛋白质被视为非DBP序列。对于35种不同的植物,共收集了1812个DBP和2284个非DBP序列。去除了具有非标准氨基酸(B、J、O、U、X和Z)和少于50个氨基酸的蛋白质序列。DBP和非DBP数据集都进行了同源性降低,以消除预测准确性上的同源性偏差。使用CD-HIT方法[30]去除每个数据集中与任何其他序列具有>40%序列同一性的序列。849个DBP和1848个非DBP序列在处理后被保留。为了避免对具有更多观测值的非DBP类的预测偏差,考虑了具有相等数量的DBP和非DBP序列的平衡数据集。换句话说,从1848个非DBP序列中随机选择了849个非DBP-序列。
方法
PSSM衍生进化特征的生成
尽管基于序列的特征已被证明在许多预测任务中是有效的,但许多研究表明,从PSSM[31]剖面中获得的进化特征比基于序列的特性[13,24]提供的信息要多得多。基于PSSM的特征描述符已被用于几种生物信息学应用[32-33]。通过在NCBI非冗余(NR)数据库上运行PSI-BLAST[31](ftp://ftp.ncbi.nih.gov/blast/db/nr),在本研究中获得了每个蛋白质序列的PSSM图谱。PSSM轮廓是一个L×20维矩阵,可以写成
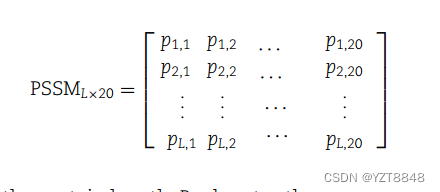
其中L是蛋白质长度,Pi,j表示氨基酸j在蛋白质序列的位置i处的出现概率。在当前的研究中,考虑了10种不同的基于PSSM的特征,包括PSSMBLOCK、AADP-PSSM、PSSM-DWT、EDPEEDP-MEDP、MBMGAC-PSSM、PSSM400、PSSM-AC、RPSM、SOMAPSSM和DFMCA-PSSM。PSSMCOOL[34]R包用于实现所有功能。在补充文件1中,每个基于PSSM的特征集都进行了简短的描述,并有适当的引用。
利用浅层学习和深度学习算法进行预测
我们使用了五种不同类型的浅层学习方法,如SVM[35]、极限梯度提升(XGB)[36]、RF[37]、自适应提升(ADB)[38]和LogitBoost[39]。除了浅层学习方法外,还使用了深度学习模型的六种变体,如1D卷积神经网络(CNN_1D)[40]、基于注意力的CNN(ABCNN)[41]、递归神经网络(RNN)[42]、双向递归神经网(BRNN)[43]、深度残差神经网络(ResNet)[44]和自动编码器(AE)[45]。R包e1071、randomForest、xgboost、adabag和caTools分别用于实现SVM、RF、XGB、ADB和LogitBoost方法。使用python的PyTorch和TensorFlow模块实现了深度学习模型。用于实现学习模型以及参数配置的软件在补充文件1(补充表1)中提供,并有适当的引用。
特征选择
