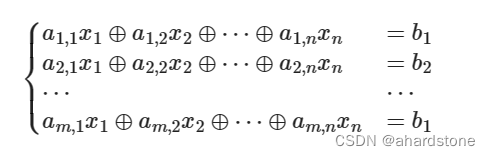索引
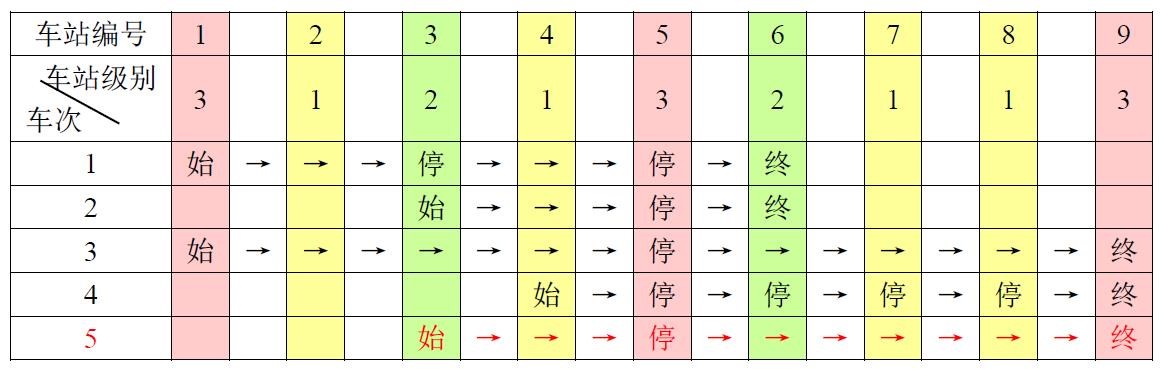
在mysql数据库之中,如果数据量过大,直接进行遍历会需要使用许多时间。这里使用空间换时间解决这一个问题。
目前就是从解决问题的这一个角度出发,需要增加搜索的速度,一定是要选择好用的数据结构进行搜索(遍历的速度越快,时间复杂度越低)。下面从不同的数据结构入手进行分析如应该使用的结构,数组,栈,队列,链表,堆,图就不进行考虑,因为这些的效率低下,和不适合进行搜索的过程。
文章目录
- 索引
- 不同数据结构
- 树
- 哈希表
- 不同种类的索引
- 索引的书写
- 唯一键索引
- 主键索引
- 普通索引
- 全文索引
不同数据结构
树
目前常用的树是有AVL树,红黑树(二叉搜索树),这些树的结构数据量过大之后就会退化成为线性便利(当数据量足够大的情况下),无论怎么进行处理都会变成这个样子。
哈希表
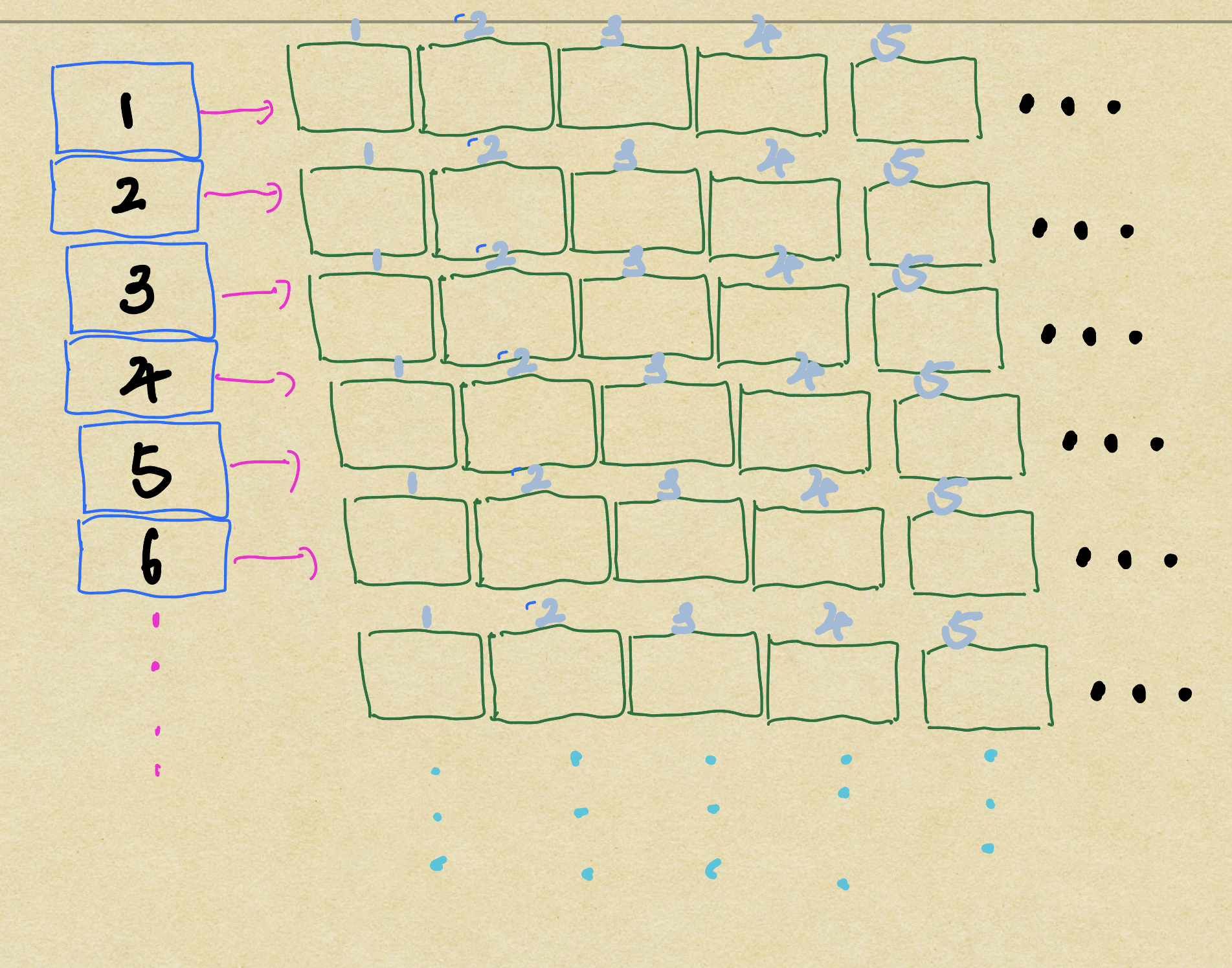
