源算子

创建环境之后,就可以构建数据的业务处理逻辑了,Flink可以从各种来源获取数据,然后构建DataStream进项转换。一般将数据的输入来源称为数据源(data source),而读取数据的算子就叫做源算子(source operator)。所以,Source就是整个程序的输入端。
Flink中添加source的方式,是调用执行环境的 addSource()方法:
DataStreamSource<String> stringDataStreamSource = env.addSource(...);
DataStreamSource<String> stringDataStreamSource = env.fromSource(...);
参数是一个泛型接口SourceFunction<OUT>,需要实现 SourceFunction 接口;返回 DataStreamSource。这里的
DataStreamSource 类继承自 SingleOutputStreamOperator 类,又进一步继承自 DataStream。所以
很明显,读取数据的 source 操作是一个算子,得到的是一个数据流(DataStream)。
Flink提供了很多种已经实现好的source function,一般情况下我们只需要找到对应的实现类就可以了。
以下介绍5种读取数据的源算子示例。
1. 从集合中读取
最简单的读取数据的方式,就是在代码创建一个集合通过调用执行环境的fromCollection 或者其他方法进行读取。这相当于将数据读取到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试。
1.1 fromCollection
基于集合构建输入数据,集合中的所有元素必须是同一种类型。
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> fromCollection(Collection<OUT> data) | env.fromCollection(list) |
public <OUT> DataStreamSource<OUT> fromCollection(Collection<OUT> data, TypeInformation<OUT> typeInfo) | env.fromCollection(list, BasicTypeInfo.STRING_TYPE_INFO) |
public <OUT> DataStreamSource<OUT> fromCollection(Iterator<OUT> data, Class<OUT> type) | env.fromCollection(new CustomIterator(), String.class) |
public <OUT> DataStreamSource<OUT> fromCollection(Iterator<OUT> data, TypeInformation<OUT> typeInfo) | env.fromCollection(new CustomIterator(), BasicTypeInfo.STRING_TYPE_INFO) |
参数说明:
Collection<OUT> data集合对象,例如List,SetIterator<OUT> data迭代器对象或者自定义迭代器,CustomIteratorClass<OUT> type type集合数据元素类型 ,例如:BasicTypeInfo.STRING_TYPE_INFO.getTypeClass()TypeInformation<OUT> typeInfo集合数据类型对象,例如:BasicTypeInfo.STRING_TYPE_INFO
其中 CustomIterator 为自定义的迭代器,自定义迭代器除了要实现 Iterator 接口外,还必须实现序列化接口 Serializable ,否则会抛出序列化失败的异常,示例代码如下:
public class CustomIterator implements Iterator<Integer>, Serializable {
private int i = 0;
@Override
public boolean hasNext() {
return i < 100;
}
@Override
public Integer next() {
i++;
return i;
}
}
1.2 fromElements
基于元素创建,所有元素必须是同一种类型。
| 方法名 | 示例 |
|---|---|
public final <OUT> DataStreamSource<OUT> fromElements(OUT... data) | env.fromElements("one1", "two2", "three3"); |
public final <OUT> DataStreamSource<OUT> fromElements(Class<OUT> type, OUT... data) | env.fromElements(String.class, "one1", "two2", "three3"); |
参数说明:
OUT... data多参数元素Class<OUT> type元素类型 例如:BasicTypeInfo.STRING_TYPE_INFO.getTypeClass()
1.3 fromSequence
基于给定的序列区间进行构建。
| 方法名 | 示例 |
|---|---|
public DataStreamSource<Long> fromSequence(long from, long to) | env.fromSequence(1, 10); |
| 返回1-10之间的所有数字。 |
1.4 fromParallelCollection
从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> fromParallelCollection(SplittableIterator<OUT> iterator, Class<OUT> type) | env.fromParallelCollection(new NumberSequenceIterator(1, 10), BasicTypeInfo.LONG_TYPE_INFO.getTypeClass()); |
public <OUT> DataStreamSource<OUT> fromParallelCollection(SplittableIterator<OUT> iterator, TypeInformation<OUT> typeInfo) | env.fromParallelCollection(new NumberSequenceIterator(1, 10), BasicTypeInfo.LONG_TYPE_INFO); |
参数说明:
SplittableIterator<OUT> iterator是迭代器的抽象基类,它用于将原始迭代器的值拆分到多个不相交的迭代器中。Class<OUT> type type集合数据元素类型 ,例如:BasicTypeInfo.STRING_TYPE_INFO.getTypeClass()TypeInformation<OUT> typeInfo集合数据类型对象,例如:BasicTypeInfo.STRING_TYPE_INFO