通过消除重复和噪声特征,特征选择降低了计算复杂度,同时提高了分类精度[46]。在这项工作中,使用SVM递归特征消除(SVM-RFE)方法选择了重要特征[47]。SVM-RFE方法是一种后向特征消除方法,其中信息量最小的特征在第一次迭代中被消除,最显著的特征在最后一次迭代中消除。确定应保留多少特征进行分析是至关重要的。在当前的研究中,实现选择了最佳分类精度。SVM-RFE方法是使用sigFeature R包实现的。
交叉验证和性能指标
使用重复的5倍交叉验证方法评估分类模型的性能,其中实验重复100次。为了进行五倍交叉验证[49],将每个DBP和非DBP数据集随机分为五个大小相等的亚组。从每个DBP和非DBP类中随机选择的一个子集被用作交叉验证的每个折叠中的测试集,而来自两个类的其余四个子集被组合作为训练集。分类进行了五次,每次折叠都有单独的训练和测试集。通过对所有五个测试集以及100个复制的准确性进行平均来确定性能指标。补充文件1(补充图S1)中提供了描述所提出方法的所有步骤的f低图。准确度、F-评分、受试者工作特征曲线下面积(AUROC)、精密度-召回曲线(AUC-PR)下面积、灵敏度、特异性、精密度和Matthews相关系数(MCC)被考虑来衡量预测模型的性能[50]。表1中提供了性能指标列表
结果
特征集选择分析
针对10个不同特征集中的每一个,分别评估11种算法中的每一种的预测性能,以分析每个特征集的有效性。此外,50%的数据集用于分析。除了几个显著的例外,SVM、RF、XGB和ADB被发现比深度学习模型表现更好,除了LogitBoost(图1)。
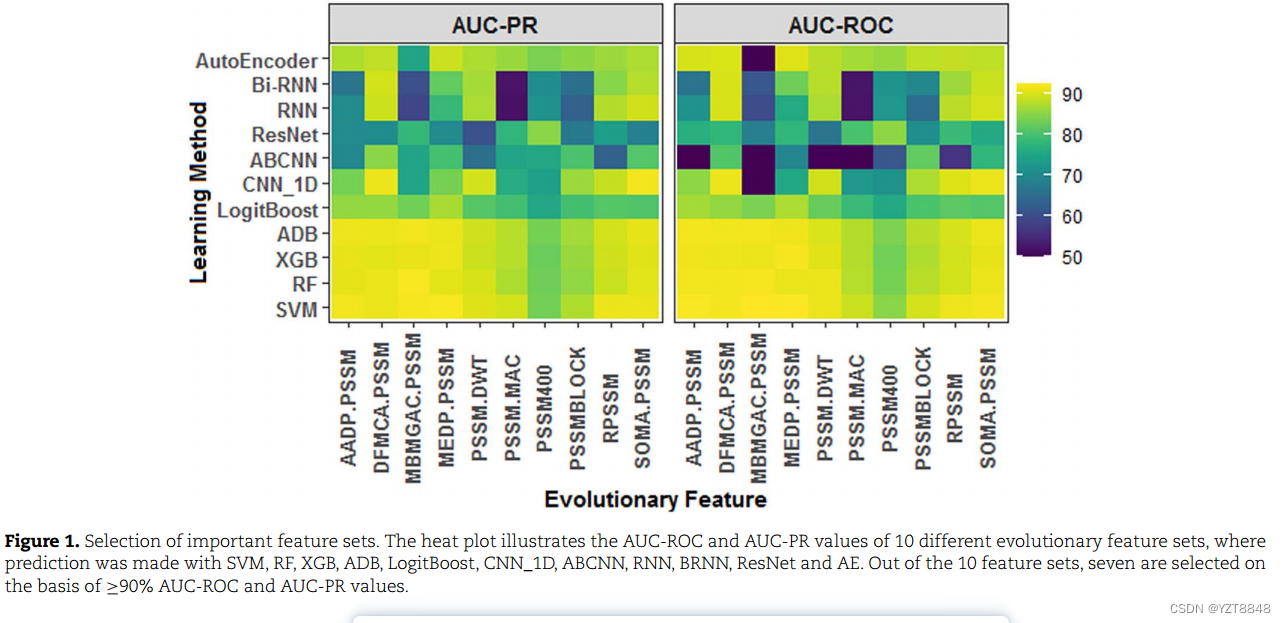
在所检查的深度学习模型中,Auto Encoder的精度最高(图1)。对于特征集AADP-PSSM、PSSM-DWT、MEDP-PSSM、MBMGACPSSM、RPSM、SOMA-PSSM和DFMCA-PSSM,SVM、RF、XGB和ADB的AUC-ROC和AUC-PR≥90%(图1),而PSSMBLOCK、PSSM400和PSSM-MAC的AUC-ROC和AUC-PR<90%(图一)。因此,考虑了七个特征集和四个精度更高的浅层学习算法(SVM、RF、XGB、ADB)进行进一步分析。
特征选择的结果
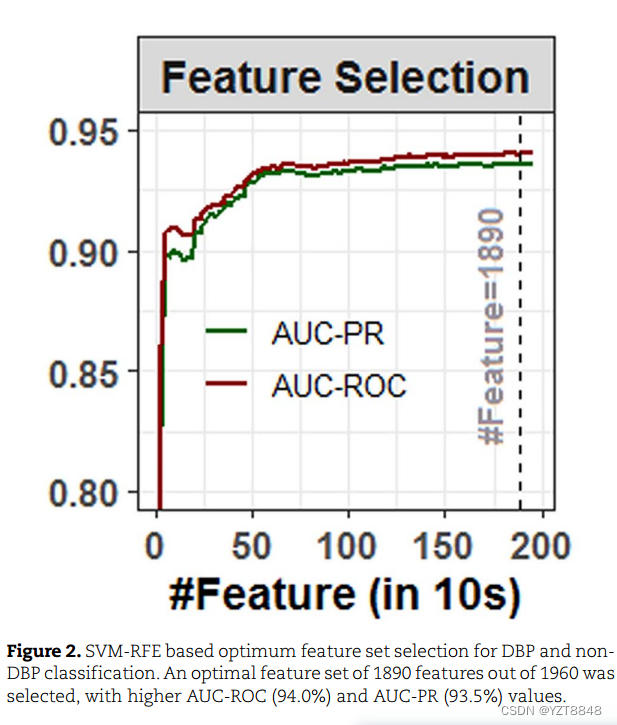
由于合并了选定的七个特征集,总共有1960个特征。每个特征集都是从PSSM导出的,因此组合的特征集可能包含冗余信息,这可能会降低预测精度。因此,为了选择用于DBP和非DBP分类的非冗余判别特征,应用了SVM-RFE特征选择方法。最后,选择了一个由1890个特征组成的特征集,发现这些特征具有更高的AUC-ROC(94.0%)和AUC-PR(93.5%)值(图2)。