这里使用哈希表方便查找,但是不方便进行访范围进行筛选。不知道,最后一个的东西的范围在哪里,列的大小不确定。目前的使用支持储存引擎。
B+树结构
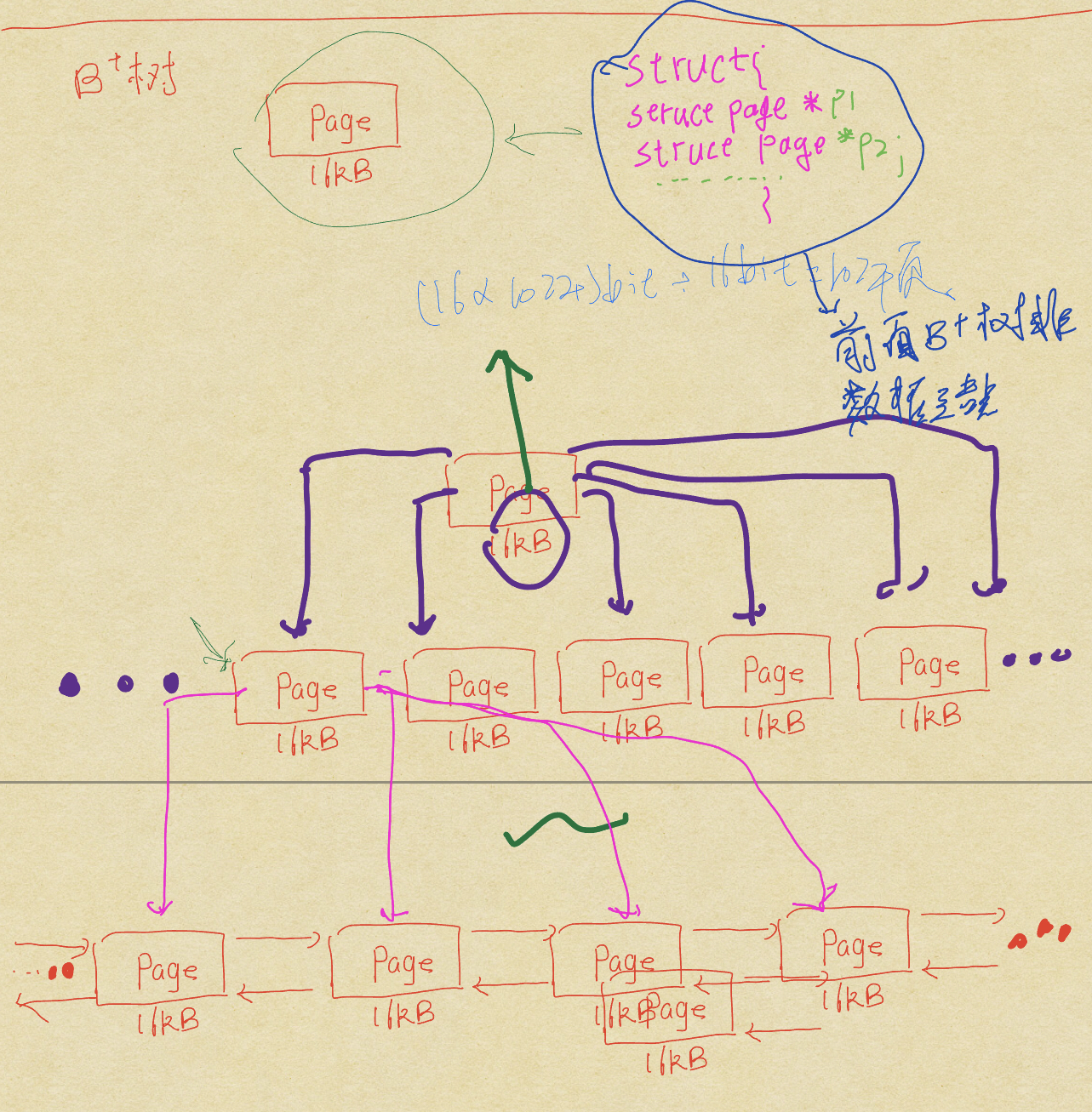
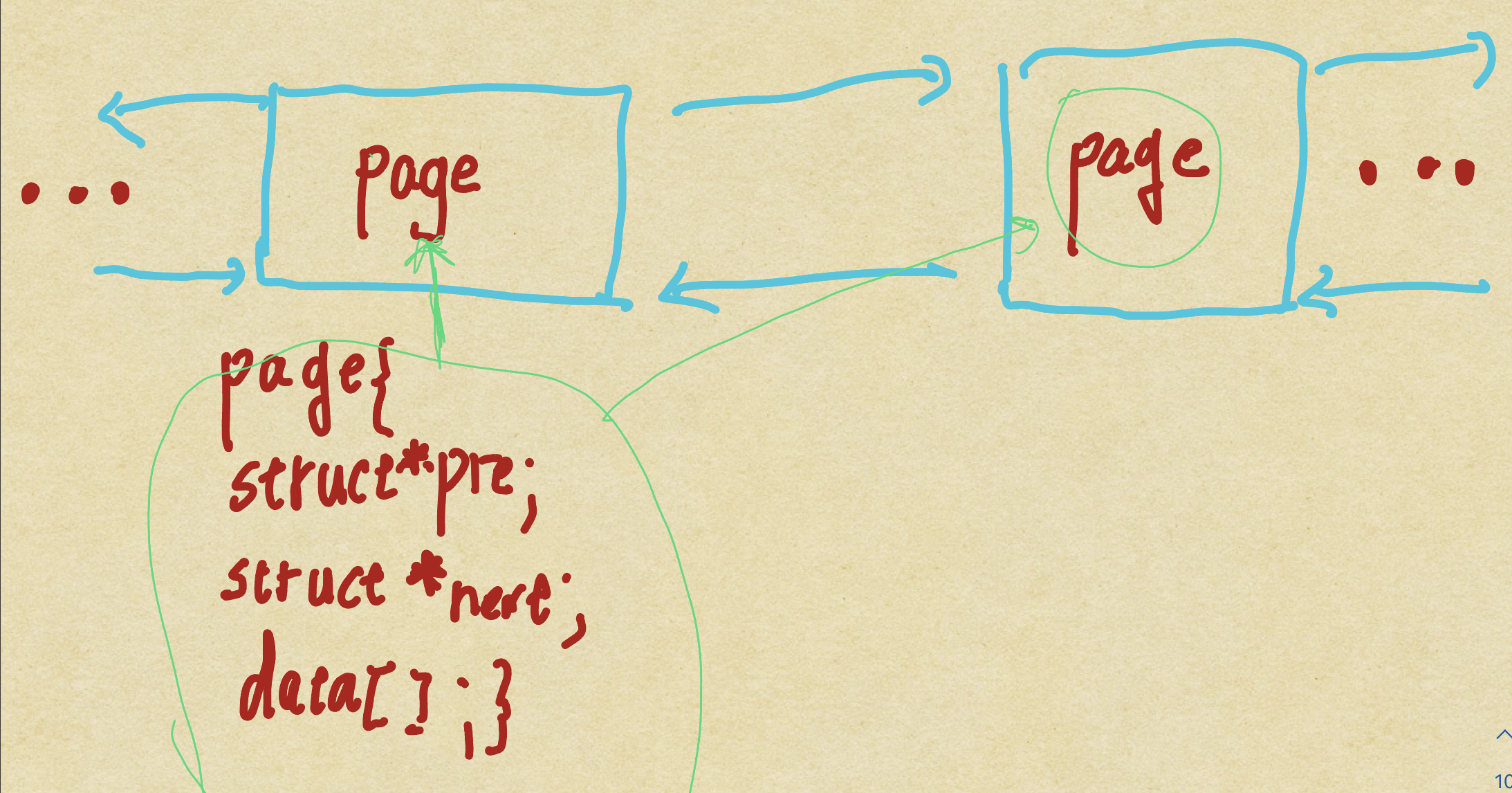
B+树克服了二次树的退化问题(多叉树),而且数据的位置储存在最后一行的位置,让整个的B+树的数据部分不会臃肿(page块,除了最后一行都是用来储下面一次节点的位置信息,)。最后一行储存数据信息的相关内容。
目前经常使用这个方法的MySQL储存引擎。

不同种类的索引
MyISAM 这种用户数据与索引数据分离的索引方案,叫做非聚簇索引。(B+树的结构决定一切,数据放在最底层)。
索引的书写
是否这里根据根主键建立索引,分成下面这两个索引,而去索引的部分的区别。
这里都是一个简单的表进行讲述
create table(
id int primary key,
name varchar(40)
);
这里创建了一个简单表,有用户的id与用户姓名,主键为id。