2. 从文件读取数据
真正业务场景中,不会让我们直接把数据写在代码里,通长情况下可能会从存储介质中获取数据,本地文件或者HDFS文件以及OBS存储中等等。
- 参数可以是目录,也可以是文件;
- 路径可以是相对路径,也可以是绝对路径;相对路径是从系统属性 user.dir 获取路径: idea 下是 project 的根目录, standalone 模式下是集群节点根目录;
- 也可以从 hdfs 目录下读取, 使用路径 hdfs://…, 由于 Flink 没有提供 hadoop 相关依赖, 需要 pom 中添加相关依赖:
2.1 readTextFile
按照 TextInputFormat 格式读取文本文件,并将其内容以字符串的形式返回。
| 方法名 | 示例 |
|---|---|
public DataStreamSource<String> readTextFile(String filePath) | env.readTextFile("doc/demo.txt"); |
public DataStreamSource<String> readTextFile(String filePath, String charsetName) | env.readTextFile("doc/demo.txt", "UTF-8"); |
参数说明:
filePath文件路径,可以是绝对路径也可以是相对路径charsetName文件字符串格式,UTF-8或者GBK等
2.2 readFile
根据给定的FileInputFormat读取用户指定的filePath的内容,文本类型的数据通用型方法
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat, String filePath) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt"); |
public <OUT> DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat,String filePath,FileProcessingMode watchType, long interval) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt", FileProcessingMode.PROCESS_ONCE , 10); |
public <OUT> DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat,String filePath, FileProcessingMode watchType,long interval,TypeInformation<OUT> typeInformation) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt", FileProcessingMode.PROCESS_ONCE , 10, BasicTypeInfo.STRING_TYPE_INFO); |
参数说明:
FileInputFormat<OUT> inputFormat数据流的输入格式String filePath文件路径,可以是本地文件系统上的路径,也可以是 HDFS 上的文件路径FileProcessingMode watchType读取方式,它有两个可选值,分别是 FileProcessingMode.PROCESS_ONCE 和 FileProcessingMode.PROCESS_CONTINUOUSLY:前者表示对指定路径上的数据只读取一次,然后退出;后者表示对路径进行定期地扫描和读取。需要注意的是如果 watchType 被设置为 PROCESS_CONTINUOUSLY,那么当文件被修改时,其所有的内容 (包含原有的内容和新增的内容) 都将被重新处理,因此这会打破 Flink 的 exactly-once 语义。long interval定期扫描的时间间隔。TypeInformation<OUT> typeInformation输入流中元素的类型
注意!FileInputFormat是一个抽象类,他的实现类有很多,对应了不同文件类型。
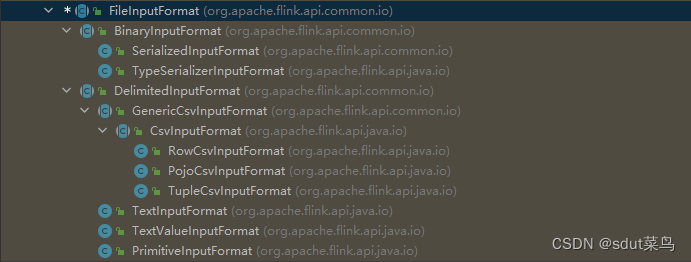
2.3 createInput
使用InputFormat创建输入数据流的通用方法。
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> createInput(InputFormat<OUT, ?> inputFormat) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt"); |
public <OUT> DataStreamSource<OUT> createInput(InputFormat<OUT, ?> inputFormat, TypeInformation<OUT> typeInfo) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt", FileProcessingMode.PROCESS_ONCE , 10); |
参数说明:
InputFormat<OUT, ?> inputFormat接受通用输入格式读取数据
实际上FileInputFormat就继承自InputFormat,所以使用readFile就可以了

3. 从 Socket 读取数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无
界的。Flink 提供了 socketTextStream 方法用于构建基于 Socket 的数据流。
3.1 socketTextStream
| 方法名 | 示例 |
|---|---|
public DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter, long maxRetry) | env.socketTextStream("127.0.0.1", 9999, "\n", 3); |
public DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter) | env.socketTextStream("127.0.0.1", 9999, "\n"); |
public DataStreamSource<String> socketTextStream(String hostname, int port) | env.socketTextStream("127.0.0.1", 9999); |
参数说明:
String hostnameIP地址或者域名地址int port端口号,设置为0表示端口号自动分配String delimiter定界符long maxRetry最大重试次数, 当 Socket 临时关闭时,程序的最大重试间隔,单位为秒。设置为 0 时表示不进行重试;设置为负值则表示一直重试。
创建一个新的数据流,其中包含从套接字无限接收的字符串。接收到的字符串由系统的默认字符集解码,使用“\n”作为分隔符。当套接字关闭时,读取器将立即终止。
4. 从 Kafka 读取数据