模型选择分析
表2中提供了四种浅层学习方法的性能。尽管四种学习算法的准确性没有太大差异,但SVM的表现比其他三种学习算法要好一些(灵敏度:86.9%,特异性:87.5%,准确度:87.2%,精密度:87.4%,F评分:87.1%,AUC-ROC:94.0%,AUC-PR:93.5%和MCC:73.5%)。
 就敏感性而言,XGB的表现优于其他三种学习方法,而SVM的特异性得分最高,其次是RF、ADB和XGB。与RF和ADB相比,XGB在其余六个性能矩阵中表现更好。继SVM之后,发现XGB的总体表现优于RF和ADB模型。
就敏感性而言,XGB的表现优于其他三种学习方法,而SVM的特异性得分最高,其次是RF、ADB和XGB。与RF和ADB相比,XGB在其余六个性能矩阵中表现更好。继SVM之后,发现XGB的总体表现优于RF和ADB模型。
独立测试集结果
在与训练数据集完全不同的独立数据集上进一步评估所提出的模型(用选定特征训练的SVM)。我们从UniProt数据库(于21年11月15日访问)中收集了植物DBP序列,以创建阳性独立集。对于35种不同的植物,共获得1403个DBP序列。在去除具有非标准残基和长度小于50个氨基酸的蛋白质序列后,保留497个DBP序列的非冗余数据集进行分析。在1848个序列的整个负集合中,在消除了用于训练集的849个序列之后,899个序列被用于独立负集合。然而,为了进行公平的预测,考虑了899个随机选择的500个非DBP序列。简而言之,将500个非DBP序列和497个DBP序列组合起来形成独立的数据集。除AUC-ROC和AUC-PR外,SVM的性能指标略高于其他三种学习技术(表3)。就AUROC和AUC-PR而言,XGB(94.1%;94.8%)和RF(94.0%;94.8%)均优于SVM(93.8%;94.6%)(表3)。所有四个模型的总体精度各不显著other相应的5倍交叉验证精度,表明预测精度既没有出现高估也没有出现低估。
与现有技术比较
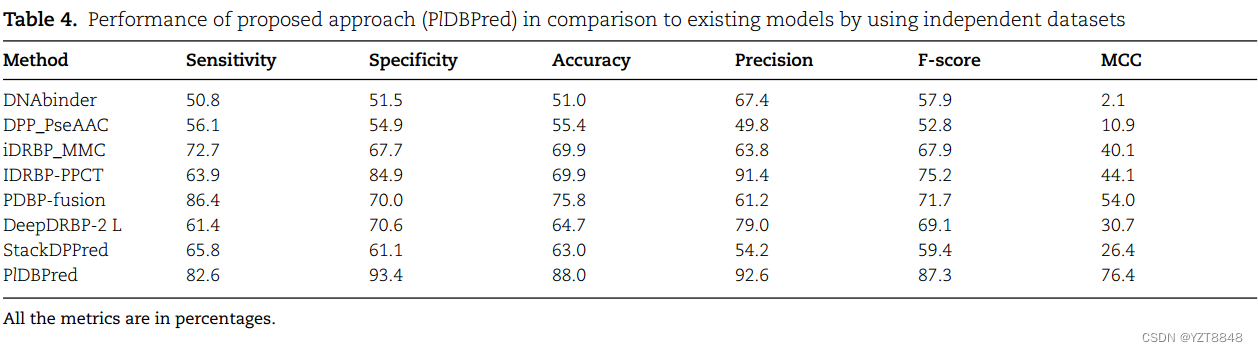
还使用我们的独立测试数据集评估了七种现有技术的DBP预测方法的性能:DNAbinder[13]、DPP-PseAAC[17]、StackDPPred[24]、iDRBP_MMC[26]、iDRBP-PCT[23]、PDBP融合[28]和DeepDRBP-2 L[27],该数据集包括497个DBP和500个非DBP。所有考虑的现有模型都已在拟南芥上进行了评估,并声称在其他植物物种中也能达到类似的性能。性能指标如表4所示。在考虑的七种现有方法中,PDBP融合具有最高的总体准确度(75.8%),而IDRBP-PCT具有最高的准确度(91.4%)和F评分(75.2%)。此外,DNAbinder在准确度方面表现最差(51.0%),DPP-PseAAC在准确度(49.8%)和F-评分(52.8%)方面表现最糟。在这个测试数据集上,我们的方法(用选定特征训练的SVM)比现有模型实现了更高的准确度(88.0%)、准确度(92.6%)、F-评分(87.3%)和MCC(76.4%)(表4)。使用我们模型的完整训练数据集,还评估了现有工具的性能,并发现与测试集的精度相似(补充文件1的补充表2)。