唯一键索引
一个表中,可以有多个唯一索引
查询效率高
如果在某一列建立唯一索引,必须保证这列不能有重复数据
如果一个唯一索引上指定not null,等价于主键索引(引入不为空的属性,基本上与主键的语法含义相同,但是在实际的应用之中的含义不同)
具体建立的方法如下:()
create table t1(
id int primary key,
name varchar(40) ,
unique(id)
);
这里的unique(id),指定id为唯一键。
create table t1(
id int primary key ,
name varchar(40) unique
);
这里指定name为唯一键,并且同时创建唯一键。
alter table t1 add unqiue(name);
主键索引
1,一个表之中,最大有一个主键索引
2,主键索引的效率高
3,主键索引列基本上是int
4,只要有主键就会生成索引
这里的创建索引的方法与上面的主键索引基本相同,只不过是添加主键。
普通索引
一个表中可以有多个普通索引,普通索引在实际开发中用的比较多。
如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
这里运用普通索引具体过程:
1,创建索引(以普通元素,最后的数据块应该是主键的位置)
2,创建主键索引(即使没有主键,系统自己也是会默认生成一个主键,按照含义叫做与位置无关码)
搜索过程:
1,根据普通的元素索引找到主键值
2,根据主键索引找到对应元素的位置信息
创建普通索引的方法,如下
create table t1(
id int primary key,
name varchar(40) ,
index(name)
);
create table t1(
id int primary key,
name varchar(40) index
);
create index index_name on t1(name)
全文索引
就是整个数据库基本上都是文字(英文,也可以是中文需要换引擎)。这个可以增加搜索的速度。
create fulltext index t1 on t1(name);
这里就创建的t1表的全文索引