一些比较基本的 Source 和 Sink 已经内置在 Flink 里。 预定义 data sources 支持从文件、目录、socket,以及 collections 和 iterators 中读取数据。 预定义 data sinks 支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和 socket。
Flink1.17版本已经集成了非常多的连接器,我这里使用的1.12版本。

Flink 还有些一些额外的连接器通过 Apache Bahir 发布, 包括:

具体详细的连接器信息,可以看官方文档DataStream Connectors
这里主要介绍下使用Flink读取Kafka数据的连接方式
4.1 导入外部依赖
Flink自身是没有Kafka的连接器的,不过Flink提供了Kafka的连接器的依赖包,
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
只需要注意相对应的版本就可以了,我这里用的
<flink.version>1.13.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
然后使用FlinkKafkaConsumer就可以了
4.2 使用FlinkKafkaConsumer开发
在1.17版本,Flink已经推荐使用KafkaSource来构建Kafka的连接器,示例:
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
FlinkKafkaConsumer测试代码示例:
public class GetDataSourceFromKafka {
public static void main(String[] args) throws Exception {
// 1. 直接调用getExecutionEnvironment 方法,底层源码可以自由判断是本地执行环境还是集群的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 从Kafka中读取数据
Properties properties = new Properties();
// 3. 设置Kafka消费者配置参数
properties.setProperty("bootstrap.servers", "hadoop102:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
// 4. 指定监听topic, 并定义Flink和Kafka之间对象的转换规则
DataStreamSource<String> KafkaSource = env.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));
KafkaSource.print("dd");
// 5. 执行程序
env.execute();
}
}
创建FlinkKafkaConsumer对象需要至少三个参数,这三个参数的说明如下:
public FlinkKafkaConsumer(String topic, DeserializationSchema<T> valueDeserializer, Properties props)
- topic:定义了从哪些主题中读取数据。
- valueDeserializer: 是一个 DeserializationSchema 或者 KafkaDeserializationSchema。Kafka 消
息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中
使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数
组简单地反序列化成字符串。DeserializationSchema 和 KafkaDeserializationSchema是
公共接口,所以我们也可以自定义反序列化逻辑。 - props: 是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
FlinkKafkaConsumer有很多的构造方法,对应不同场景,你可以使用一个 topic,也可以是 topic
列表,还可以是匹配所有想要读取的 topic 的正则表达式。
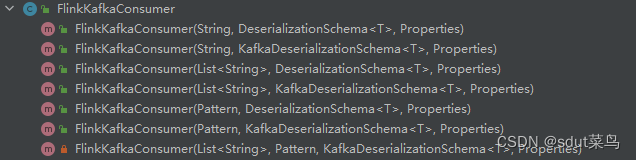
KeyedDeserializationSchema 过期了,所以这里使用的是KafkaDeserializationSchema。当然读取kafka的数据还有更多配置,这里不再详细描写,可以看官网的文档Apache Kafka 连接器
5. 自定义 Source读取数据
除了Flink提供的数据源连接器外,你还可以通过自定义实现 SourceFunction创建数据源连接器,自定义SourceFunction必须要实现重写两个关键方法:run()和 cancel()。
run()方法:使用运行时上下文对象(SourceContext)向下游发送数据。cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
以下是自定义SourceFunction代码实例:
public class CustomSource implements SourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
ctx.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
// 隔 1 秒生成一个点击事件,方便观测
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}
使用方式就是直接通过addSource()调用就可以了
DataStreamSource<Event> customSource = env.addSource(new CustomSource());
注意我们实现的SourceFunction并行度只有1,如果数据源设置大于1的并行度,就会抛出异常
Exception in thread "main" java.lang.IllegalArgumentException: The parallelism
of non parallel operator must be 1.
所以如果我们想要自定义并行的数据源的话,需要使用·ParallelSourceFunction,示例代码如下:
public class CustomSource implements ParallelSourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
ctx.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
// 隔 1 秒生成一个点击事件,方便观测
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}
使用方式就是直接通过addSource()调用就可以了
DataStreamSource<Event> customSource = env.addSource(new CustomSource()).setParallelism(2);