与特定模型相比
Motion等人[51]提出的方法是唯一一种基于植物的DBP预测方法。在这种方法中,通过使用拟南芥的129个DBP和129个非DBP(随机取自1767个非DBPs)进行交叉验证分析。由于分区数据集不可访问,我们使用229个DBP和229个非DBP(随机取自1767个拟南芥的非DBP)进行5倍的交叉验证分析。该实验进一步重复100次,每次使用229个非DBP(1767个非DBPs中)的随机集合以及相同的DBPs集合。所提出的方法(PlDBPred)在准确性方面优于现有方法约4%(表5)。还发现,所提出的方法的MCC比Motion等人[51]开发的方法高出约7%(表5)。在另一种设置中,Motion等人[51]在用拟南芥数据训练模型后,使用其他植物物种的数据集(111个DBP和516个非DBP)作为测试集。按照类似的方法,我们还使用我们训练的模型来预测测试集,并比较准确性。我们观察到PlDBPred的准确性比Motion等人[51]的方法高出约8%(表5)。还发现PlDBPred的MCC远高于现有方法(表5)

讨论
DBPs的预测对未来的蛋白质组学和基因组学研究具有重要的理论和实践意义[3,54]。由于DBP家族数量众多,DNA特征多样,在蛋白质组中鉴定DBP是一项具有挑战性的工作。已经提出了几种寻找DBP的计算方法。然而,他们中的大多数人专注于人类数据,而只有一小部分人专注于拟南芥。到目前为止,只有一种基于SVM的技术,准确率为74.0%[51],植物研究主要忽略了这一领域。
在这项研究中,开发了一种名为PlDBPred的计算工具,该工具使用浅层学习,利用进化特征信息从蛋白质序列中预测植物特异性DBP。在人类数据集上先前的DBP预测中,基于PSSM的进化特征已成功与其他基于序列的特征相结合[13,24]。因此,在当前的研究中,我们考虑了从PSSM矩阵中获得的进化特征。当存在冗余或不相关的特征时,预测准确性会受到影响。因此,我们使用SVM-RFE[55]来确定DBP和非DBP最准确分类的理想特征集。深度学习和浅层学习算法最初都用于预测模型。浅层学习模型的表现优于深度学习模型。因此,只有浅层学习方法用于最终预测分析,该分析使用重复的5倍交叉验证方法进行。SVM的性能略高于其他浅层学习技术(RF、XGB、ADB)。还使用独立的测试数据集评估了所提出的计算方法(具有选定特征的SVM)用于识别植物特定DBP的性能,以确认其稳健性。研究发现,独立数据集的总体准确性与交叉验证的准确性相似。这表明准确性并没有被高估或低估。为了进一步评估所开发模型的可靠性,我们使用独立测试数据集将PlDBPred的性能与其他七种最先进的方法进行了比较。我们发现,我们的方法在准确性方面优于比较模型。用植物测试数据集对现有模型的评估只是为了强调,尽管对人类和小鼠等其他真核生物物种产生了更高的准确性,但现有工具在预测植物特异性DBP方面并不那么有效。已知DBP对每个王国都具有高度特异性,高达47%的DNA结合转录因子属于谱系特异性家族[56]。然而,现有的模型是基于来自广泛的真核生物和原核物种的蛋白质序列开发的,导致了更通用的模型,该模型未能捕捉谱系特异性DNA结合蛋白的变异。换句话说,现有的DBP预测模型无法捕捉植物的谱系特异性蛋白质家族,导致准确性差。除了AADP-PSSM特征描述符外,本研究中使用的其余六个特征描述符(PSSM-DWT、MEDPPSSM、MBMGAC-PSSM、RPSM、SOMA-PSSM和DFMCA-PSSM)都没有在早期的DBP识别模型中进行过探索,这可能是所提出方法具有更高精度的可能原因之一。
此外,将所提出的模型的有效性与Motion等人[51]提出的唯一植物特定DBP预测模型进行了比较。除了测试数据集,我们还使用Motion等人[51]提供的训练数据集来比较我们模型的性能。所提出的模型在训练集和测试集方面都优于Motion等人[51]提出的模型,实现了更高的准确性。DBPred的更高准确性可能归因于方法的改进,因为基于训练数据集发现所提出的模型的准确性更高。
我们使用我们的模型,利用拟南芥(AT)、普通拟南芥(HV)和番茄(SL)的全蛋白质组数据集来预测DBP,以证明对DBP进行可靠的高通量全蛋白质组预测的能力。对于所有三个蛋白质组数据集,发现预测的DBP在DNA结合和相关转录生物学过程中显著富集。此外,细胞成分富集分析显示,相当一部分预测的DBP是在细胞核中发现的。在处理拟南芥、番茄和普通番茄的输入数据集时,共鉴定出87个、28个和7个实验验证的DBP。PlDBPred在拟南芥中准确预测了总共79个(90.80%)实验验证的DBP,在番茄中准确预测24个(85.72%),在普通番茄中全部准确预测7个(100%)。补充文件2包含所有经过实验验证的DBPs。
结论
与当前方法相比,所提出的方法PlDBPred对植物中的DBP提供了高得多的广义预测能力。由于令人鼓舞的结果,PlDBPred可以通过仅利用序列信息有效地用于植物特异性蛋白质的大规模注释。为了定位特定于工厂的DBP,我们开发了一个在线预测工具PlDBPred(https://iasri-sg.icar.gov.in/pldbpred/). 预计所提出的方法将补充现有的识别植物中DBP的模型和实验技术。